| Status | Accepted |
|---|---|
| RFC # | [#4] |
| Author(s) | Chanakya Ekbote (@Chanakya-Ekbote) |
| Sponsor | Yong Tang (@yongtang), Paul Greenberg (@greenpau) |
| Updated | 2020-05-13 |
| Obsoletes |
This project aims to try and detect anomalies that occur in a CoreDNS server using a machine learning model developed in Keras. This project would help automate the process of anomaly detection, and reduce the necessity to write anomaly detection 'rules'.
To detect whether an anomaly has occurred or not in a CoreDNS server, an engineer has to write specific 'rules'. If the data metrics follow those 'rules' they are classified as non - anomalies, however, if they violate these 'rules' they are classified as anomalies. Prometheus itself has these alerting rules.
The process of writing effective rules requires a lot of testing as well as experience in the field and moreover, it may so happen that the engineer may not include some edge cases that may give false positives or false negatives. In addition to that, these anomaly detection 'rules' are only written for specific anomalies and hence may not generalize to other anomalies. Therefore, it would make sense to model anomaly detection as a machine learning problem where the models could learn the relations between the metrics and the anomaly, which would then lead to a generalized anomaly detection solution. Moreover, this model can be continuously updated based on new training data, which leads to adaptability in the anomaly detection problem.
- At the end of the GSoC period, I would be delivering a Keras Model that would detect anomalies.
- This model would be packaged as a part of the class. The class would contain various functions which would make it easy for anyone to retrain and modify the Keras Model, even those who have no idea about TensorFlow/Keras syntaxes
- At the end of the project, we would have a huge collection of Prometheus data metrics which could also be used for someone else to train other models as well as develop better alerting 'rules'
To train a machine learning model, the main ingredient is data. The following methods allow us to garner data that could be used to train our machine learning model:
There are two methods through which we could collect data
-
Simulation of Data Traffic in a cluster: We could use simulation software that simulates Kubernetes clusters to obtain data metrics that correspond to non - anomalous data. The software that we can use is: k8s-cluster-simulator.
-
Collecting Data from a Production Server: We collect data metrics from a production server, and use that to train the Keras Model.
The data would be split as follows. 70% would be used for training, 15% for validation and 15% for testing.
There are three machine learning models that would be tried for this project. Depending on the results produced by the models as well as the evaluation metrics (as described in the next section), a single model will be shortlisted and submitted as a GSoC deliverable.
In this approach, we'd be assuming that the data metrics we collect from both, the simulation, as well as the production server, are devoid of anomalies.
A Convolutional Autoencoder is a machine learning model that is useful for compressing the information contained in the input data to a lower-dimensional latent vector. Such a structure is useful, as it helps discard the unnecessary information present in the input data. Moreover, it is easier to derive inferences regarding the input data while working with learned representations of lower dimensions as it captures only the information that is relevant for reconstructing the data.

The encoder is tasked with compressing the information into a lower dimension. The decoder makes sure that the latent vector correctly captures the information regarding the input data.
The loss function for the entire model is the mean squared error between the input and the output. The loss function is as follows:
Where, F(Xi) represents the output of the Autoencoder when the input data is Xi.
Since the data metrics are time dependant, a small modification would have to be done, to the input 'image' of the Convolutional Autoencoder. In our case, the time-dependent metrics would be stacked up as a FIFO stack and used as the input to the Autoencoder. The input to the FIFO stack is the latest data metric. The size of the FIFO stack is a hyperparameter and can be changed depending on the results obtained during training.
Inferences from the Model
Once the Autoencoder has been trained, the model will be tested on anomalous data metrics (these can be filtered out based on the 'rules' described in Prometheus). An L2 norm will be calculated between the mean of the latent representation of the anomaly free data metrics and the anomalous data metrics. The lowest L2 norm will be considered a threshold, and any latent vector whose distance from the mean that is greater than the threshold is considered to be derived from anomalous data.
Advantages
Such a method can be used to find patterns between different anomaly types. This can be done by using a K-Means Clustering Algorithm or SVM's.
Disadvantage
The optimization function doesn't reflect the fact that anomalous and non - anomalous data has to be separated. Hence, it may so happen that the machine learning model does not give the appropriate results, as the objective function is different from what we want to achieve.
References
Implementation Examples
This would be a simple Convolutional Classification Model that predicts whether the data metric corresponds to an anomaly or not. The model would be a binary classifier that predicts whether the data metrics correspond to an anomaly or not. The data that would be used is data from the production server as well as the simulation software.
Similar to the previous model, since the data metrics are time dependant, a small modification would have to be done, to the input 'image' of the Convolutional Autoencoder. In our case, the time-dependent metrics would be stacked up as a FIFO stack and used as the input to the Autoencoder. The input to the FIFO stack is the latest data metrics. The size of the FIFO stack is a hyperparameter and can be changed depending on the results obtained during training.
