Integration PR followups: make_workdiv, uniform_elements, concrete kernel dimensions #141
Conversation
|
I think the plots might look a bit different now that the work division is different, but hopefully they are still run-to-run reproducible (I'll check). For now, I'm just making sure I didn't break something. /run standalone |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
|
Welp, I did break something. I'll look into it |
17d4223 to
aa82696
Compare
|
Hopefully it's fine now. /run standalone |
|
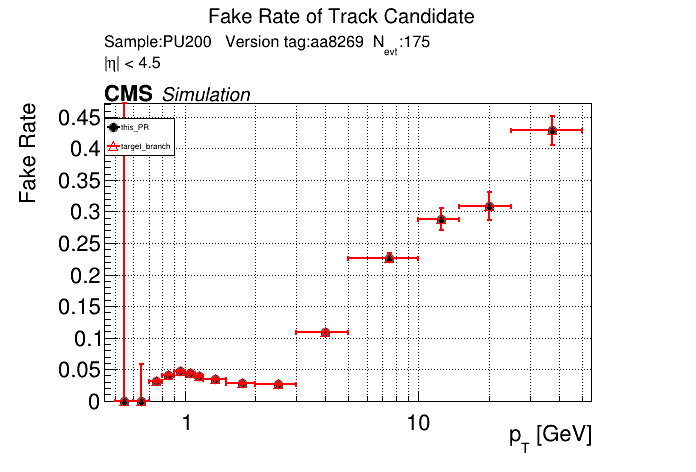
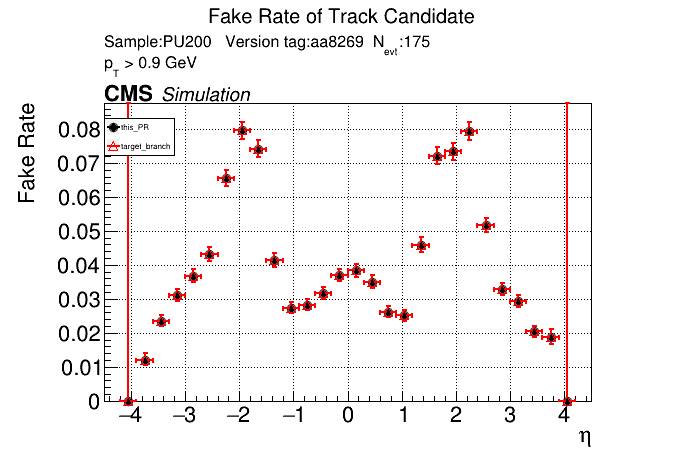
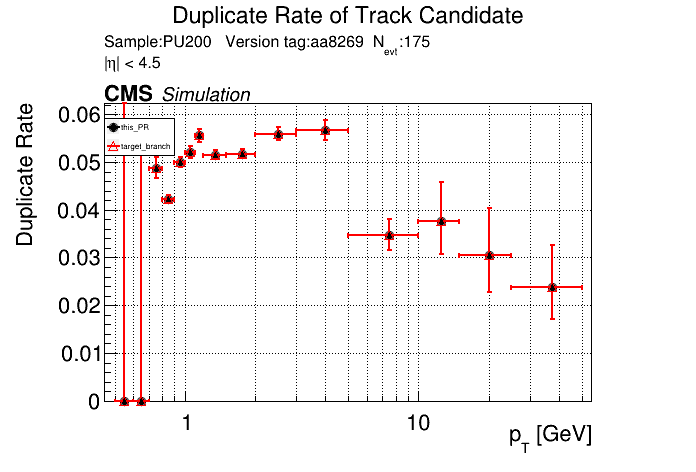
