原文:
www.kdnuggets.com/2021/10/four-basic-steps-data-preparation.html
评论
由Rosaria Silipo撰写,KNIME 数据科学布道主管
数据准备的步骤是什么?我们是否需要针对特定问题采取具体步骤?答案并不那么简单:实践和知识将为每种情况设计最佳方案。
 1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
1. 谷歌网络安全证书 - 快速进入网络安全职业生涯。
 2. 谷歌数据分析专业证书 - 提升你的数据分析能力
2. 谷歌数据分析专业证书 - 提升你的数据分析能力
3. 谷歌 IT 支持专业证书 - 支持你的组织的 IT
首先,数据准备有两种类型:KPI 计算用于从原始数据中提取信息,以及数据科学算法的数据准备。前者依赖于领域和业务,而后者则更为标准化。
在这篇博客文章中,我们专注于准备数据以供机器学习算法使用的操作。这些数据操作有很多,其中一些更为通用,而另一些则更针对特定情况。当你考虑到有整门大学课程专注于数据准备操作时,这个话题太广泛,无法在一篇简短的文章中涵盖所有内容。
我们希望在这里介绍四个非常基础且非常通用的机器学习算法数据准备步骤。我们将描述在特定示例中如何及为什么应用这些转换。
-
归一化
-
转换
-
缺失值插补
-
重采样
让我们以数据科学中的一个简单例子来说明:流失预测。简单来说,流失预测旨在区分那些有流失风险的客户和其他客户。通常,使用公司 CRM 系统中的数据,包括客户行为、人口统计信息和收入特征。有些客户流失,有些则没有。这些数据然后用于训练一个预测模型,以区分这两类客户。
这个问题是一个二分类问题。输出类别(流失)只有两个可能的值:流失“是”和流失“否”。任何分类算法都适用:决策树、随机森林、逻辑回归等。逻辑回归有点像历史算法,运行快速且易于解释。我们将采用它来解决这个问题。
让我们开始构建我们的工作流程。首先,我们从两个独立的文件中读取数据,一个 CSV 文件和一个 Excel 文件,然后应用逻辑回归,最后将模型写入文件。
但别急,Nelly!让我们先查看数据。
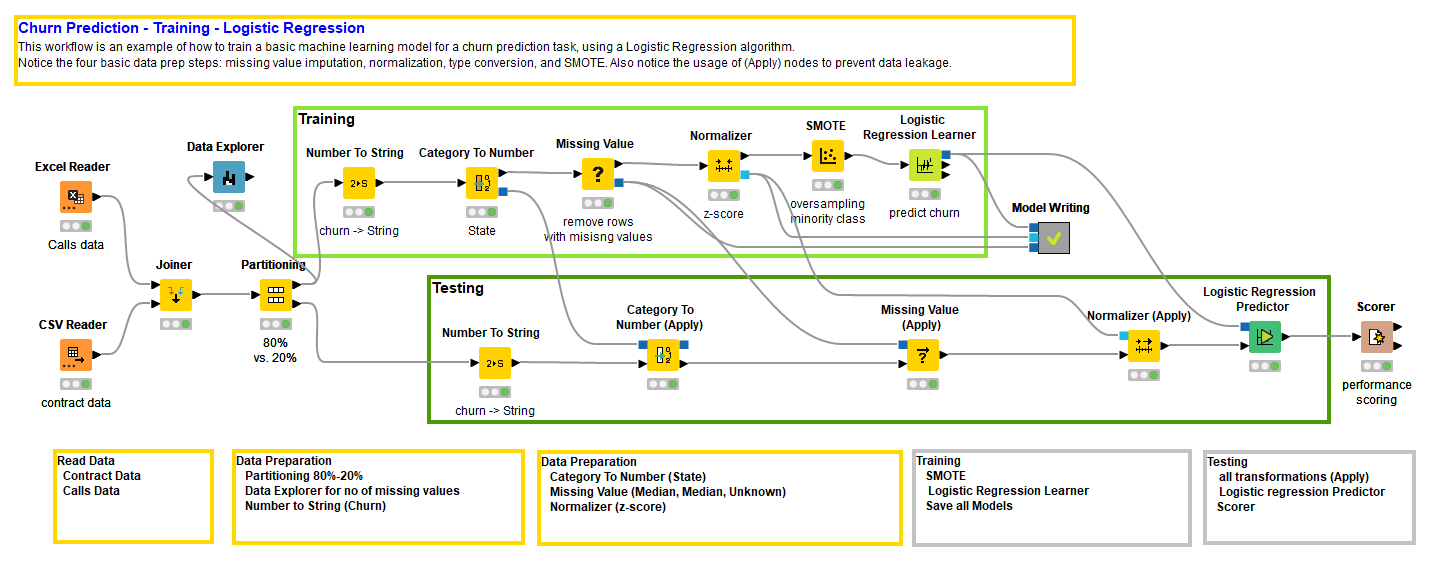
图 1. 训练和评估逻辑回归模型的工作流程,包括四个常见的数据准备步骤(点击放大)。
训练一个模型还不足以声称我们有一个好的模型。我们还需要通过在单独的数据子集上使用准确性或误差度量来评估它。换句话说,我们需要创建一对不重叠的子集——训练集和测试集——从原始数据集中随机抽取。为此,我们使用分区节点。分区节点从输入数据表中随机提取数据,按其配置窗口中指定的比例,生成两个数据子集并在两个输出端口输出。
训练集将由逻辑回归学习器节点用于训练模型,测试集将由逻辑回归预测器节点和后续的评分节点用于评分模型。逻辑回归预测器节点生成客户流失预测,而评分节点评估这些预测的准确性。
在这里,我们没有将分区操作包含在数据准备操作中,因为它并不会真正改变数据。然而,这只是我们的看法。如果你想将分区包含在数据准备操作中,只需将标题从“四”改为“数据准备的五个基本步骤” :-)
接下来,逻辑回归需要将输入数据标准化到区间[0, 1],如果能够高斯标准化则更好。任何包括距离或方差的算法都将在标准化的数据上有效。这是因为具有较大范围的特征会影响方差和距离的计算,可能会主导整个算法。由于我们希望所有输入特征被平等考虑,因此数据的标准化是必要的。
