WebServer 1.0 简单实现了一个基础的 多并发网络服务程序 。在该版本中,主要实现了以下重要内容:
- 线程互斥锁 & 条件变量的封装
- 线程池的设计,以支持并发
- 基础网络连接的实现
- http 协议的简略支持
- 支持部分常用 HTTP 报文
- 200 OK
- 400 Bad Request
- 500 Internal Server Error
- 501 Not Implemented
- 505 HTTP Version Not Supported
- 支持 HTTP GET 请求
- 支持 HTTP/1.1 持续连接 特性
- 支持部分常用 HTTP 报文
1.0 版本的项目代码位于 Kiprey/WebServer CommitID: 4095cc - github
最新版本的项目代码位于 Kiprey/WebServer - github
运行示例:
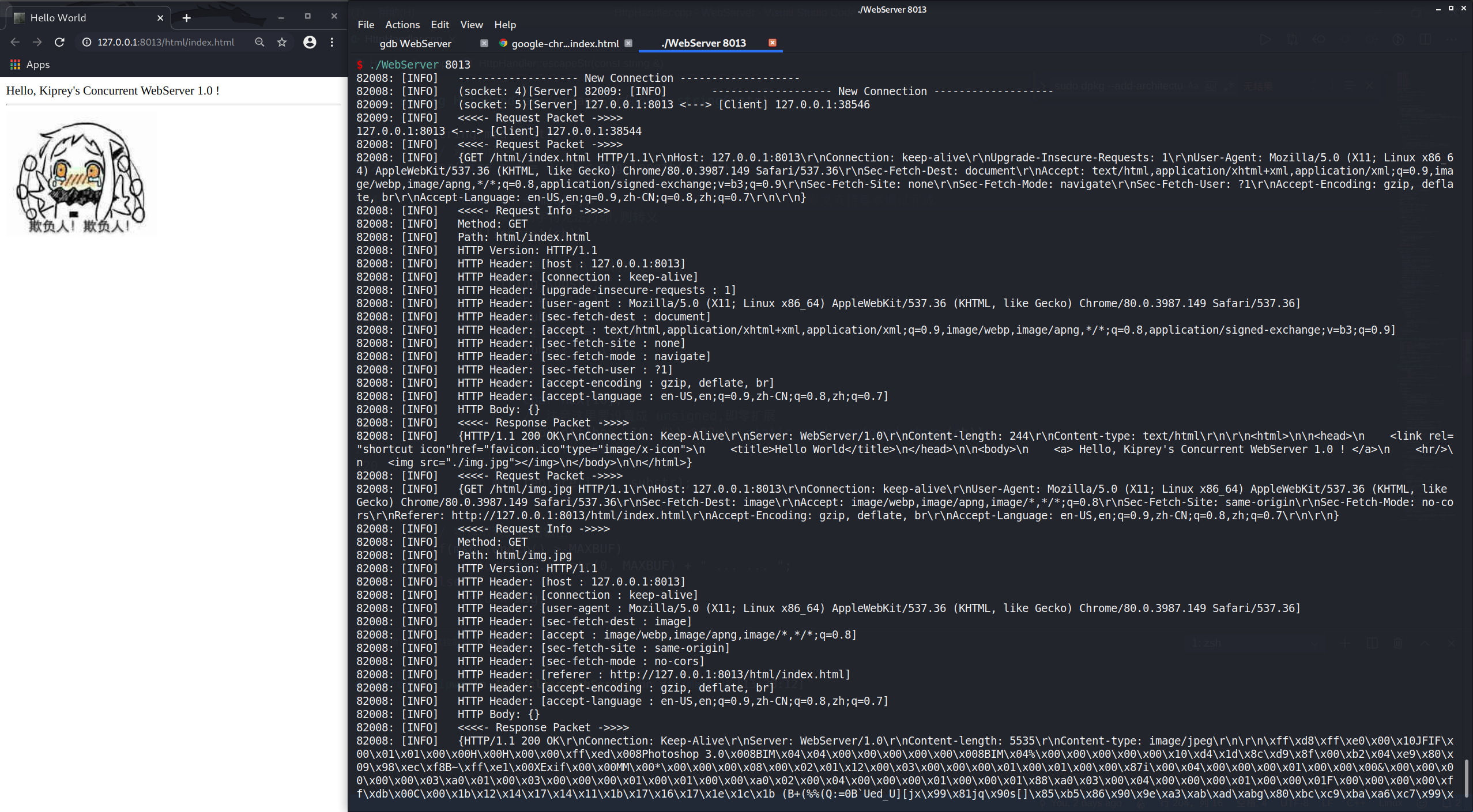
注意:该程序的实现大量参考了 linyacool/WebServer - github 的代码。
对于当前的多线程程序来说,可能会出现多个线程同时读写同一个数据结构的情况,那么此时势必会造成脏读这种错误情况。而互斥锁的使用,是为了保证数据共享操作的完整性,确保任一时刻,只能有一个线程访问目标对象。
在linux中,互斥锁主要使用以下函数来实现:
// 初始化 mutex 对象
pthread_mutex_t mutex = PTHREAD_MUTEX_INITIALIZER;
int pthread_mutex_init(pthread_mutex_t *restrict mutex,
const pthread_mutexattr_t *restrict attr);
// mutex 加锁,在获得锁之前将会阻塞
int pthread_mutex_lock(pthread_mutex_t *mutex);
// mutex 加锁,如果能马上获取锁则返回0,无法获取锁则马上返回errno
int pthread_mutex_trylock(pthread_mutex_t *mutex);
// mutex 释放锁
int pthread_mutex_unlock(pthread_mutex_t *mutex);
// 销毁 mutex 对象
int pthread_mutex_destroy(pthread_mutex_t *mutex);由于 pthread 族的库函数名称较长,并且调用方式也互不相同,因此在这些库函数上做了一个简单的封装:
/**
* @brief MutexLock 将 pthread_mutex 封装成一个类,
* 这样做的好处是不用记住那些繁杂的 pthread 开头的函数使用方式
*/
class MutexLock
{
private:
pthread_mutex_t mutex_;
public:
MutexLock() { pthread_mutex_init(&mutex_, nullptr); }
~MutexLock() { pthread_mutex_destroy(&mutex_); }
void lock() { pthread_mutex_lock(&mutex_); }
void unlock() { pthread_mutex_unlock(&mutex_); }
pthread_mutex_t* getMutex() { return &mutex_; };
};正常来说,我们使用锁时,需要经过以下过程:获取锁->进入临界区->释放锁。但在实际使用锁时,容易忘记释放锁,而这是一个非常严重的错误。因此我们可以实现一个 MutexLockGuard类,借助类的构造函数和析构函数,来帮助我们自动获取锁和释放锁,只需一个简单的声明即可获取锁&释放锁。
/**
* @brief MutexLockGuard 主要是为了自动获取锁/释放锁, 防止意外情况下忘记释放锁
* 而且块状的锁定区域更容易让人理解代码
*/
class MutexLockGuard
{
private:
MutexLock& lock_;
public:
/**
* @brief 声明 MutexLockGuard 时自动上锁
* @param lock 待锁定的资源
*/
MutexLockGuard(MutexLock& mutex) : lock_(mutex) { lock_.lock(); }
/**
* @brief 当前作用域结束时自动释放锁, 防止遗忘
*/
~MutexLockGuard() { lock_.unlock(); }
};一说起条件变量,就不得不说先说起管程。管程保证了同一时刻只有一个线程在管程内活动,但不能保证线程在进入管程后,能继续一次性执行下去直到管程结束。
例如某个线程好不容易进入了管程,但执行了一段时间,突然发现某个条件没有满足,使得当前线程必须阻塞,无法继续执行。但要是该线程原地阻塞,一直占用这个管程,那其他的线程自然就无法进入管程,造成死锁。
那该怎么办呢?这就轮到条件变量出场了。
继续以上面的这个例子为例,由于该线程进入管程后可能会阻塞,因此非常肯定的是,必须在该进程进入阻塞状态前释放管程,否则会造成死锁。但是该线程已经进入管程,且没办法继续执行下去,因此只能原地释放管程,并等待条件满足后,重新获取管程锁,并将该线程唤醒,使其继续执行。
条件变量起到的作用,就相当于控制线程在管程中挂起和唤醒的作用。上面的语句可能有点难以理解,请思考一下这个例子:
线程池中,当子线程需要读取事件队列来获取事件之前,需要先获取队列的锁。当子线程获取到锁以后,如果队列为空,则条件不满足(注意这里的条件是:队列非空),因此子线程就无法从中获取事件,没法继续执行。此时可以使用条件变量让子线程在管程中挂起,等到条件满足时再通过条件变量来唤醒,回到管程继续执行。
注意:使用条件变量时,一定要确保在已经获取到管程锁的前提下使用,否则条件变量容易被多个子线程修改/使用。
条件变量相关的函数如下:
// 初始化条件变量
pthread_cond_t cond = PTHREAD_COND_INITIALIZER;
int pthread_cond_init(pthread_cond_t *restrict cond,
const pthread_condattr_t *restrict attr);