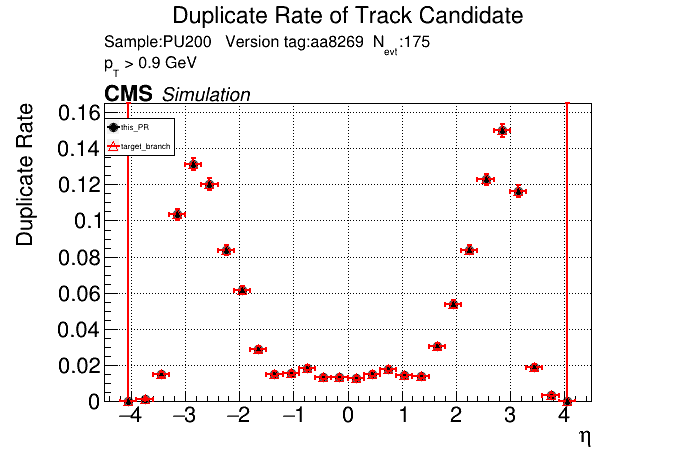
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
|
The plots match perfectly, which is nice. There was a significant increase in timing, especially for |
7278857 to
9444e18
Compare
|
Sorry for all the force-pushing. I made the code compatible with both I think the last low hanging fruit that I'll include here is to set concrete dimensions instead of templated types for kernels and alpaka functions. |
2a034e8 to
0da8474
Compare
|
/run all |
|
There was a problem while building and running in standalone mode. The logs can be found here. |
|
There was a problem while building and running with CMSSW. The logs can be found here. |