例如,决策树依赖于概率,不需要标准化数据,但逻辑回归依赖于方差,因此需要先前的标准化;许多聚类算法,如 k-Means,依赖于距离,因此需要标准化;神经网络使用激活函数,其参数落在[0,1]之间,因此也需要标准化;等等。你将学会识别哪些算法需要标准化及其原因。
逻辑回归确实需要高斯标准化的数据。因此,必须引入一个Normalizer节点来标准化训练数据。
逻辑回归在数值属性上工作。这对于原始算法来说是正确的。有时,在一些包中,你会看到逻辑回归也接受分类的,即名义输入特征。在这种情况下,逻辑回归学习函数内部实现了一个准备步骤,将分类特征转换为数字。通常,逻辑回归只在数值特征上工作。
由于我们希望掌控操作,而不是盲目地将转换操作委托给逻辑回归扩展包,因此我们可以自行实现这个转换步骤。实际上,我们希望将一个名义列转换为一个或多个数值列。这里有两个选项:
-
索引编码。每个名义值被映射为一个数字。
-
独热编码。每个名义值创建一个新列,其单元格根据原始列中该值的存在与否填充 1 或 0。
索引编码解决方案从一个名义列生成一个数值列。然而,由于映射函数,它在两个值之间引入了人为的数值距离。
独热编码解决方案不会引入任何人为距离。然而,它从一个原始列生成许多列,因此增加了数据集的维度,并人为地加重了原始列的权重。
没有完美的解决方案。最终这是在准确性和速度之间的妥协。
在我们的案例中,原始数据集中有两个分类列:State和Phone。Phone是一个唯一的 ID,用于识别每个客户。由于它不包含关于客户行为或合同的任何一般信息,我们在分析中不会使用它。State则相反,可能包含相关信息。某个州的客户可能由于当地竞争者的存在,更倾向于流失。
为了转换输入特征State,我们使用了基于索引的编码,通过Category to Number节点实现。
在光谱的另一端,我们有目标列Churn,其中包含有关客户是否流失(1)或未流失(0)的信息。许多分类器训练算法要求类别标签的目标列为分类的。在我们的案例中,Churn 列最初被读取为数值(0/1),必须转换为分类类型,通过Number To String节点。
逻辑回归的另一个缺点是它不能处理数据中的缺失值。一些逻辑回归学习函数包括缺失值策略。然而,正如我们之前所说的,我们希望控制整个过程。让我们也决定缺失值填补的策略。
文献中有很多缺失值填补的策略。你可以在文章“缺失值填补:综述”中查看详细信息。
最简单的策略就是忽略有缺失值的数据行。这是粗糙的,但如果我们有多余的数据,并不算错。当数据很少时,这就变得有问题了。在这种情况下,仅仅因为某些特征缺失而丢弃一些数据,可能不是最聪明的决定。
如果我们对领域有一些了解,我们就会知道缺失值的含义,并且能够提供一个合理的替代值。
由于我们一无所知,数据集也确实不大,我们需要找到一些替代方案。如果我们不想思考,那么采用中位数、均值或最频繁值是一个合理的选择。如果我们一无所知,就选择多数值或中间值。这是我们在这里采用的策略。
然而,如果我们想稍微思考一下,我们可能想通过 数据探索器 节点对数据集进行一些统计分析,以估计缺失值问题的严重性。如果缺失值问题严重,我们可以在受影响最严重的列中隔离那些有缺失值的行。从这些观察中,可能会得到一个合理的替代值的想法。当然,在实施缺失值策略后,我们这样做了。事实上,数据探索器节点的视图显示我们的数据集没有缺失值。完全没有。哦,好吧!让我们把缺失值节点留在那里以完成工作。
现在最后一个基本问题:目标类别在数据集中是否均匀分布?
