Dynamic Memory Limits for LST Objects #148
Conversation
fb65216 to
1faa5f8
Compare
|
Performance plots look unchanged, and negligible changes in timing. |
|
/run all |
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
There was a problem while building and running in standalone mode. The logs can be found here. |
|
Should I rebase to master? |
I don't think it will help by itself; the CI is not pulling in the right version of alpaka. |
|
/run all |
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
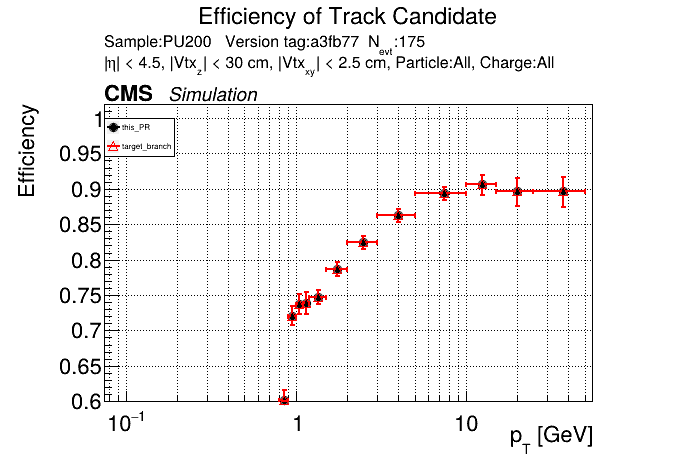
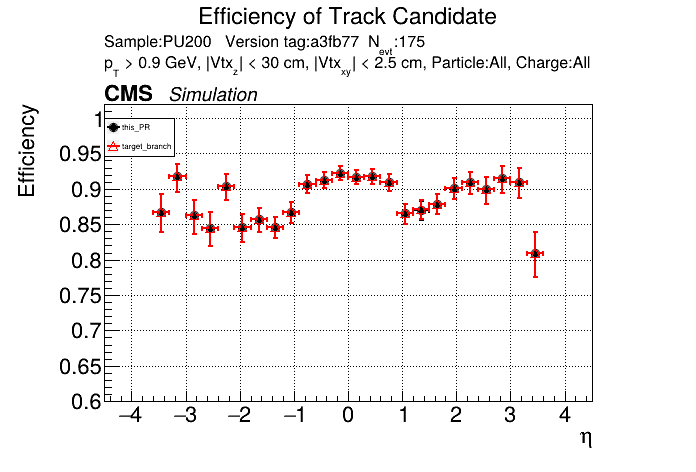
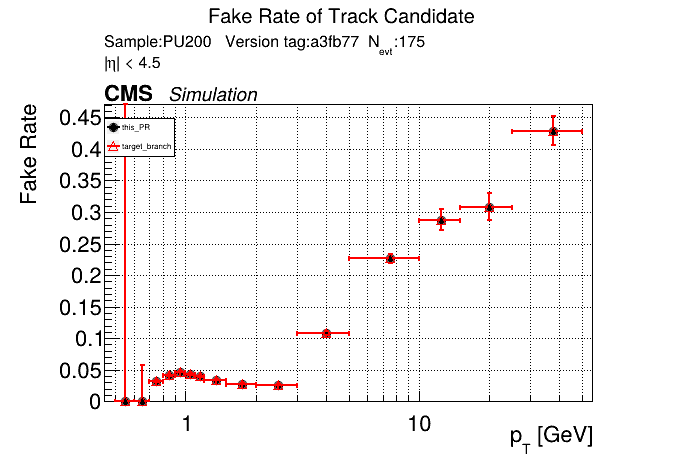
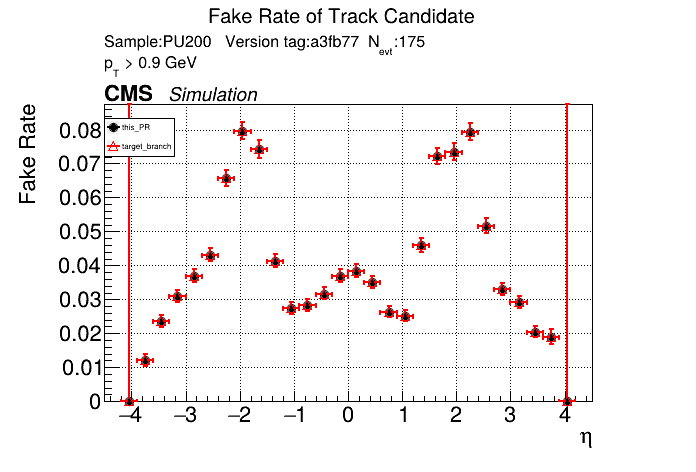
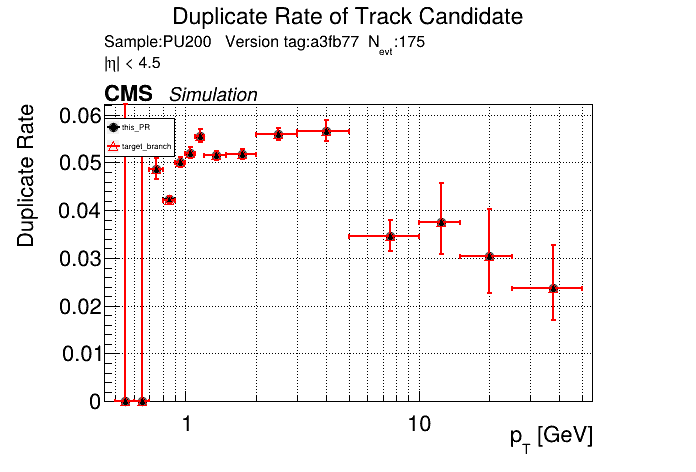
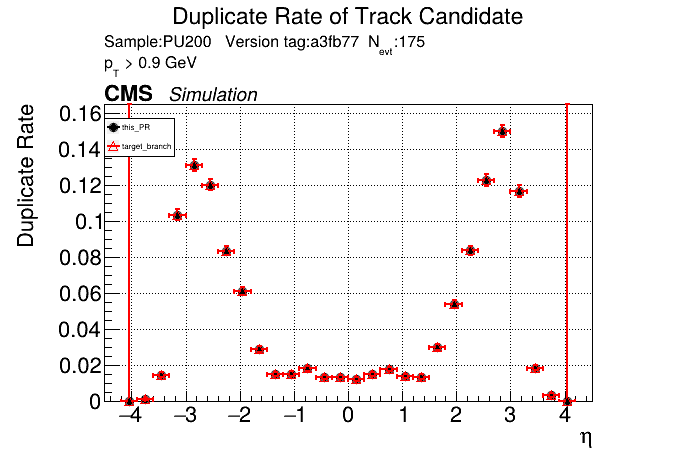
this almost worked with switching to |
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
|
I changed the target branch because I thought that the CI should work now that it uses the latest IB release, but I just noticed that it failed for another PR. I'll look into it. |
|
/run cmssw |
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
I'll change the CI so that it does the merge before checking out the packages |
|
There's going to have to be some (hopefully minor) rebasing now that my PR was merged into CMSSW. I'll update our master to see if there are conflicts. |
5 files with conflicts now |
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
Should I just rebase to master and fix the conflicts? Seems like the CMSSW run failed for reasons unrelated to this PR. |
a3fb77d to
aaa5e63
Compare
|
Just squashed the commits, will rebase now to fix the conflicts if that is fine. |
I'd rebase (to master or to SegmentLinking:ariostas/integration_pr_followups should work) |
aaa5e63 to
71b7485
Compare
|
There was a problem while building and running with CMSSW. The logs can be found here. |
|
/run cmssw |
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |

|
@slava77 Do you have any comments for this PR, or should I submit it to CMSSW? |
what's the plan with #147 ? I thought that you wanted that more or less together with this. |
|
I went through the changes and they look good to me |
I moved some arrays (the pLS hit indices and their delta phi) onto the GPU in the pixelSegments SoA but corrected this with a later update. I removed the edit from the PR description and just list the current total memory savings for 0.8 GeV at 100 events to be self-consistent.