I couldn't parse the error to the point of understanding where a fix is needed |
|
We had some issues with our /run all |
|
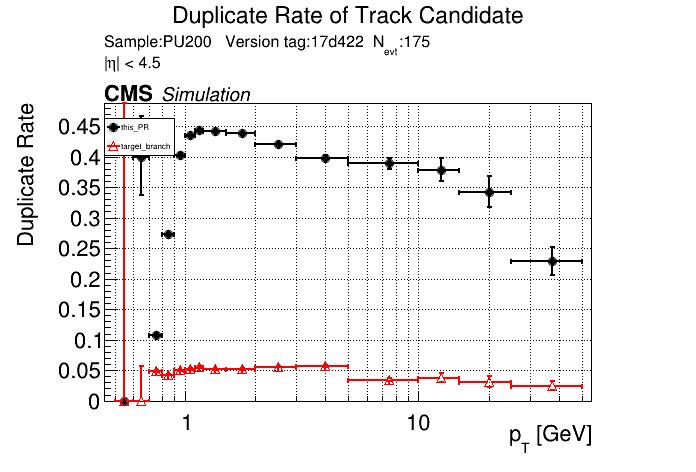
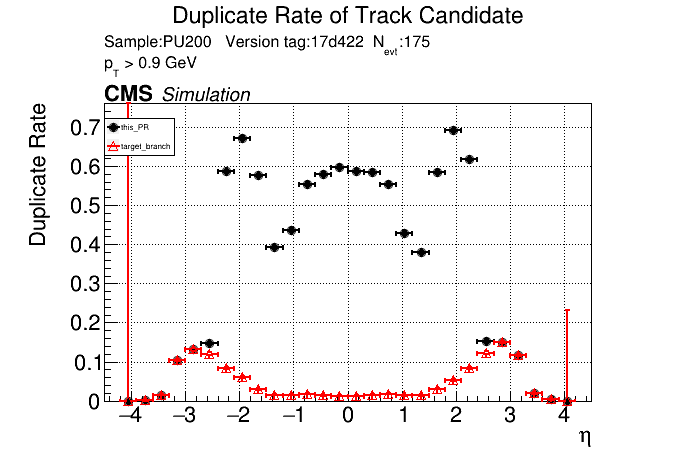
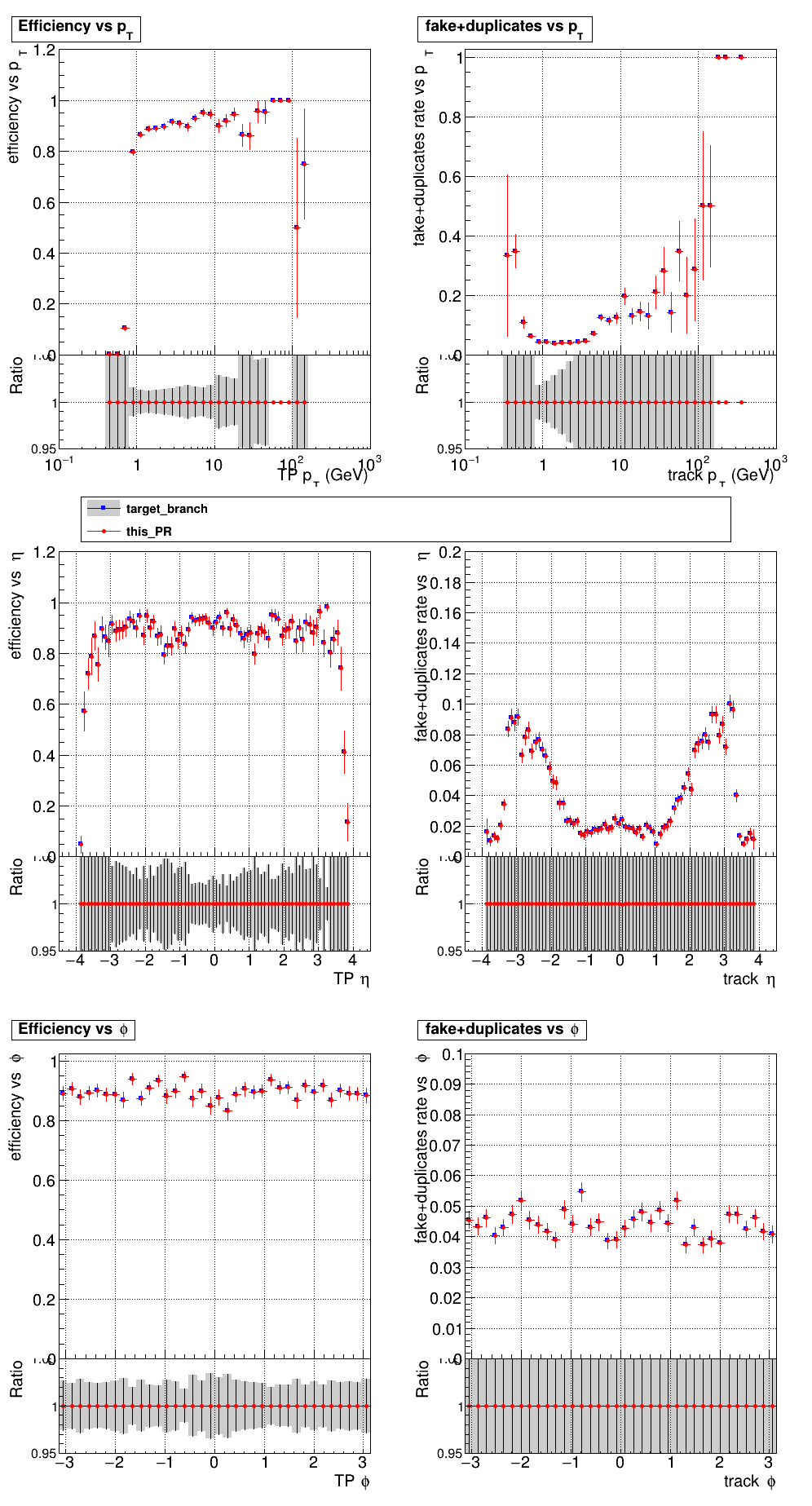
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
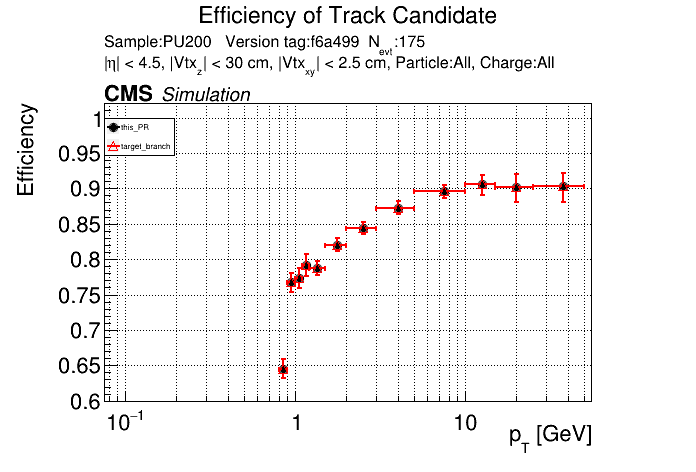
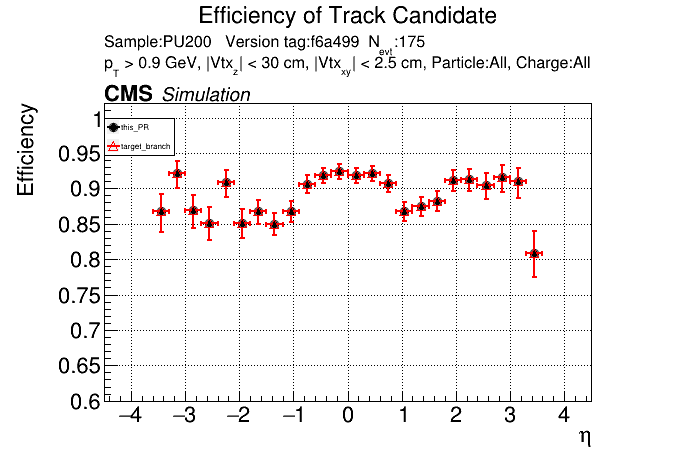
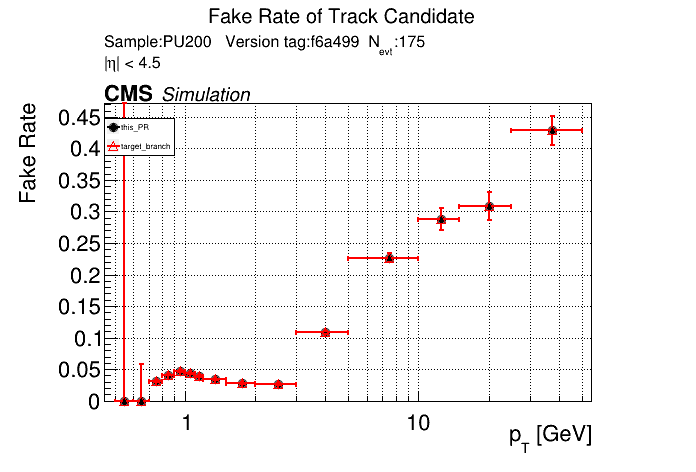
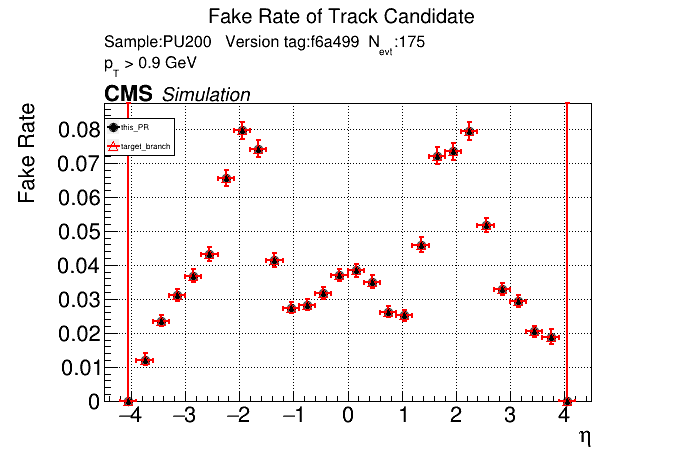
|
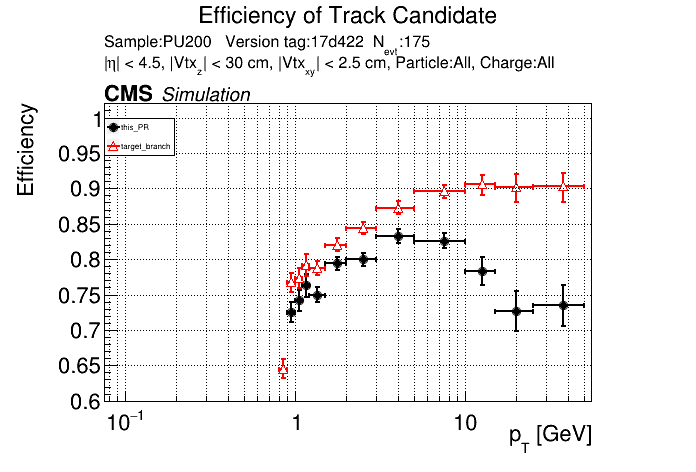
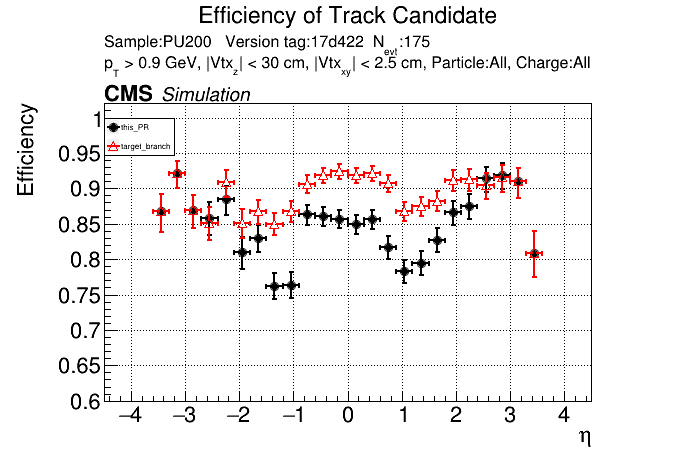
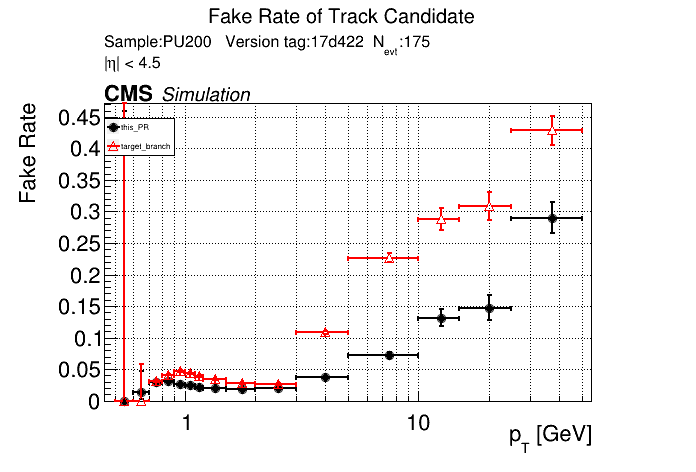
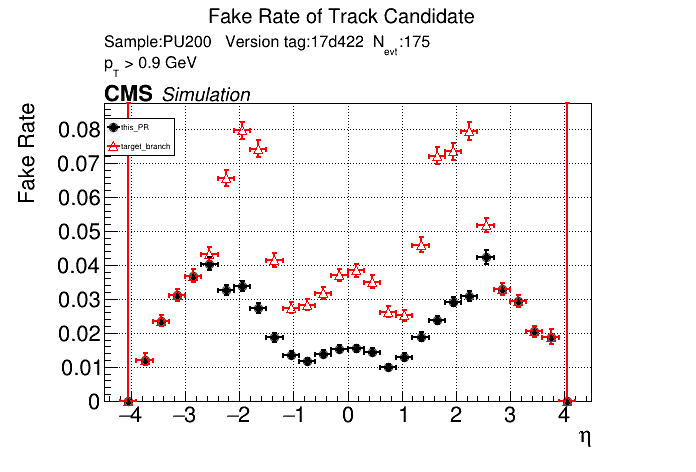