The model will look something similar to this:
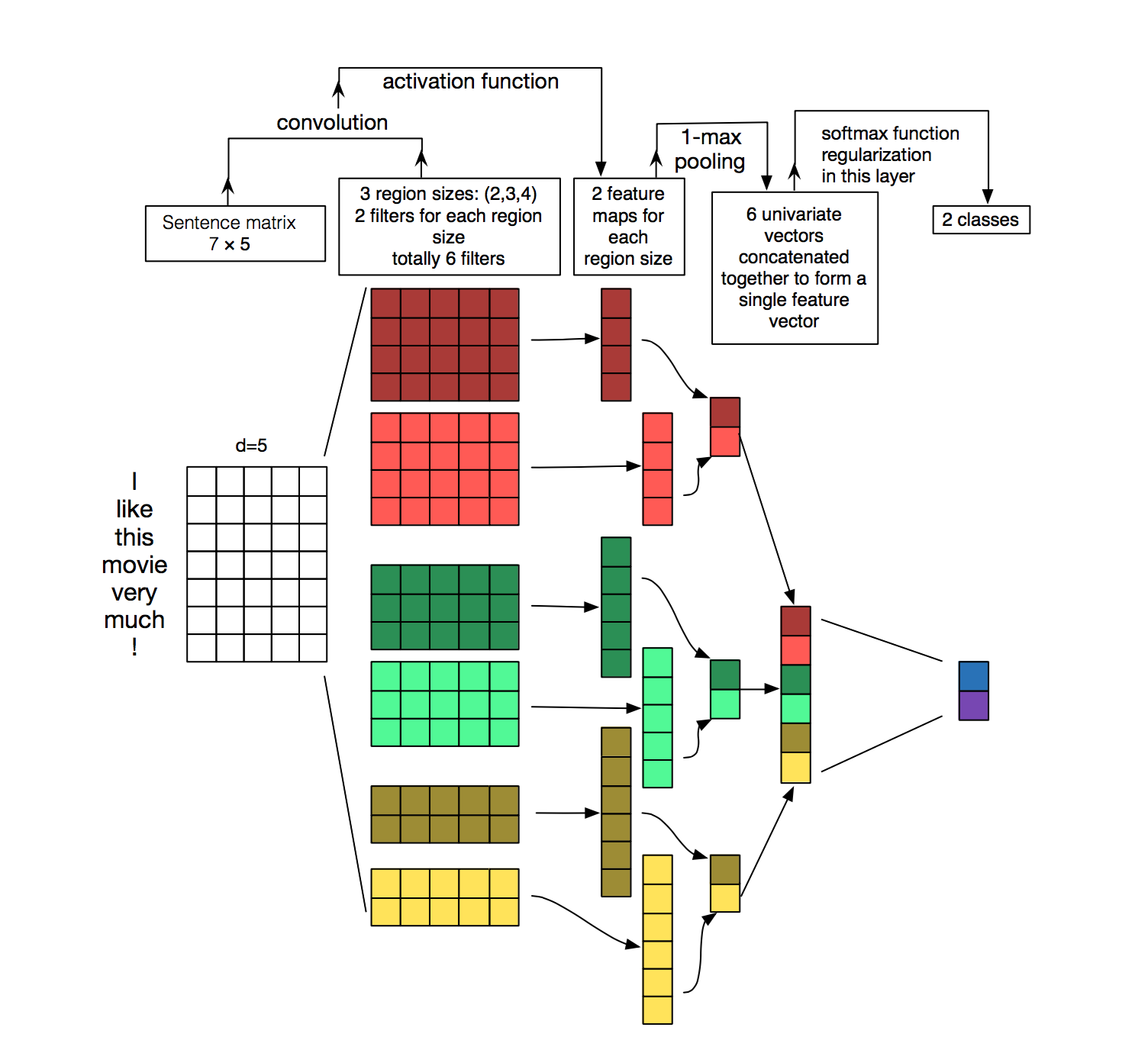
The loss function for the entire model would be the binary cross entropy loss. The loss function is as follows:
Here, Ylabel} gives the actual class of the data (whether it is an anomaly or not), and Ypred} is the predicted label (what the model classifies the data as).
Advantages
The optimization function is directly correlated to our objective. Hence, there is a higher chance of the model giving the right results.
Disadvantages
Since this model only checks whether the data metrics correspond to an anomaly or not, it is difficult to pinpoint what specific anomaly has been detected.