// 唤醒 **至少一个** 被目标条件变量阻塞的线程
int pthread_cond_signal(pthread_cond_t *cond);
// 唤醒 **所有** 被目标条件变量阻塞的线程
int pthread_cond_broadcast(pthread_cond_t *cond);
// 让目标条件变量阻塞当前线程
int pthread_cond_wait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex);
// 让目标条件变量阻塞当前线程,并设置最大阻塞时间
int pthread_cond_timedwait(pthread_cond_t *restrict cond,
pthread_mutex_t *restrict mutex,
const struct timespec *restrict abstime);
// 销毁条件变量
int pthread_cond_destroy(pthread_cond_t *cond);与上面的互斥锁一样,这里也实现了一个 Condition类来简化条件变量的使用:
/**
* @brief 条件变量,主要用于多线程中的锁
* 与 MutexLock 一致,无需记住繁杂的函数名称
* 条件变量主要是与mutex进行搭配,常用于资源分配相关的场景,
* 例如当某个线程获取到锁以后,发现没有资源,则此时可以释放资源并等待条件变量
* @note 注意: 使用条件变量时,必须上锁,防止出现多个线程共同使用条件变量
*/
class Condition
{
private:
MutexLock& lock_; // 目标 Mutex 互斥锁
pthread_cond_t cond_; // 条件变量
public:
Condition(MutexLock& mutex) : lock_(mutex) { pthread_cond_init(&cond_, nullptr); }
~Condition() { pthread_cond_destroy(&cond_); }
void notify() { pthread_cond_signal(&cond_); }
void notifyAll() { pthread_cond_broadcast(&cond_); }
void wait() { pthread_cond_wait(&cond_, lock_.getMutex()); }
/**
* @brief 等待当前的条件变量一段时间
* @param sec 等待的时间(单位:秒)
* @return 成功在时间内等待到则返回 true, 超时则返回 false
*/
bool waitForSeconds(size_t sec)
{
timespec abstime;
// 获取当前系统真实时间
clock_gettime(CLOCK_REALTIME, &abstime);
abstime.tv_sec += (time_t)sec;
return ETIMEDOUT != pthread_cond_timedwait(&cond_, lock_.getMutex(), &abstime);
}
};-
线程池是一种多线程的处理方式,常常用在高并发服务器上。线程池可以有效的利用高并发服务器上的线程资源。
-
线程用于处理各个请求,其流程大致为:创建线程 => 传递信息至子线程 => 线程分离 => 线程运行 => 线程销毁。对于较小规模的通信来说,上述的这个流程可以满足基本需求。但是对于高并发服务器来说,重复的创建线程与销毁线程,其开销不可忽视。因此可以使用线程池来让线程复用。
-
对于一个线程所要执行的任务,我们需要明确以下几点:
- 当前线程所要执行的函数,最好是与主线程没有较大关联的,即尽量降低耦合性。
-
所要执行的事件,可以传入一个参数,但需要明确不能有返回值。
要想有应该也可以做,不过这就是后面的事情了。
因此,我们便可以设计出以下的 task 结构体
// 每个线程的基本事件单元 struct ThreadpoolTask { void (*function)(void*); void* arguments; };
-
线程池除了一些特定的变量(线程个数、事件队列等等)以外,还需要互斥锁以及条件变量。
- 对于每个线程来说,这些线程是有可能同时访问线程池,因此需要在每个线程访问之前加以上锁。
- 上锁之后,对于每个线程来说,有可能出现这种获取到锁,但没有事件可以执行的情况。对于这类情况,子线程必须先释放锁等待事件的到来,等到事件到来之后再重新上锁,获取事件,而这就是条件变量的用处。
由于子线程只会在线程池创建之时创建,在线程池销毁之时销毁,因此,在子线程中必然要执行一个事件循环,其中重复执行 获取事件、执行事件 的动作。
但这里需要注意两件事情,
- 获取事件时,需要给线程池上锁,因为要访问消息队列;必要时刻还需要设置条件变量来暂时释放锁。
- 当线程池被销毁时,子线程该如何终止?
针对问题2,有两种方式:
- 一种是在线程池设置一个标志,子线程定期轮询该标志以确认是否退出。
- 再一种就是当前所实现的:添加一个退出事件至事件队列中,子线程执行到该事件时自动退出。
因此具体实现的代码如下所示:
注意,
pthread_cond_signal会唤醒至少一个线程,注意是至少。因此可能会出现唤醒多个线程但只有一个事件等待处理的情况。针对于这种情况,只需设置子线程在被唤醒后,循环检测是否有剩余事件等待处理即可。
void* ThreadPool::TaskForWorkerThreads_(void* arg)
{
ThreadPool* pool = (ThreadPool*)arg;
// 启动当前线程
ThreadpoolTask task;
// 对于子线程来说,事件循环开始
for(;;)
{
// 首先获取事件
{
// 获取事件时需要上个锁
MutexLockGuard guard(pool->threadpool_mutex_);
/**
* 如果好不容易获得到锁了,但是没有事件可以执行
* 则陷入沉睡,释放锁,并等待唤醒
* NOTE: 注意, pthread_cond_signal 会唤醒至少一个线程
* 也就是说,可能存在被唤醒的线程仍然没有事件处理的情况
* 这时只需循环wait即可.