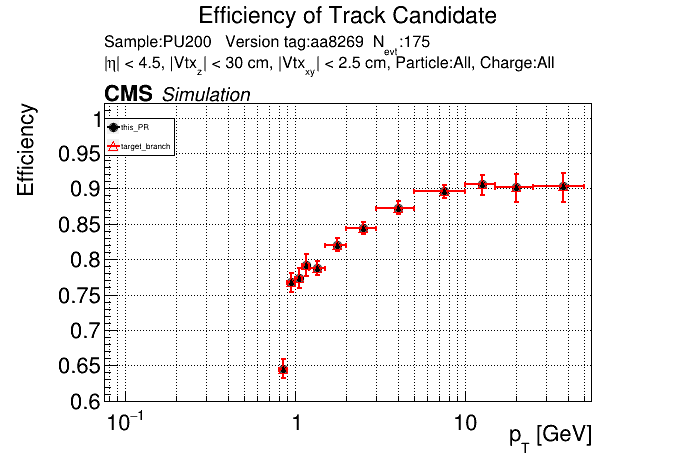
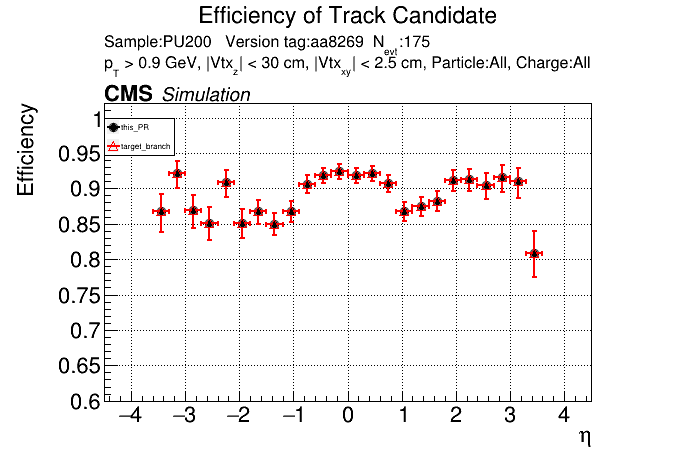
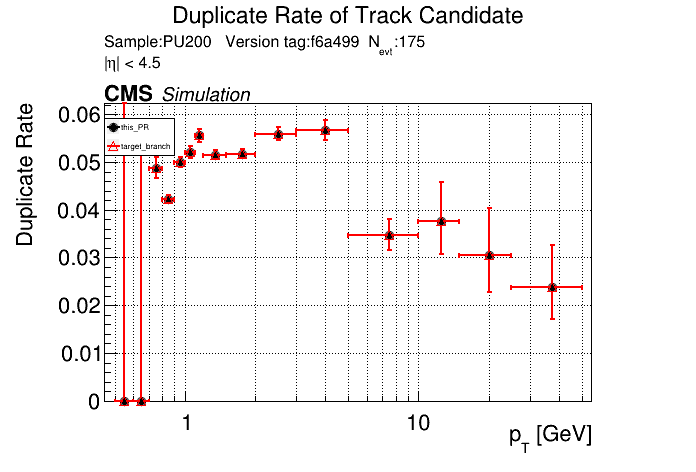
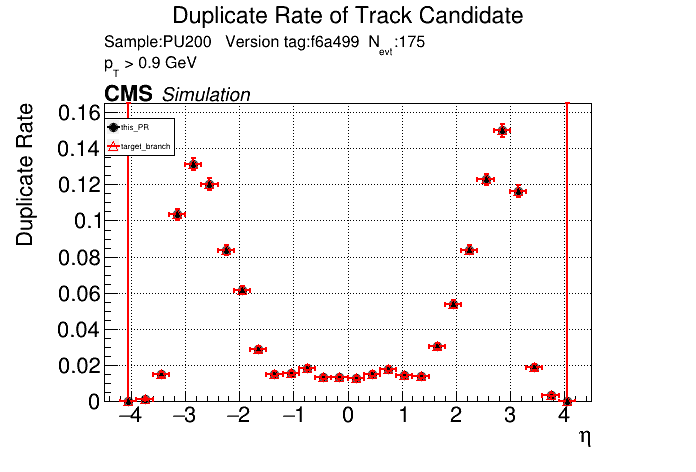
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
I updated the master branch after the merge of #140 . |
f6a499c to
4f9d7f9
Compare
Thank you, Slava. It's fixed now. /run all |
|
There was a problem while building and running in standalone mode. The logs can be found here. |
4f9d7f9 to
c8b78fd
Compare
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
c8b78fd to
1a27b2a
Compare
|
/run all |
|
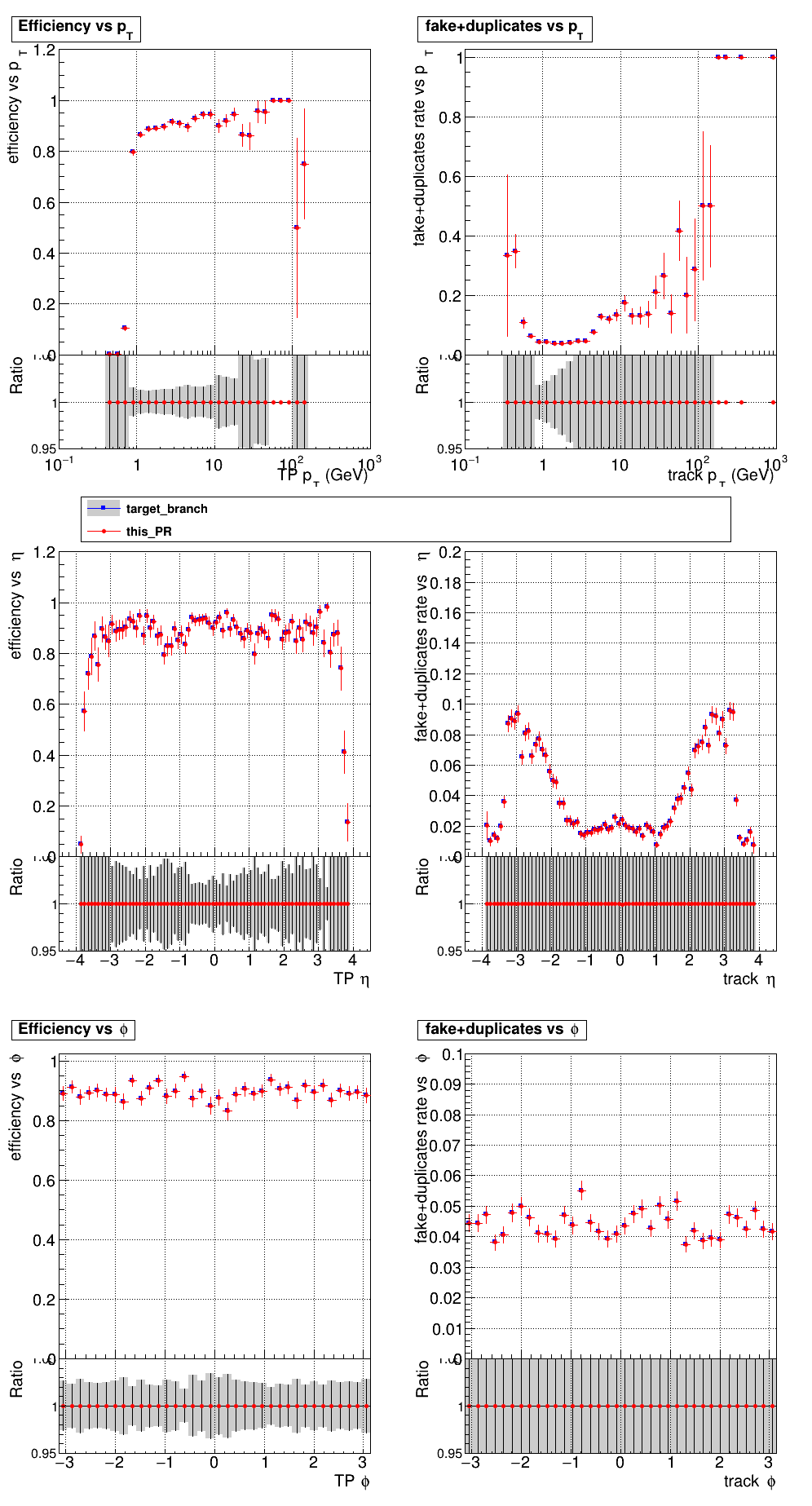
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