I think it makes sense to merge this PR separately from #147. I think it's still unclear what the occupancies should be set to, and that will involve its own efficiency and memory changes. Therefore I think it's better to merge this in first before addressing the occupancy tuning in that PR. |
mostly for the purpose of the CMSSW PR, to have more clarity perhaps instead of "MDs are created" say "the MD container is instantiated". Our |
d9ef1f9 to
c7b126c
Compare
c7b126c to
2967c14
Compare
|
/run all |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
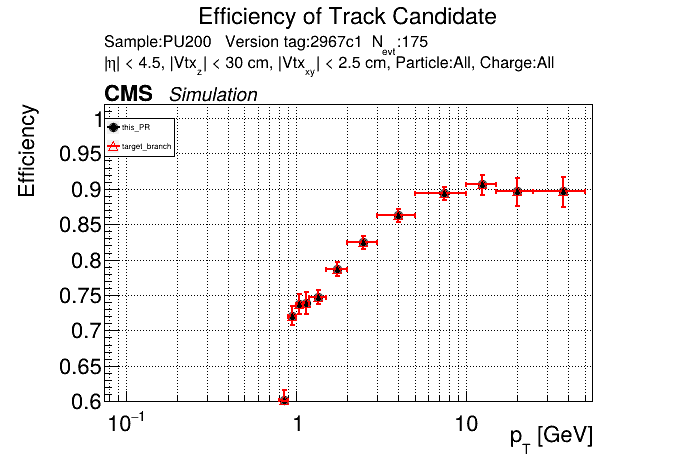
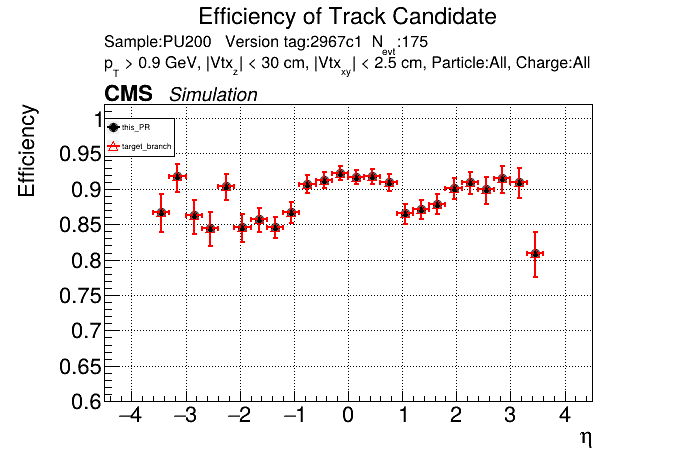
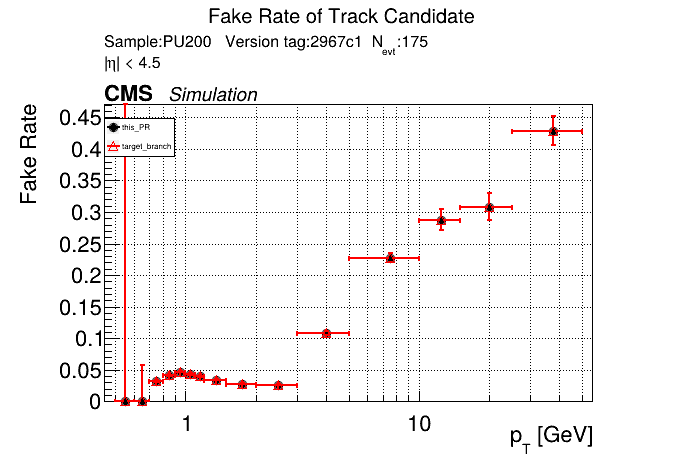
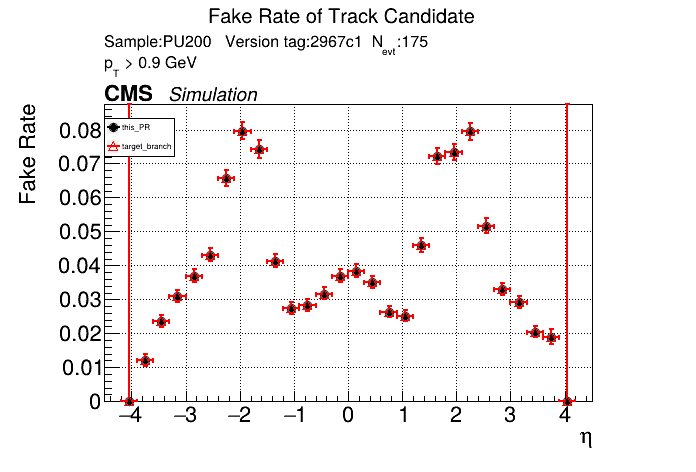
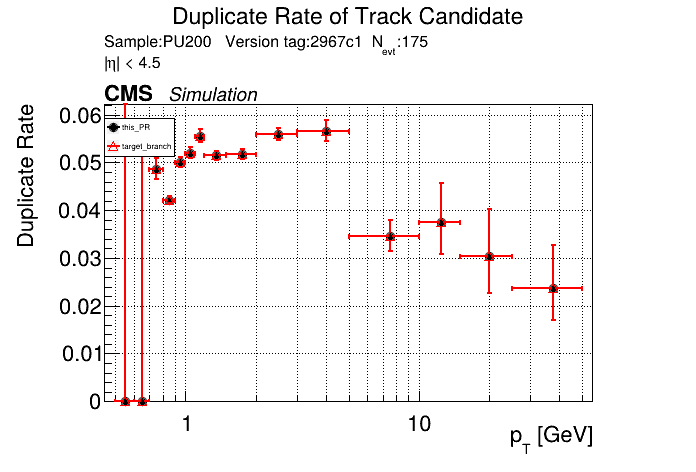
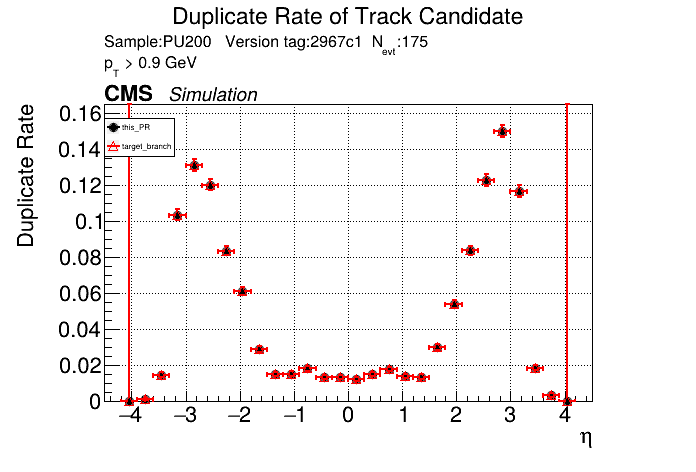
|
@GNiendorf |
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |

|
Working with IB releases definitely makes building the standalone part a bit more confusing. If we keep having to use IB builds we might need to tweak the Here's a timing comparison on cgpu-1. |
|
Thank you @ariostas! |
thank you; for the single-stream perhaps I should ignore the hits column |
Dynamic Memory Limits
I compute a dynamic max for each module that is the max possible number of objects that can be created given the number of lower level objects (so for example the number of possible T5's for a given module given the total number of T3's in modules where two T3's can be connected). This upper bound provides a large reduction in the occupancies. This is also accomplished with no new truncations, since this dynamic max represents the maximum number of possible objects that can be created.
For the segments, I had to rearrange the addPixelSegmentToEvent() function so that the segments container is instantiated after the MDs container is filled. Right now the segments object is instantiated during the pLS loading, which is done before the MDs container is filled.
Object Size Reduction
Reduction in object sizes (total occupancy basically) at current max occupancies (averaged over 10 events, 0.8 GeV):
Total Memory Decrease
For single stream, 100 events at current occupancies:
1695MiB -> 1275MiB (25% decrease, 0.8 GeV)