*/
while(pool->task_queue_.size() == 0)
pool->threadpool_cond_.wait();
// 唤醒后一定有事件
assert(pool->task_queue_.size() != 0);
task = pool->task_queue_.front();
pool->task_queue_.pop();
}
// 执行事件
(task.function)(task.arguments);
}
// 注意: UNREACHABLE, 控制流不可能会到达此处
// 因为线程的退出不会走这条控制流,而是执行退出事件
assert(0 && "TaskForWorkerThreads_ UNREACHABLE!");
return nullptr;
}创建线程池较为简单,直接循环创建线程即可。
需要注意的是,这里设置了销毁线程池时的处理方式。具体信息将在下面销毁线程池的那部分中详细讲解。
ThreadPool::ThreadPool(size_t threadNum, ShutdownMode shutdown_mode, size_t maxQueueSize)
: threadNum_(threadNum),
maxQueueSize_(maxQueueSize),
// 使用 类成员变量 threadpool_mutex_ 来初始化 threadpool_cond_
threadpool_cond_(threadpool_mutex_),
shutdown_mode_(shutdown_mode)
{
// 开始循环创建线程
while(threads_.size() < threadNum_)
{
pthread_t thread;
// 如果线程创建成功,则将其压入栈内存中
if(!pthread_create(&thread, nullptr, TaskForWorkerThreads_, this))
{
threads_.push_back(thread);
// // 注意这里只修改已启动的线程数量
// startedThreadNum_++;
}
}
}添加新事件时,需要设置一下锁,防止脏读。在新事件添加完成后,使用条件变量来唤醒其中某一个空闲线程以执行新事件。
bool ThreadPool::appendTask(void (*function)(void*), void* arguments)
{
// 由于会操作事件队列,因此需要上锁
MutexLockGuard guard(threadpool_mutex_);
// 如果队列长度过长,则将当前task丢弃
if(task_queue_.size() > maxQueueSize_)
return false;
else
{
// 添加task至列表中
ThreadpoolTask task = { function, arguments };
task_queue_.push(task);
// 每当有新事件进入之时,只唤醒一个等待线程
threadpool_cond_.notify();
return true;
}
}销毁线程池时,需要判断销毁的方式。
这里设置了两种销毁方式,分别是
-
IMMEDIATE_SHUTDOWN
-
GRACEFUL_QUIT
对于第一种销毁方式,线程池将马上清空事件队列中的全部事件,并添加与线程个数相对应量的退出事件。这将会使每个子线程在执行完当前事件后,马上执行退出事件以退出。
退出事件如下:每个线程简单执行 pthread_exit 以退出。
auto pthreadExit = [](void*) { pthread_exit(0); };而对于第二种销毁方式来说,只是简单的添加退出事件,没有额外的清空之前的事件。这样线程池只会在所有事件全部结束后才真正的被销毁。
以下是具体的实现代码:
ThreadPool::~ThreadPool()
{
// 向任务队列中添加退出线程事件,注意上锁
// 注意在 cond 使用之前一定要上 mutex
{
// 操作 task_queue_ 时一定要上锁
MutexLockGuard guard(threadpool_mutex_);
// 如果需要立即关闭当前的线程池,则
if(shutdown_mode_ == IMMEDIATE_SHUTDOWN)
// 先将当前队列清空
while(!task_queue_.empty())
task_queue_.pop();
// 往任务队列中添加退出线程任务
for(size_t i = 0; i < threadNum_; i++)
{
auto pthreadExit = [](void*) { pthread_exit(0); };
ThreadpoolTask task = { pthreadExit, nullptr };
task_queue_.push(task);
}
// 唤醒所有线程以执行退出操作
threadpool_cond_.notifyAll();
}
for(size_t i = 0; i < threadNum_; i++)
{
// 回收线程资源
pthread_join(threads_[i], nullptr);
}
}执行一次完整的网络连接通常需要执行数个 socket 类 函数。
为了弄懂这些函数的使用,本人将在下面随着代码的编写,尽量讲解所使用到的函数内容。
注:以下部分主要参考自 Linux/Posix manual page(man指令真是一个好东西 XD)。
-
socket 函数主要用于创建网络交互(communication)中的一个终端(endpoint),即创建一个 socket fd 文件描述符。
-
socket 函数的类型声明如下:
#include <sys/types.h> /* See NOTES */ #include <sys/socket.h> // 执行成功则返回一个新文件描述符fd,失败则返回-1并设置errno int socket(int domain, int type, int protocol);
其中,对于参数 domain,我们主要用到以下两种类型:
- AF_UNIX / AF_LOCAL:本地通信,通常用于进程间通信。其通信不经过网卡,速度远远大于 AF_INET。
- AF_INET: IPv4 协议通信,数据需要经过网卡。
IPv6 和 bluetooth 等类型暂且不表。比较诧异的是,AF_VSOCK用于虚拟机程序与宿主机进行通信。
对于参数 type,常用的主要有以下几种:
-
SOCK_STREAM: TCP 通信
-
SOCK_DGRAM: UDP 通信
-
SOCK_NONBLOCK: 设置非阻塞 socket。使用 or 运算符来附加属性
与设置 O_NONBLOCK 至对应文件描述符操作等同。
-
SOCK_CLOEXEC: 设置若当前程序执行 exec 时,对应文件描述符将在子进程中给关闭。使用 or 运算符来附加属性
与设置 FD_CLOEXEC 至对应文件描述符等同。
参数 protocol 通常用于指定某一个特定的套接字协议。如果给定协议系列只有一个协议可以支持特定的套接字类型,则 protocol 可以指定为0。但是若给定协议系列中可能存在多个可以支持套接字的类型,这时候就必须设置 protocol 以指定具体类型。
-
简单举例:创建一个 IPv4 的 TCP 套接字(最常用)
int listen_fd = socket(AF_INET, SOCK_STREAM, 0);
-
对于一个新创建的 socket(注意是新创建的),还没有任何的地址用于赋给该 socket。而 bind 函数就是用于赋以一个地址给该 socket。
需要注意的是:如果当前 socket 在执行 bind 前已经被使用,则操作系统将会自动分配地址以及端口号等等,这也是为什么一些网络程序向外通信时使用的端口号是随机的,因为操作系统会在后面调控。
-
bind 函数的声明如下:
#include <sys/types.h> /* See NOTES */ #include <sys/socket.h> // 执行成功则返回0,失败则返回-1并设置errno int bind(int sockfd, const struct sockaddr *addr, socklen_t addrlen);
-
其中,第一个参数sockfd 用以传入目标 socket 文件描述符
-
至于第二个参数addr,其中使用的规则与结构体,在地址族之间有所不同。
-
第三个参数addrlen用于表示第二个参数addr所指向结构体的size。
对于 AF_INET:所使用到的 address format 如下
#include <netinet/in.h> // ! 注意头文件!! struct sockaddr_in { sa_family_t sin_family; /* address family: AF_INET */ in_port_t sin_port; /* port in network byte order */ struct in_addr sin_addr; /* internet address */ }; /* Internet address. */ struct in_addr { uint32_t s_addr; /* address in network byte order */ };
其中,sin_family 始终为 AF_INET;sin_port 设置为目标端口;sin_addr用以保存监听目标的地址。
这里多提一句,由于现代计算机可能有多张网卡,因此指定 sin_addr 可以使得只监听特定网卡的连接。如果想监听全部网卡的连接,则可以使用宏定义 INADDR_ANY(实际上就是 0.0.0.0)。
/* Address to accept any incoming messages. */ #define INADDR_ANY ((in_addr_t) 0x00000000)
而如果绑定 127.0.0.1 回环地址,则只能监听到主动发送至回环地址的请求,其他发送到当前该机器但目标IP非回环地址的请求则不会被处理。
注意:sin_port、sin_addr 变量都必须以网络端序来保存数据(即大端序)。
socket提供了端序转换的一些函数,便于转换(其中,h表示host,n表示network)。
/* Functions to convert between host and network byte order. Please note that these functions normally take `unsigned long int' or `unsigned short int' values as arguments and also return them. But this was a short-sighted decision since on different systems the types may have different representations but the values are always the same. */ extern uint32_t ntohl (uint32_t __netlong) __THROW __attribute__ ((__const__)); extern uint16_t ntohs (uint16_t __netshort) __THROW __attribute__ ((__const__)); extern uint32_t htonl (uint32_t __hostlong) __THROW __attribute__ ((__const__)); extern uint16_t htons (uint16_t __hostshort) __THROW __attribute__ ((__const__));
-
如果需要网络端序IP地址<--->字符串类型转变,则请参照以下函数:
#include <sys/socket.h> #include <netinet/in.h> #include <arpa/inet.h> int inet_aton(const char *cp, struct in_addr *inp); in_addr_t inet_addr(const char *cp); in_addr_t inet_network(const char *cp); char *inet_ntoa(struct in_addr in); struct in_addr inet_makeaddr(in_addr_t net, in_addr_t host); in_addr_t inet_lnaof(struct in_addr in); in_addr_t inet_netof(struct in_addr in);
对于一个 AF_NET 地址族来说,执行 bind 的一个简单例子如下:
// 绑定端口
sockaddr_in server_addr;
// 初始化一下
memset(&server_addr, '\0', sizeof(server_addr));
// 设置一下基本操作
server_addr.sin_family = AF_INET;
server_addr.sin_port = htonl((unsigned short)port);
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
// 试着bind
if(bind(listen_fd, (sockaddr*)&server_addr, sizeof(server_addr)) == -1)
return -1;listen 函数将会使得传入的 socket fd 变为等待连接状态。该函数原型如下:
#include <sys/types.h> /* See NOTES */
#include <sys/socket.h>
// 成功则返回0,失败则返回-1并设置 errno
int listen(int sockfd, int backlog);该函数主要有两个参数:参数 sockfd 传入目标 fd;backlog 指定最大挂起连接的等待队列长度,如果队列满了,则新连接将会被拒绝(ECONNREFUSED)。而对于某些特殊协议,将会在一段时间后重新发起连接。
-
accept 函数将会取出 listen_fd的挂起连接等待队列 中的第一个连接,创建一个新的 socket fd(client fd),并将其返回。后续与该连接的交互都是通过该client fd 完成。
-
需要注意的是, accept 会从 listen_fd 中取出挂起的连接,并尝试连接。一旦完成连接后,将会创建一个新的 client_fd。原先的 listen_fd 不会有任何改变。
-
如果当前 listen_fd 为阻塞式的,则如果当前挂起连接等待队列中不存在任何连接,那么执行 accept 时将阻塞,直到有新连接的到来。
-
该函数的原型如下:
#include <sys/types.h> /* See NOTES */ #include <sys/socket.h> int accept(int sockfd, struct sockaddr *addr, socklen_t *addrlen);
- 第一个参数为传入的监听socket listen_fd
- 第二个参数为指向 sockaddr 结构体的 一个指针,accept 函数将会把 远程 socket 的address写入目标结构体中
- 第三个参数是一个存放 sockaddr 结构体大小的指针。
由于 read/recv & write/send 操作涉及到阻塞与非阻塞式读写,因此我们需要额外对其做一些异常处理。
需要注意的是,socket读写中,除了使用read/write以外,还可以使用专用于套接字通信的send/recv函数族等等。
该类函数中最常返回的错误为 EINTR 以及 EAGAIN,其他错误暂时忽略。其中:
-
EINTR:该错误常见于阻塞式的操作,提示当前操作被中断。
如果一个进程在一个慢系统调用中阻塞时,捕获到信号并执行完信号处理例程返回时,这个系统调用将不再被阻塞,而是被中断,返回 EINTR。
对于读写函数来说,当返回这类错误时,最常用的做法就是重新执行目标函数。
-
EAGAIN:该错误常见于非阻塞式的操作,提示用户稍后再重新执行。
例如:
- 当以非阻塞方式大量发送数据时,如果缓冲区爆满,则产生 Resource temporarily unavailable的错误(资源暂时不可用),并返回 EAGAIN。
- 当以非阻塞模式下读取数据,如果多次读取数据但没有数据可读,则此时不会阻塞等待数据,而是直接返回 EAGAIN
对于 read 函数来说,由于数据取决于远程,因此当接收到 EAGAIN 时终止读取,直接返回;
但对于 write 函数来说,由于数据取决于当前服务器,因此可以继续循环写入,直至数据完全写入。
对于 recv/send 函数来说,与 read/write 相比,将会额外多出部分专用于 socket 的错误码,例如 ECONNREFUSED、EPIPE 以及 ECONNRESET 等等。出于调试目的,在实现 读写函数的 wrapper时,将这两类读写函数全部集成在 wrapper中,并用一个bool参数来控制启用 read/write 还是 recv/send 函数。
对于读取操作来说,阻塞读取和非阻塞读取又有所不同:
- 当有数据到来时,阻塞和非阻塞的实现相同,都是读取数据并立即返回。
- 但是当没有数据到来时,由于非阻塞读取时会返回 EAGAIN 错误,因此可以立即返回;而阻塞读取此时就必须阻塞,直到数据到来才返回。
在具体实现 读取操作的wrapper函数时,同样使用一个bool参数来控制是否是阻塞/非阻塞读取。
read/recv & write/send 函数的返回值
- 若为负数则说明存在错误
- 若为0则说明连接中断
- 若为正数则该数为成功读取/发送的字节数
综上所述,read/recv 函数重新实现的 wrapper 如下:
ssize_t readn(int fd, void*buf, size_t len, bool isBlock, bool isRead)
{
// 这里将 void* 转换成 char* 是为了在下面进行自增操作
char *pos = (char*)buf;
size_t leftNum = len;
ssize_t readNum = 0;
while(leftNum > 0)
{
ssize_t tmpRead = 0;
// 尝试循环读取,如果报错,则进行判断
// 注意, read 的返回值为0则表示读取到 EOF,是正常现象
if(isRead)
tmpRead = read(fd, pos, leftNum);
else
tmpRead = recv(fd, pos, leftNum, (isBlock ? 0 : MSG_DONTWAIT));
if(tmpRead < 0)
{
if(errno == EINTR)
tmpRead = 0;
// 如果始终读取不到数据,则提前返回,因为这个取决于远程 fd,无法预测要等多久
else if (errno == EAGAIN)
return readNum;
else
return -1;
}
// 读取的0,则说明远程连接已被关闭
if(tmpRead == 0)
break;
readNum += tmpRead;
pos += tmpRead;
// 如果是阻塞模式下,并且读取到的数据较小,则说明数据已经全部读取完成,直接返回
if(isBlock && static_cast<size_t>(tmpRead) < leftNum)
break;
leftNum -= tmpRead;
}
return readNum;
}write/send 函数的 wrapper 同理:
ssize_t writen(int fd, void*buf, size_t len, bool isWrite)
{
// 这里将 void* 转换成 char* 是为了在下面进行自增操作
char *pos = (char*)buf;
size_t leftNum = len;
ssize_t writtenNum = 0;
while(leftNum > 0)
{
ssize_t tmpWrite = 0;
if(isWrite)
tmpWrite = write(fd, pos, leftNum);
else
tmpWrite = send(fd, pos, leftNum, 0);
// 尝试循环写入,如果报错,则进行判断
if(tmpWrite < 0)
{
// 与read不同的是,如果 EAGAIN,则继续重复写入,因为写入操作是有Server这边决定的
if(errno == EINTR || errno == EAGAIN)
tmpWrite = 0;
else
return -1;
}
if(tmpWrite == 0)
break;
writtenNum += tmpWrite;
pos += tmpWrite;
leftNum -= tmpWrite;
}
return writtenNum;
}综上各类函数的分析,现在我们可以为服务器端开启一个监听套接字,并等待客户端连接:
int socket_bind_and_listen(int port)
{
int listen_fd = 0;
// 开始创建 socket, 注意这是阻塞模式的socket
// AF_INET : IPv4 Internet protocols
// SOCK_STREAM : TCP socket
if((listen_fd = socket(AF_INET, SOCK_STREAM, 0)) == -1)
return -1;
// 绑定端口
sockaddr_in server_addr;
// 初始化一下
memset(&server_addr, '\0', sizeof(server_addr));
// 设置一下基本操作
server_addr.sin_family = AF_INET;
server_addr.sin_port = htons((unsigned short)port);
server_addr.sin_addr.s_addr = htonl(INADDR_ANY);
// 端口复用
int opt = 1;
if(setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)) == -1)
return -1;
// 试着bind
if(bind(listen_fd, (sockaddr*)&server_addr, sizeof(server_addr)) == -1)
return -1;
// 试着listen, 设置最大队列长度为 1024
if(listen(listen_fd, 1024) == -1)
return -1;
return listen_fd;
}注意到这部分代码,设置端口复用属性:
// 端口复用
int opt = 1;
if(setsockopt(listen_fd, SOL_SOCKET, SO_REUSEADDR, &opt, sizeof(opt)) == -1)
return -1;正常来说,对于某个网络程序,一个端口只能绑定一个套接字,别的套接字无法使用这个端口。而如果需要让同一程序的不同套接字绑定统一端口,则需要设置端口复用属性。
不过在当前WebServer-1.0版本中,设置端口复用貌似是不必要的,就算删除也无伤大雅。
SIGPIPE 信号将在远程连接被中断时发出。默认的处理例程是终止程序,而这很明显不是我们所期望的处理方式。因此我们必须设置 WebServer 忽视 SIGPIPE 信号,以免被意外终止。
void handleSigpipe()
{
struct sigaction sa;
memset(&sa, '\0', sizeof(sa));
sa.sa_handler = SIG_IGN;
sa.sa_flags = 0;
if(sigaction(SIGPIPE, &sa, NULL) == -1)
LOG(ERROR) << "Ignore SIGPIPE failed! " << strerror(errno) << std::endl;
}WebServer-1.0版本中实现的输出功能较为简单,只将信息输出到终端的stdout、stderr,没有建立日志文件。
具体实现如下:
/**
* @brief 输出信息相关宏定义与函数
* 使用 `LOG(INFO) << "msg";` 形式以执行信息输出.