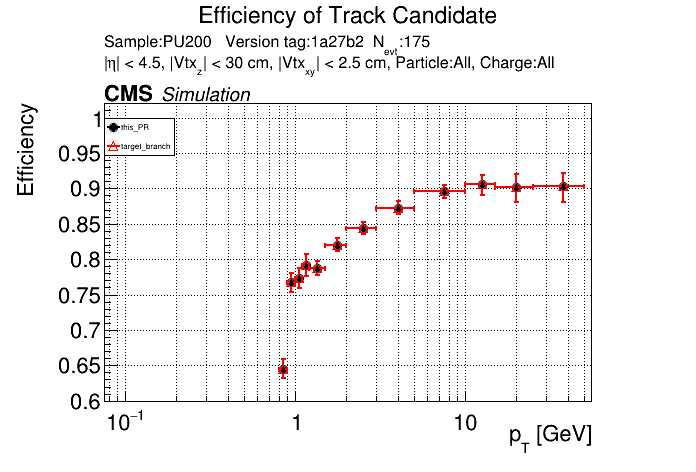
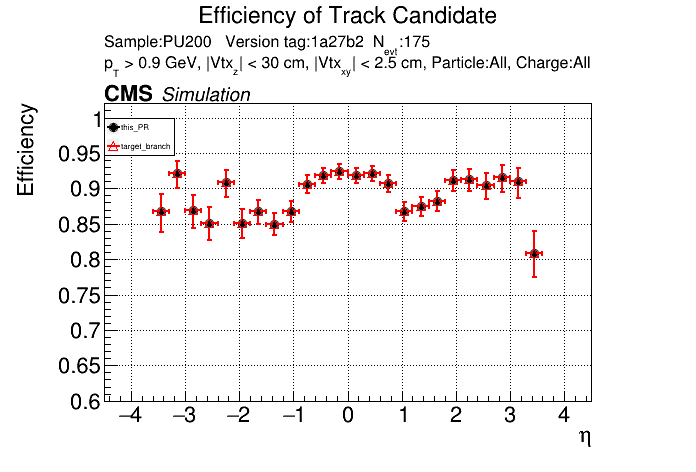
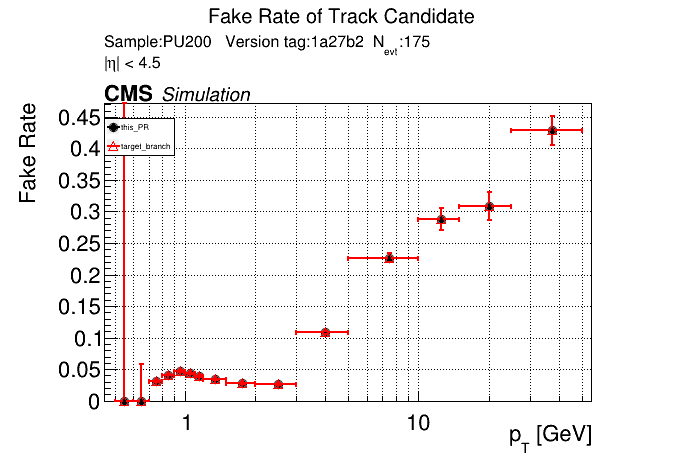
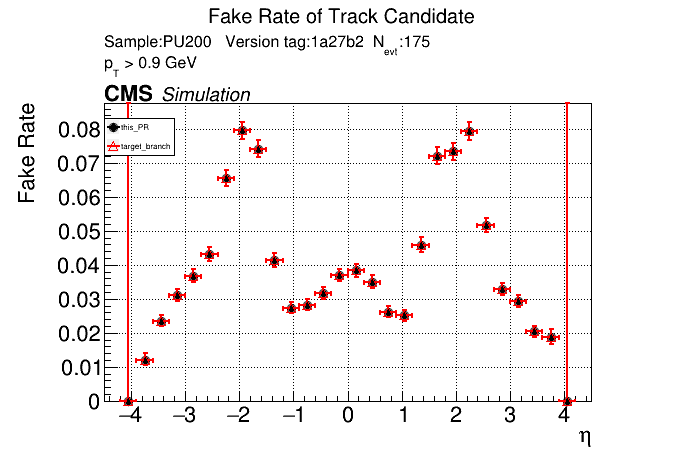
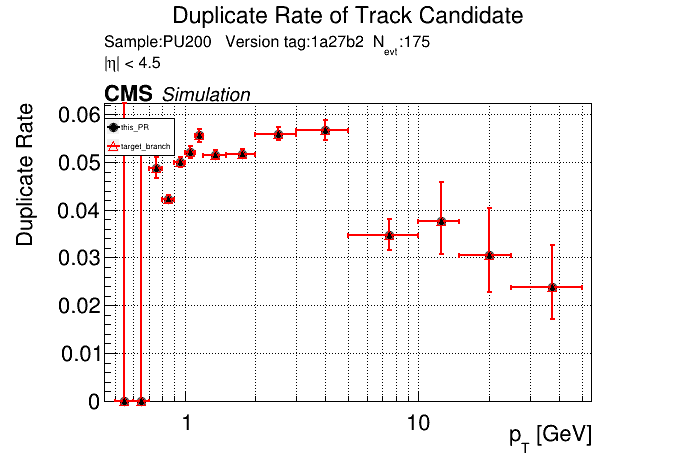
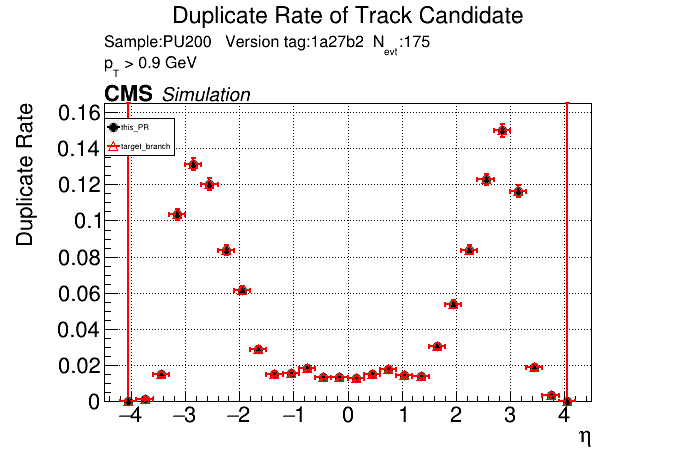
|
before the break we talked about batching, assuming other contributions overlapping this PR can accumulate. |
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
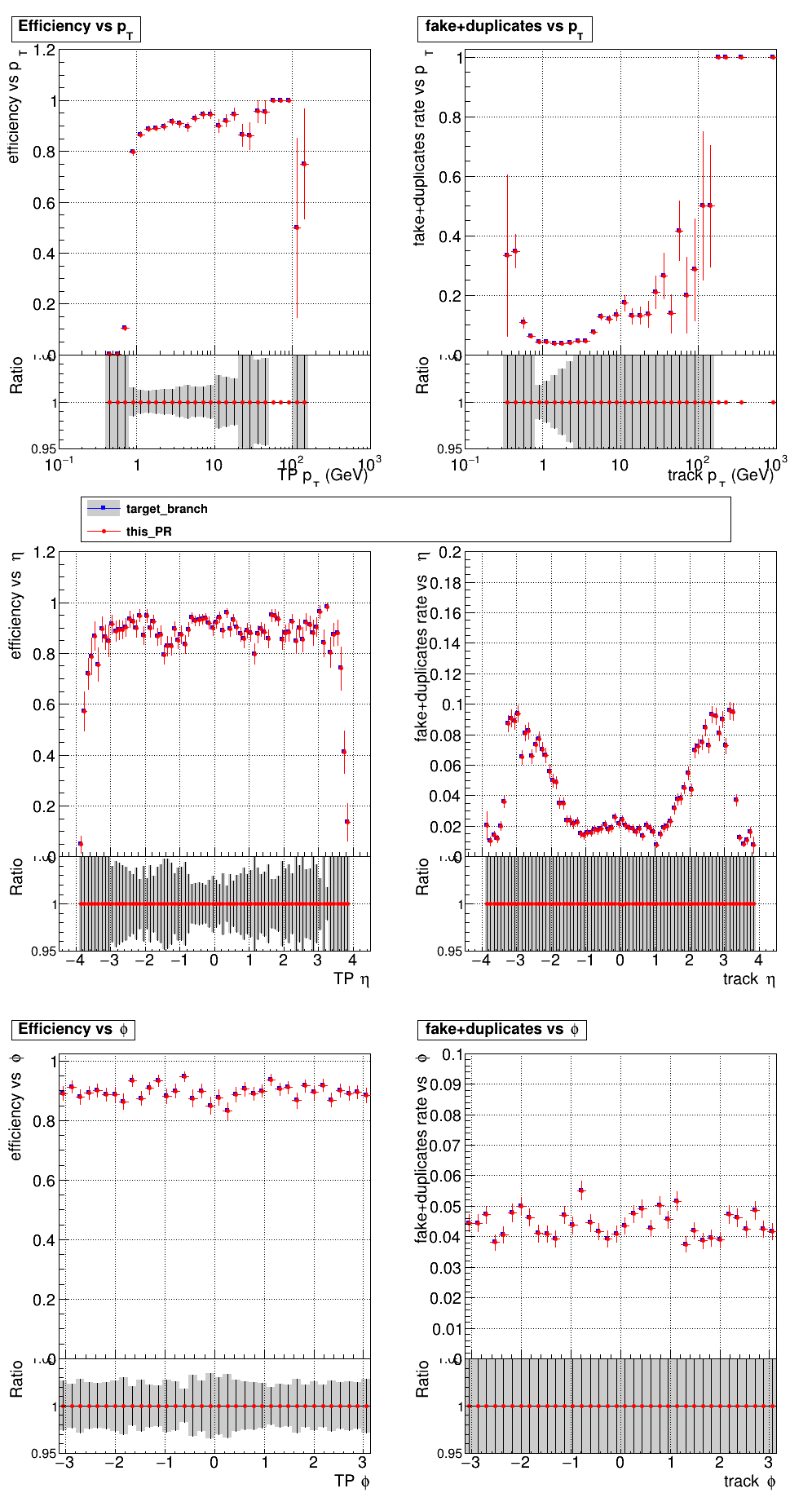
|
this crashed in the bot tests with GPU: did it run locally on GPU or is it some more recent feature in the IBs? |
|