在我们的情况下,它们并不是这样。两个类别之间存在 85%(未流失)对 15%(流失)的不平衡。当一个类别比另一个类别少得多时,训练算法可能会忽视这个类别。如果不平衡不是很严重,那么在分区节点中使用分层抽样策略进行随机数据抽取应该足够了。然而,如果不平衡较强,如本例所示,则可能需要在训练算法之前进行一些重采样。
要进行重采样,你可以选择对多数类别进行欠采样,或者对少数类别进行过采样,这取决于你处理的数据量以及是否可以承担丢弃多数类别数据的奢侈。这种数据集不大,因此我们决定使用 SMOTE 算法对少数类别进行过采样。
现在,我们必须对测试集重复所有这些变换,使用与工作流的训练分支中定义的完全相同的变换。为了防止数据泄漏,我们不能将测试数据用于任何这些变换的制作。因此,在工作流的测试分支中,我们使用了(应用)节点,仅仅将变换应用于测试数据。
请注意,没有 SMOTE(应用)节点。这是因为我们要么重新应用 SMOTE 算法来对测试集中的少数类进行过采样,要么采用考虑类别不平衡的评估指标,如 Cohen’s Kappa。我们选择用 Cohen’s Kappa 指标来评估模型质量。
我们已经完成了工作流的最后一步(你可以从 KNIME Hub 下载工作流 数据准备的四个基本步骤)。我们已经准备了训练数据,对其进行了预测算法训练,使用完全相同的变换准备了测试数据,将训练好的模型应用于测试数据,并将预测结果与实际类别进行评分。评分器 节点生成了多个准确度指标来评估模型的质量。我们选择了 Cohen’s Kappa,因为它可以衡量算法在两个类别上的表现,即使它们高度不平衡。
我们得到了接近 0.4 的 Cohen’s Kappa。这是我们能做的最好结果吗?我们应该尝试回到之前的步骤,调整一些参数,看看是否能得到更好的模型。与其手动调整参数,我们甚至可以引入优化周期。查看免费的电子书 从建模到模型评估,了解更多展示模型性能的评分技术。
我们现在结束这篇文章,介绍了四种非常基础的数据变换。我们邀请你深入了解这四种变换,并探索其他数据变换,例如降维、特征选择、特征工程、异常值检测、PCA 等。
简介: Rosaria Silipo 不仅是数据挖掘、机器学习、报告和数据仓库领域的专家,她还成为了 KNIME 数据挖掘引擎的公认专家,关于这一点她已出版了三本书:《KNIME Beginner’s Luck》、《The KNIME Cookbook》和《The KNIME Booklet for SAS Users》。之前,Rosaria 曾为欧洲多家公司担任自由数据分析师。她还曾在 Viseca(苏黎世)领导 SAS 开发组,在 Spoken Translation(加州伯克利)使用 C# 实现语音转文本和文本转语音接口,并在 Nuance Communications(加州门罗公园)开发了多种语言的语音识别引擎。Rosaria 于 1996 年获得意大利佛罗伦萨大学的生物医学工程博士学位。
首次发布于 KNIME 博客
原文. 经许可转载。
相关:
-
使用 dplyr 在 R 中进行数据准备,附带备忘单!
-
混乱的数据是美丽的
-
基于机器学习的自动数据标注