* @note 注意: 该宏功能尚未完备,多线程下使用LOG宏将会导致输出数据混杂
*/
#define INFO 1 /* 普通输出 */
#define ERROR 2 /* 错误输出 */
#define LOG(x) logmsg(x) /* 调用输出函数 */
std::ostream& logmsg(int flag)
{
// 输出信息时,设置线程互斥
// 获取线程 TID
long tid = syscall(SYS_gettid);
if(flag == ERROR)
{
std::cerr << tid << ": [ERROR]\t";
return std::cerr;
}
else if(flag == INFO)
{
std::cout << tid << ": [INFO]\t";
return std::cout;
}
else
{
logmsg(ERROR) << "错误的 LOG 选择" << std::endl;
abort();
}
}如果有信息需要输出到终端,则按照以下调用方式使用即可,简单方便:
LOG(INFO) << "my msg" << std::endl;输出信息时,会自动将当前子线程的 LWP 号以及信息类型(INFO/ERROR)输出,例如:
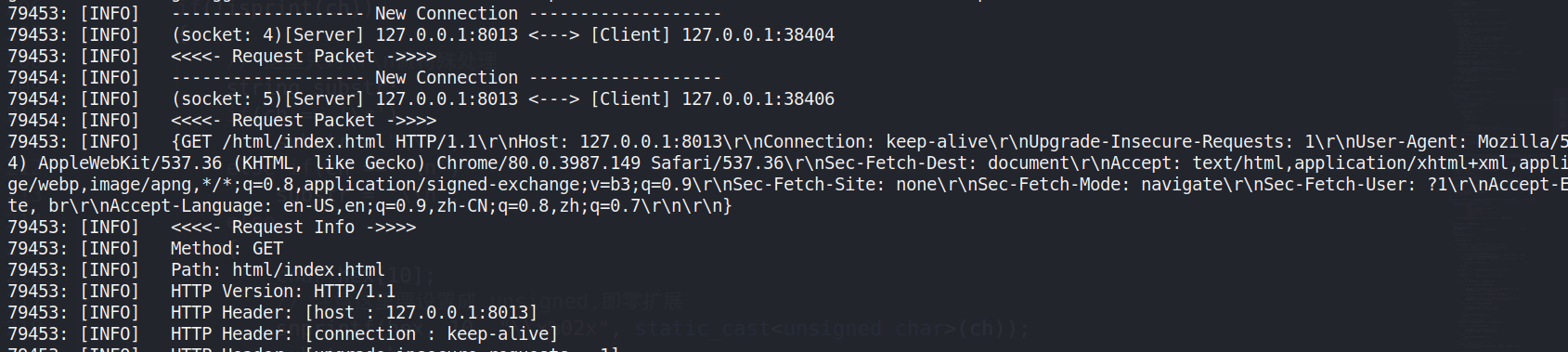
需要注意的是,该输出功能没有设置多线程互斥,因此可能会造成输出格式异常,即多个线程同时使用LOG功能,输出的数据在终端上揉成一团,显示的不太雅观。
当 Server 成功与 Client 建立连接后,Client 将会发送数据至 Server,此时 Server 就需要解析数据并进一步将目标数据传送回 Client。其中,http报文的解析和http header的处理便是重点。
当建立起一个新的客户端套接字(client_fd)后,目标事件将被放进事件队列中,并等待空闲线程处理。
而这里的事件便是以下函数:
void handlerConnect(void* arg)
{
int* fd_ptr = (int*)arg;
int client_fd = *fd_ptr;
delete fd_ptr;
if(client_fd < 0)
{
LOG(ERROR) << "client_fd error in handlerConnect" << endl;
return;
}
HttpHandler handler(client_fd);
handler.RunEventLoop();
close(client_fd);
}我们可以很容易的看到,该函数只做了几件事情:
- 取出 client_fd
- 初始化 HttpHandler 类实例
- 调用
HttpHandler::RunEventLoop函数 - 最终释放 client_fd
这里的 HttpHandler 类,就是下文中的重点。
HttpHandler 支持部分 HTTP/1.1 版本的特性——持续连接。默认情况下,执行其 RunEventLoop 成员函数时,将循环读取来自客户端的请求,处理并返回对应的响应报文。
HttpHandler 的整体代码结构如下所示,主要是由多个成员函数以及少数几个成员变量组成。RunEventLoop 函数是启动整个处理请求循环的一个开关函数:
/**
* @brief HttpHandler 类处理每一个客户端连接,并根据读入的http报文,动态返回对应的response
* 其支持的 HTTP 版本为 HTTP/1.1
* @note 该类只实现了部分异常处理,没有涵盖大部分的异常(不过暂时也够了)
*/
class HttpHandler
{
public:
/**
* @brief HttpHandler内部状态
*/
enum ERROR_TYPE {
ERR_SUCCESS = 0, // 无错误
ERR_READ_REQUEST_FAIL, // 读取请求数据失败
ERR_NOT_IMPLEMENTED, // 不支持一些特定的请求操作,例如 Post
ERR_HTTP_VERSION_NOT_SUPPORTED, // 不支持当前客户端的http版本
ERR_INTERNAL_SERVER_ERR, // 程序内部错误
ERR_CONNECTION_CLOSED, // 远程连接已关闭
ERR_BAD_REQUEST, // 用户的请求包中存在错误,无法解析
ERR_SEND_RESPONSE_FAIL // 响应包发送失败
};
/**
* @brief 显式指定 client fd
* @param fd 连接的 fd, 初始值为 -1
*/
explicit HttpHandler(int fd = -1);
/**
* @brief 释放所有 HttpHandler 所使用的资源
* @note 注意,不会主动关闭 client_fd
*/
~HttpHandler();
/**
* @brief 为当前连接启动事件循环
* @note 1. 在执行事件循环开始之前,一定要设置 client fd
* 2. 异常处理不完备
*/
void RunEventLoop();
// 只有getFd,没有setFd,因为Fd必须在创造该实例时被设置
int getClientFd() { return client_fd_; }
private:
const size_t MAXBUF = 1024;
int client_fd_;
// http 请求包的所有数据
string request_;
// http 头部
unordered_map<string, string> headers_;
// 请求方式
string method_;
// 请求路径
string path_;
// http版本号
string http_version_;
// 是否是 `持续连接`
// NOTE: 为了防止bug的产生,对于每一个类中的isKeepAlive_来说,
// 值只能从 true -> false,而不能再次从 false -> true
bool isKeepAlive_;
// 当前解析读入数据的位置
/**
* NOTE: 该成员变量只在
* readRequest -> parseURI -> parseHttpHeader -> RunEventLoop
* 内部中使用
*/
size_t pos_;
/**
* @brief 将当前client_fd_对应的连接信息,以 LOG(INFO) 的形式输出
*/
void printConnectionStatus();
/**
* @brief 从client_fd_中读取数据至 request_中
* @return 0 表示读取成功, 其他则表示读取过程存在错误
* @note 内部函数recvn在错误时会产生 errno
*/
ERROR_TYPE readRequest();
/**
* @brief 从0位置处解析 请求方式\URI\HTTP版本等
* @return 0 表示成功解析, 其他则表示解析过程存在错误
*/
ERROR_TYPE parseURI();
/**
* @brief 从request_中的pos位置开始解析 http header
* @return 0 表示成功解析, 其他则表示解析过程存在错误
*/
ERROR_TYPE parseHttpHeader();
/**
* @brief 发送响应报文给客户端
* @param responseCode http 状态码, http报文第二个字段
* @param responseMsg http 报文第三个字段
* @param responseBodyType 返回的body类型,即 Content-type
* @param responseBody 返回的body内容
* @return 0 表示成功发送, 其他则表示发送过程存在错误
*/
ERROR_TYPE sendResponse(const string& responseCode, const string& responseMsg,
const string& responseBodyType, const string& responseBody);
/**
* @brief 发送错误信息至客户端