Seems like the bug is outside of the changes I made for this PR. The issue was triggered by the switch from |
|
Nevermind, seems like it is a problem in this PR. Maybe I'm misunderstanding how some other functionality works on GPUs. |
|
Turns out that cms-sw#46967 broke running on GPUs. The binary search is not working for some reason. |
The GPU tests passed back then though: |
the baseline in the PR tests ran OK as well. So, the crash appears from just the incremental addition of this PR. |
The baseline doesn't crash, but it produces garbage results. With the switch from |
Co-authored-by: Andrea Bocci <[email protected]>
1a27b2a to
baa91b3
Compare
|
/run all |
|
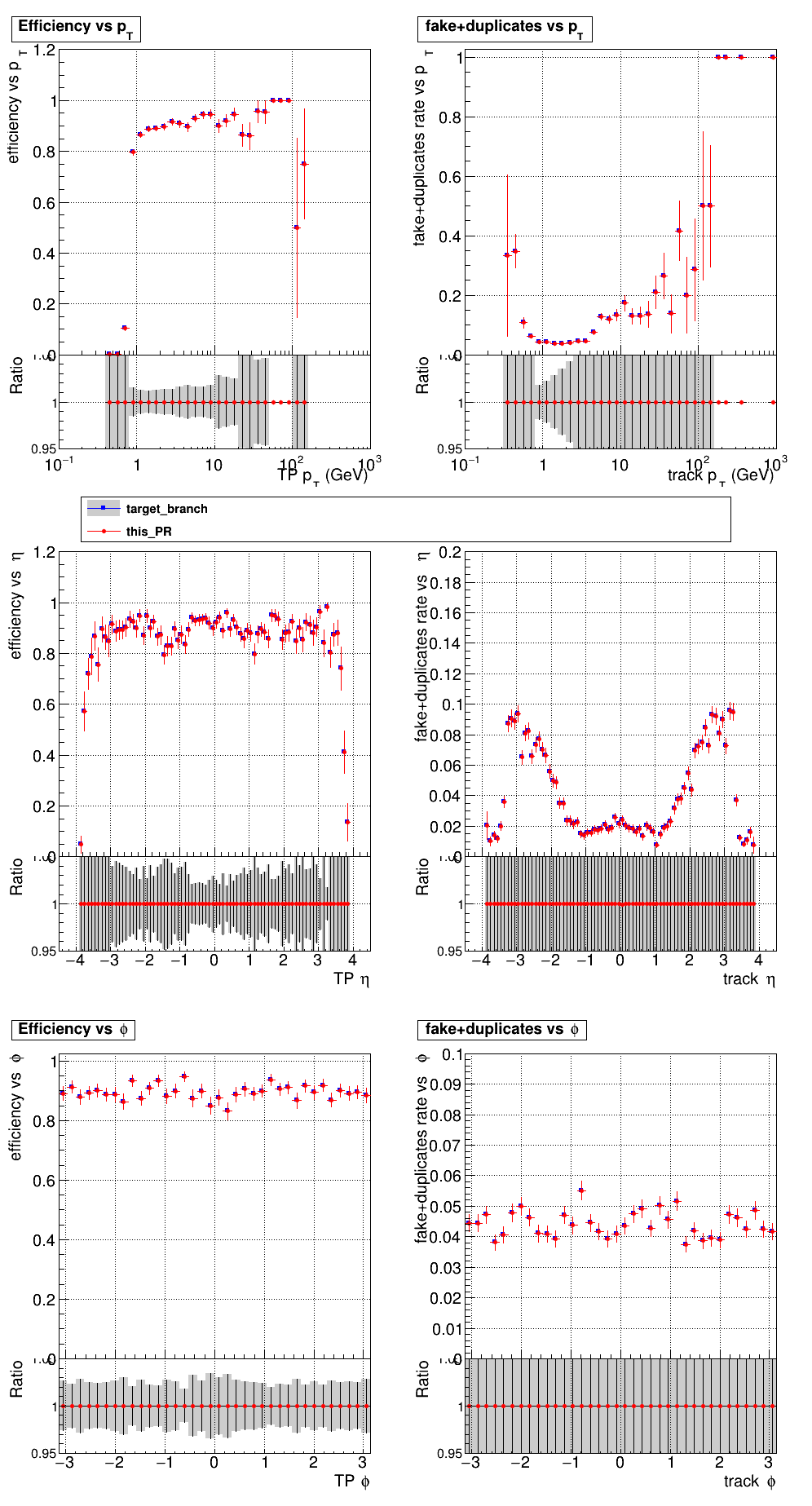
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
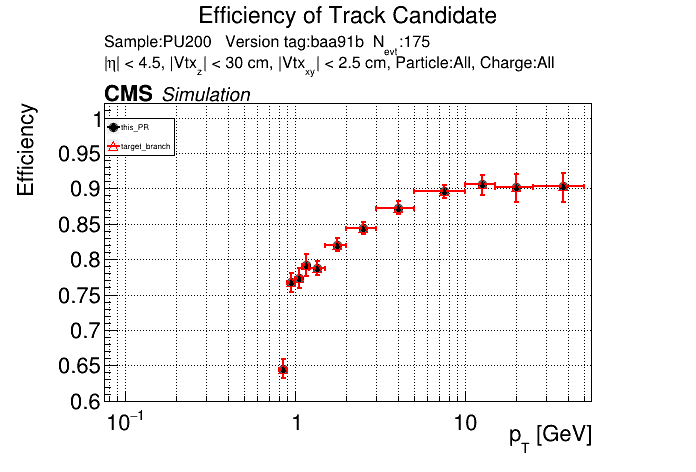
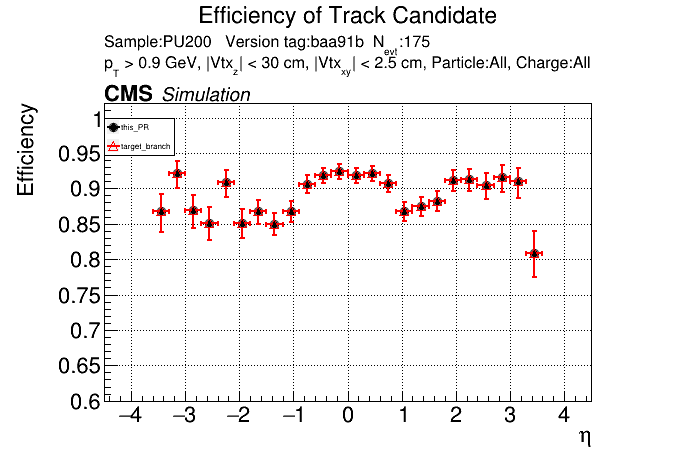
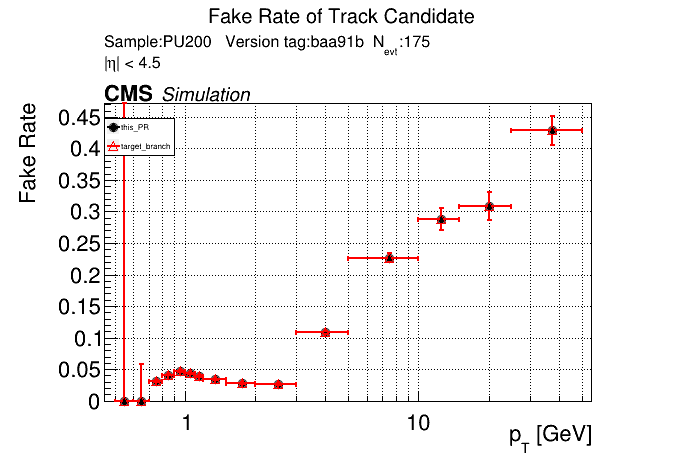
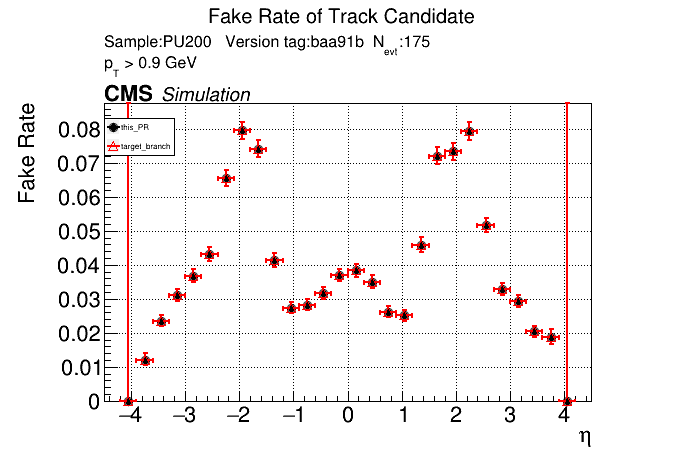
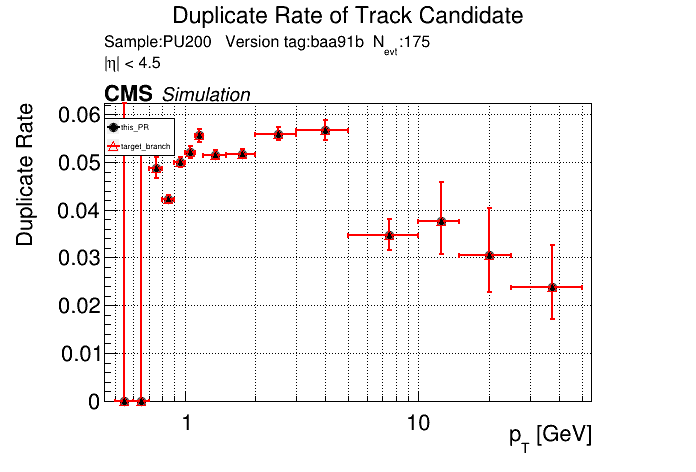
| @@ -694,7 +658,8 @@ namespace ALPAKA_ACCELERATOR_NAMESPACE::lst { | |||
| float y2 = mds.anchorY()[secondMDIndex]; | |||
| float y3 = mds.anchorY()[thirdMDIndex]; | |||
|
|
|||
| circleRadius = computeRadiusFromThreeAnchorHits(acc, x1, y1, x2, y2, x3, y3, circleCenterX, circleCenterY); | |||
| std::tie(circleRadius, circleCenterX, circleCenterY) = | |||