* @param errCode 错误http状态码
* @param errMsg 错误信息, http报文第三个字段
* @return 0 表示成功发送, 其他则表示发送过程存在错误
*/
ERROR_TYPE handleError(const string& errCode, const string& errMsg);
/**
* @brief 将传入的字符串转义成终端可以直接显示的输出
* @param str 待输出的字符串
* @return 转义后的字符串
* @note 是将 '\r' 等无法在终端上显示的字符,转义成 "\r"字符串 输出
*/
string escapeStr (const string& str);
};HttpHandler 中实现了以下错误类型:
/**
* @brief HttpHandler内部状态
*/
enum ERROR_TYPE {
ERR_SUCCESS = 0, // 无错误
ERR_READ_REQUEST_FAIL, // 读取请求数据失败
ERR_NOT_IMPLEMENTED, // 不支持一些特定的请求操作,例如 Post
ERR_HTTP_VERSION_NOT_SUPPORTED, // 不支持当前客户端的http版本
ERR_INTERNAL_SERVER_ERR, // 程序内部错误
ERR_CONNECTION_CLOSED, // 远程连接已关闭
ERR_BAD_REQUEST, // 用户的请求包中存在错误,无法解析
ERR_SEND_RESPONSE_FAIL // 响应包发送失败
};除了第一种 ERR_SUCCESS 表示无错误以外,其余的错误类型都有对应的错误处理方式,例如终止连接或者向客户端发送一个特定的响应报文,我们将在下面的内容中提到这些错误处理方式。
当远程客户端发送数据至服务器端时,无论传来的是什么数据,首先要做的就是将数据从缓存中读取并保存至自己的缓冲区内。读取时需要明确一点:使用阻塞方式读取。因为每个客户端连接都是由单独的线程进行处理的,倘若服务器端没有将所有的请求数据全部读完,那么自然就无法继续执行下去。
同时还需要明确一点的是,调用 readn 函数读取数据时,有可能客户端传来的数据较多,使得读取到的字节数刚好等于传入 readn 的最大缓冲区大小,那么此时就必须保存并继续循环读取,因为这里可能还有一部分数据没有读取完成,仍然需要继续读取。只有当 readn 函数返回的值小于传入的最大缓冲区大小,才能说明来自客户端的数据已经全部读取完成。此时就可以退出读取请求函数。
最后,readn 函数可能会因为出错、远程连接中断等意外情况返回负数,因此这里需要额外写一点错误处理,返回对应原因的错误枚举 ERR_READ_REQUEST_FAIL 或者 ERR_CONNECTION_CLOSED 等等。
综上所述,最终实现的代码如下所示:
HttpHandler::ERROR_TYPE HttpHandler::readRequest()
{
// 清除之前的数据
request_.clear();
pos_ = 0;
char buffer[MAXBUF];
// 循环阻塞读取 ------------------------------------------
for(;;)
{
ssize_t len = readn(client_fd_, buffer, MAXBUF, true, true);
if(len < 0)
return ERR_READ_REQUEST_FAIL;
/**
* 如果此时没读取到信息并且之前已经读取过信息了,则直接返回.
* 这里需要注意,有些连接可能会提前连接过来,但是不会马上发送数据.因此需要阻塞等待
* 这里有个坑点: chromium在每次刷新过后,会额外开一个连接,用来缩短下次发送请求的时间
* 也就是说这里大概率会出现空连接,即连接到了,但是不会马上发送数据,而是等下一次的请求.
*
* 如果读取到的字节数为0,则说明远程连接已经被关闭.
*/
else if(len == 0)
{
// 对于已经读取完所有数据的这种情况
if(request_.length() > 0)
// 直接停止读取
break;
// 如果此时既没读取到数据,之前的 request_也为空,则表示远程连接已经被关闭
else
return ERR_CONNECTION_CLOSED;
}
// 将读取到的数据组装起来
string request(buffer, buffer + len);
request_ += request;
// 由于当前的读取方式为阻塞读取,因此如果读取到的数据已经全部读取完成,则直接返回
if(static_cast<size_t>(len) < MAXBUF)
break;
}
return ERR_SUCCESS;
}接下来是 HTTP 请求报文的解析,我们先简单看看 请求报文的格式:
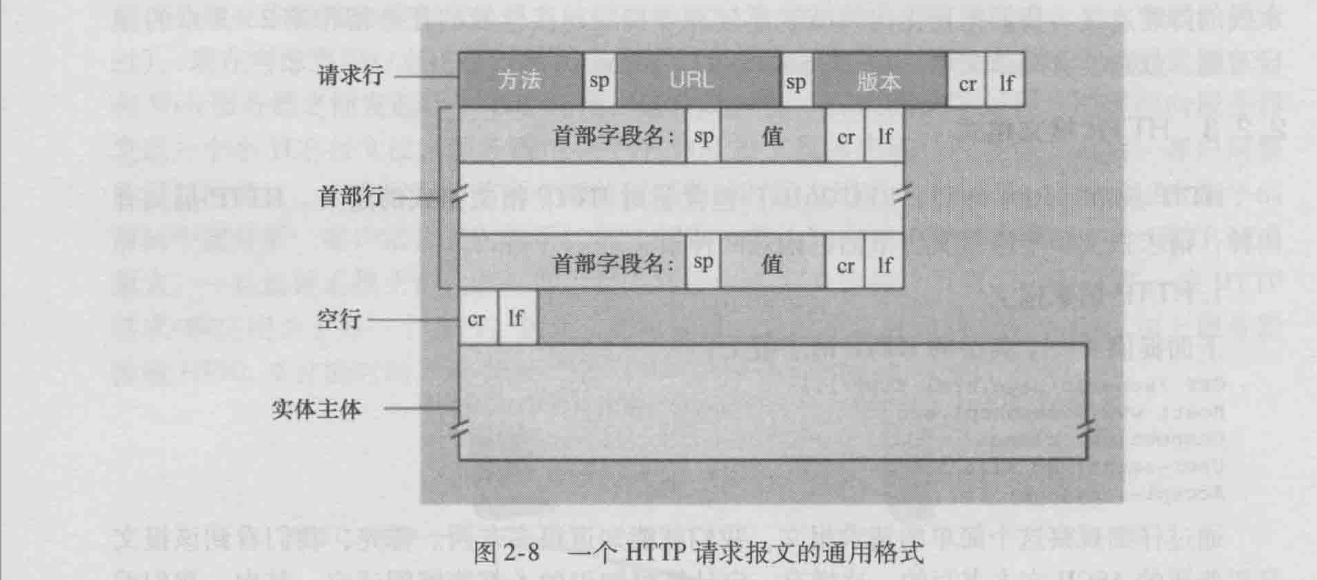
首先,我们需要从报文中获取第一个以 \r\n结尾的行,并从这行中解析出请求方法、目标URL以及HTTP版本。任何一种因为错误报文格式所导致的解析失败,都是 ERR_BAD_REQUEST 错误。
其次,目前 WebServer-1.0 版本只支持 GET 的请求方法,倘若识别到其他请求方法都会返回 ERR_NOT_IMPLEMENTED 错误。
由于请求 URL 可能是一个文件夹地址,而不是文件。因此如果URL指向的是一个文件夹,那么我们就必须在这个URL地址后添加/index.html字符串,使得请求的目标地址一定是一个文件(即便该文件可能不存在)。
最后,目前的 WebServer-1.0版本只支持 HTTP/1.0 和 HTTP/1.1 版本,因此如果识别到了其他的 HTTP版本,则马上返回 ERR_HTTP_VERSION_NOT_SUPPORTED 错误。
综上所述,最后实现的代码如下所示:
HttpHandler::ERROR_TYPE HttpHandler::parseURI()
{
if(request_.empty()) return ERR_BAD_REQUEST;
size_t pos1, pos2;
pos1 = request_.find("\r\n");
if(pos1 == string::npos) return ERR_BAD_REQUEST;
string&& first_line = request_.substr(0, pos1);
// a. 查找get
pos1 = first_line.find(' ');
if(pos1 == string::npos) return ERR_BAD_REQUEST;
method_ = first_line.substr(0, pos1);
string output_method = "Method: ";
if(method_ == "GET")
output_method += "GET";
else
return ERR_NOT_IMPLEMENTED;
LOG(INFO) << output_method << endl;
// b. 查找目标路径
pos1++;
pos2 = first_line.find(' ', pos1);
if(pos2 == string::npos) return ERR_BAD_REQUEST;
// 获取path时,注意去除 path 中的第一个斜杠
pos1++;
path_ = first_line.substr(pos1, pos2 - pos1);
// 如果 path 为空,则添加一个 . 表示当前文件夹
if(path_.length() == 0)
path_ += ".";
// 判断目标路径是否是文件夹
struct stat st;
if(stat(path_.c_str(), &st) == 0)
{
// 如果试图打开一个文件夹,则添加 index.html
if (S_ISDIR(st.st_mode))
path_ += "/index.html";
}
LOG(INFO) << "Path: " << path_ << endl;
// c. 查看HTTP版本
// NOTE 这里只支持 HTTP/1.0 和 HTTP/1.1
pos2++;
http_version_ = first_line.substr(pos2, first_line.length() - pos2);
LOG(INFO) << "HTTP Version: " << http_version_ << endl;
// 检测是否支持客户端 http 版本
if(http_version_ != "HTTP/1.0" && http_version_ != "HTTP/1.1")
return ERR_HTTP_VERSION_NOT_SUPPORTED;
// 设置只在 HTTP/1.1时 允许 持续连接
if(http_version_ != "HTTP/1.1")
isKeepAlive_ = false;
// 更新pos_
pos_ = first_line.length() + 2;
return ERR_SUCCESS;
}从HTTP报文第二行开始,每个以 \r\n为结尾的一行数据中,都有一个 key: value的键值对(header最后一行除外)。因此我们需要继续遍历请求报文的数据,将每个 HTTP header 存入数据结构中。如果解析报文的时候出现错误,则返回 ERR_BAD_REQUEST 错误。
这里有个点需要注意:HTTP/1.1默认支持持续连接,因此 HttpHandler 的成员变量 isKeepAlive_ 默认为 true。但如果客户端中存在这样的 http header Connection: close,则说明当前连接并非持续性的,因此处理完当前 http 请求后必须马上断开连接。所以当我们接收到了Connection: close这样的http header时,必须设置 isKeepAlive_ 变量为 false。
综上所述,最终实现的代码如下:
HttpHandler::ERROR_TYPE HttpHandler::parseHttpHeader()
{
// 清除之前的 http header
headers_.clear();
size_t pos1, pos2;
for(pos1 = pos_;
(pos2 = request_.find("\r\n", pos1)) != string::npos;
pos1 = pos2 + 2)
{
string&& header = request_.substr(pos1, pos2 - pos1);
// 如果遍历到了空头,则表示http header部分结束
if(header.size() == 0)
break;
pos1 = header.find(' ');
if(pos1 == string::npos) return ERR_BAD_REQUEST;
// key处减去1是为了消除key里的最后一个冒号字符
string&& key = header.substr(0, pos1 - 1);
// key 转小写
transform(key.begin(), key.end(), key.begin(), ::tolower);
// 获取 value
string&& value = header.substr(pos1 + 1);
LOG(INFO) << "HTTP Header: [" << key << " : " << value << "]" << endl;
headers_[key] = value;
}
// 获取header完成后,处理一下 Connection 头
auto conHeaderIter = headers_.find("connection");
if(conHeaderIter != headers_.end())
{
string value = conHeaderIter->second;
transform(value.begin(), value.end(), value.begin(), ::tolower);
if(value != "keep-alive")
isKeepAlive_ = false;
}
// 判断处理空 header 条目的 \r\n
if((request_.size() < pos1 + 2) || (request_.substr(pos1, 2) != "\r\n"))
return ERR_BAD_REQUEST;
pos_ = pos1 + 2;
return ERR_SUCCESS;
}http响应报文格式如下所示:
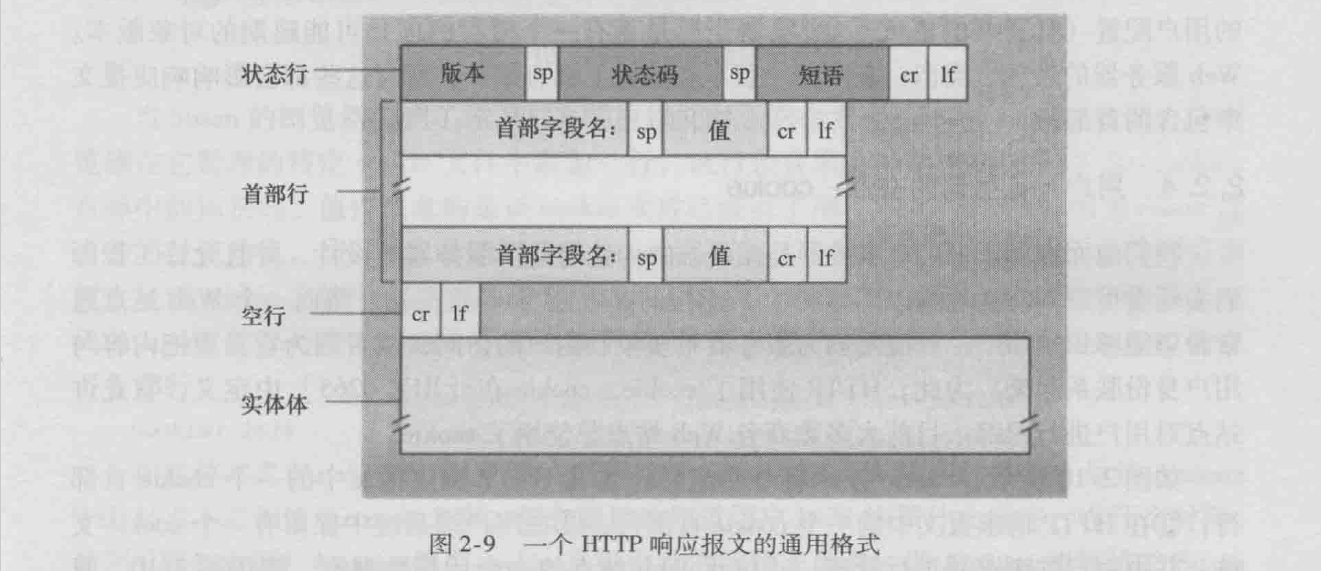
照着这个报文格式,照葫芦画瓢构建一个报文并将其发送至客户端即可。
这里要注意一点,当前连接是否继续保持取决于 isKeepAlive_ 变量。具体实现如下所示:
HttpHandler::ERROR_TYPE HttpHandler::sendResponse(const string& responseCode, const string& responseMsg,
const string& responseBodyType, const string& responseBody)
{
stringstream sstream;
sstream << "HTTP/1.1" << " " << responseCode << " " << responseMsg << "\r\n";
sstream << "Connection: " << (isKeepAlive_ ? "Keep-Alive" : "Close") << "\r\n";
sstream << "Server: WebServer/1.0" << "\r\n";
sstream << "Content-length: " << responseBody.size() << "\r\n";
sstream << "Content-type: " << responseBodyType << "\r\n";
sstream << "\r\n";
sstream << responseBody;
string&& response = sstream.str();
ssize_t len = writen(client_fd_, (void*)response.c_str(), response.size());
// 输出返回的数据
LOG(INFO) << "<<<<- Response Packet ->>>> " << endl;
LOG(INFO) << "{" << escapeStr(response) << "}" << endl;
if(len < 0 || static_cast<size_t>(len) != response.size())
return ERR_SEND_RESPONSE_FAIL;
return ERR_SUCCESS;
}当 handlerError 错误处理函数被调用时,在该函数内部将简单构建一个 html 错误提示页面,并将该页面发送至远程客户端。具体实现如下所示:
HttpHandler::ERROR_TYPE HttpHandler::handleError(const string& errCode, const string& errMsg)
{
string errStr = errCode + " " + errMsg;
string responseBody =
"<html>"
"<title>" + errStr + "</title>"
"<body>" + errStr +
"<hr><em> Kiprey's Web Server</em>"
"</body>"
"</html>";
return sendResponse(errCode, errMsg, "text/html", responseBody);
}HttpHandler 中的 RunEventLoop 函数维护了整个连接的事件循环。具体操作如下:
- 首先,由于 HTTP/1.1 协议支持 持续连接,因此控制流将会进入一个 while 循环,循环进行读取请求并发送响应这样的过程。
- while 循环内部中,首先读取来自客户端的数据,之后进行 URI 与 http header 的解析。如果上面中任何一步存在错误,则发送对应的错误页面给客户端,或者退出循环断开连接。