| computeRadiusFromThreeAnchorHits(acc, x1, y1, x2, y2, x3, y3); | |||
There was a problem hiding this comment.
is it shorter to write circleRadius = computeRadiusFromThreeAnchorHits(...).get<0>()
There was a problem hiding this comment.
That's true. I'll wait to see if there are any other comments and I'll fix it
|
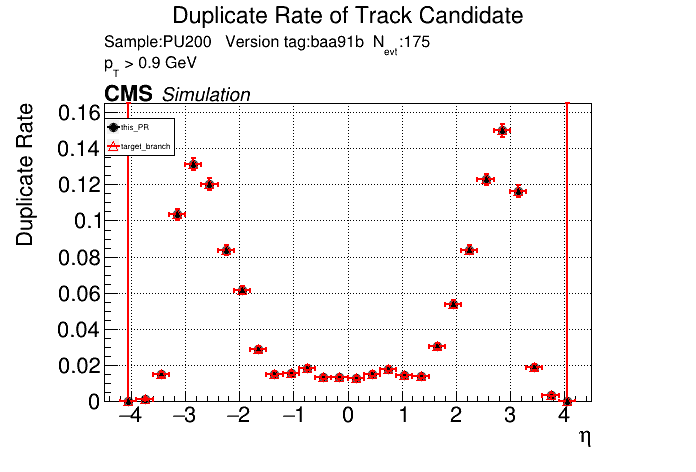
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
|
Here's a timing comparison on cgpu-1: |
I started to address some follow-up tasks in #75. In particular:
cms::alpakatools::makeworkdirinstead of our customcreateWorkDiv.cms::alpakatools::uniform_elementsfor kernel loops.kVerticalModuleSlope.