- 如果上述步骤没有错误,则打开目标文件,将文件数据通过 mmap 函数映射到内存,读取并发送至远程客户端。而如果目标文件不存在,则返回 404 错误;文件映射失败则返回 500 错误。
- 最后返回 while 循环头部,继续等待新的请求报文。
void HttpHandler::RunEventLoop()
{
ERROR_TYPE err_ty;
LOG(INFO) << "------------------- New Connection -------------------" << endl;
// 输出连接
printConnectionStatus();
// 持续连接
while(isKeepAlive_)
{
LOG(INFO) << "<<<<- Request Packet ->>>> " << endl;
// 从socket读取请求数据, 如果读取失败,或者断开连接
// NOTE 这里的 readRequest 必须完整读取整个 http 报文
if((err_ty = readRequest()) != ERR_SUCCESS)
{
if(err_ty == ERR_READ_REQUEST_FAIL)
LOG(ERROR) << "Read request failed ! " << strerror(errno) << endl;
else if(err_ty == ERR_CONNECTION_CLOSED)
LOG(INFO) << "Socket(" << client_fd_ << ") was closed." << endl;
else
assert(0 && "UNREACHABLE");
// 断开连接
break;
}
LOG(INFO) << "{" << escapeStr(request_) << "}" << endl;
// 解析信息 ------------------------------------------
LOG(INFO) << "<<<<- Request Info ->>>> " << endl;
// 1. 先解析第一行
if((err_ty = parseURI()) != ERR_SUCCESS)
{
if(err_ty == ERR_NOT_IMPLEMENTED)
{
LOG(ERROR) << "Request method is not implemented." << endl;
handleError("501", "Not Implemented");
}
else if(err_ty == ERR_HTTP_VERSION_NOT_SUPPORTED)
{
LOG(ERROR) << "Request HTTP Version Not Supported." << endl;
handleError("505", "HTTP Version Not Supported");
}
else if(err_ty == ERR_BAD_REQUEST)
{
LOG(ERROR) << "Bad Request." << endl;
handleError("400", "Bad Request");
}
else
assert(0 && "UNREACHABLE");
continue;
}
// 2. 解析每一条http header
if((err_ty = parseHttpHeader()) != ERR_SUCCESS)
{
if(err_ty == ERR_BAD_REQUEST)
{
LOG(ERROR) << "Bad Request." << endl;
handleError("400", "Bad Request");
}
else
assert(0 && "UNREACHABLE");
continue;
}
// 3. 输出剩余的 HTTP body
LOG(INFO) << "HTTP Body: {"
<< escapeStr(request_.substr(pos_, request_.length() - pos_))
<< "}" << endl;
// 发送目标数据 ------------------------------------------
// 试图打开一个文件
int file_fd;
if((file_fd = open(path_.c_str(), O_RDONLY, 0)) == -1)
{
// 如果打开失败,则返回404
LOG(ERROR) << "File [" << path_ << "] open failed ! " << strerror(errno) << endl;
handleError("404", "Not Found");
continue;
}
else
{
// 获取目标文件的大小
struct stat st;
if(stat(path_.c_str(), &st) == -1)
{
LOG(ERROR) << "Can not get file [" << path_ << "] state ! " << endl;
handleError("500", "Internal Server Error");
continue;
}
// 读取文件, 使用 mmap 来高速读取文件
void* addr = mmap(nullptr, st.st_size, PROT_READ, MAP_PRIVATE, file_fd, 0);
// 记得关闭文件描述符
close(file_fd);
// 异常处理
if(addr == MAP_FAILED)
{
LOG(ERROR) << "Can not map file [" << path_ << "] -> mem ! " << endl;
handleError("500", "Internal Server Error");
continue;
}
// 将数据从内存页存入至 responseBody
char* file_data_ptr = static_cast<char*>(addr);
string responseBody(file_data_ptr, file_data_ptr + st.st_size);
// 记得删除内存
int res = munmap(addr, st.st_size);
if(res == -1)
LOG(ERROR) << "Can not unmap file [" << path_ << "] <-> mem ! " << endl;
// 获取 Content-type
string suffix = path_;
// 通过循环找到最后一个 dot
size_t dot_pos;
while((dot_pos = suffix.find('.')) != string::npos)
suffix = suffix.substr(dot_pos + 1);
// 发送数据
if(sendResponse("200", "OK", MimeType::getMineType(suffix), responseBody) != ERR_SUCCESS)
LOG(ERROR) << "Send Response failed !" << endl;
}
}
LOG(INFO) << "------------------ Connection Closed ------------------" << endl;
}最后简单说说编译和调试。使用make命令即可构建带有调试信息的 WebServer 二进制文件。这里的makefile是直接抄自 linyacool/WebServer 中的 makefile,并在其基础之上,修改了编译优化选项为 -O0,以及设置编译时附带额外的调试信息-g3 -ggdb3。
-g所携带的调试信息可以被多个调试器所共用,而-ggdb所携带的调试信息是专供 gdb 使用,两者不完全等同。-ggdb3的调试等级甚至可以调试宏。
这里的调试主要是使用 gdb + pwndbg 来完成(gdb 永远的神)。因为多线程程序在gdb下调试非常的方便,它可以很快的切换线程上下文(使用info <threadNum>)以及栈帧上下文(使用f <frameNum>);而且临时查看 errno 以及临时调用 strerror(errno)查看错误信息等等都非常地方便。