References
Implementation Examples
The main objective of this model is to make sure that the distance between the latent vectors of non - anomalous data is as small as possible, the distance between latent vectors of anomalous data metrics is as small as possible, and also that the distance between anomalous and non - anomalous data is as large as possible, which in turn creates a cluster of anomalous data metrics in latent space that is far apart from the cluster of non-anomalous data metrics in latent space,
Similar to the previous two models, the data that would be used is data from the production server as well as the simulation. Moreover, since the data metrics are time dependant, a small modification would have to be done, to the input 'image' of the Convolutional Autoencoder. In our case, the time-dependent metrics would be stacked up as a FIFO stack and used as the input to the Autoencoder. The input to the FIFO stack is the latest data metric. The size of the FIFO stack is a hyperparameter and can be changed depending on the results obtained during training.
The model will be similar to this:
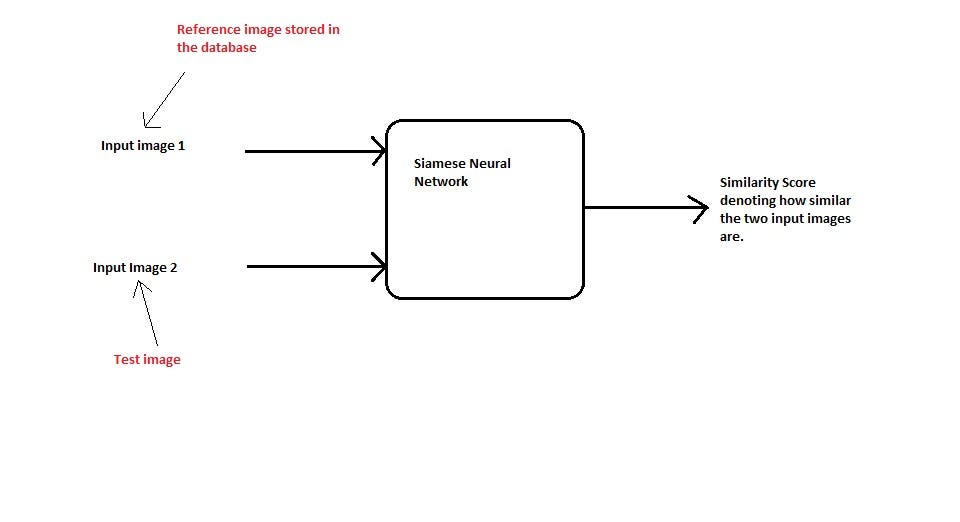
In a siamese network, a pair of images are fed into the same network. If the images belong to the same class, then the distance is minimised. Else the distance is maximised.
The loss function is as follows:
This loss function would minimise the distance if Yi is equal to 1 (data is of the same class) or maximise the distance if Yi is equal to 0 (the data is of different classes)
Inferences from the Model
To understand whether the data metrics correspond to anomalous or non - anomalous data, we will take the L2 norm between the latent vector representation of the data metric and the mean of the latent representation of the anomaly free data metrics as well as the mean of the latent representation of the anomalous data metrics. Whichever distance is smaller, that would be the class that the data metric is classified as.
Advantages
The optimization function is directly correlated to our objective. Hence, there is a higher chance of the model giving the right results.
Disadvantages
Since this model only checks whether the data metrics correspond to an anomaly or not, it is difficult to pinpoint what specific anomaly has been detected.
References
Implementation Examples
All three of these models would be trained and then depending on the results as well as the results of the evaluation parameters of the model, one of them would be shortlisted.
For each of these models the following metrics would be calculated:
-
Confusion Matrix: This is the matrix that gives an idea about the number of True Positives, True Negatives, False Positives and False Negatives.
-
Prescision : Precision is a metric that quantifies the number of correct positive predictions made. Therefore, Precision = TruePositives / (TruePositives + FalsePositives)
-
Recall: Recall is a metric that quantifies the number of correct positive predictions made out of all positive predictions that could have been made. Therefore, Recall = TruePositives / (TruePositives + FalseNegatives)
-
F Measure: F-Measure provides a way to combine both precisions and recall into a single measure that captures both properties. Therefore, F-Measure = (2 * Precision * Recall) / (Precision + Recall)
-
Results on testing data : Some classes (based on the rules) will not be used for training or validation. They will purely be used for testing purposes to know how the model would respond to never been seen before anomalous data.
Depending on these evaluation parameters the models would be retrained, and later on, a single model would be shortlisted from the three as a deliverable.
References
Given the fact that we’ll be working on tuning various models, tuning the hyperparameters manually is a cumbersome task. Hence, we’d be using a tool Talos. It helps in automating the process of hyperparameter tuning. Moreover, we would be using TensorBoard to visualize the results.
Retraining the model will be of prime importance as if the engineer observes some anomalous but the model predicts that no anomaly occurred. In that case, the engineer labels this data and then the model is retrained. This is applicalbe only for models 2 and 3.
The trained model would be packaged as a class. Moreover, the classes would contain functions (given below) that would make training and testing the model much easier, even if he/she has no prior knowledge about TensorFlow/Keras syntaxes. The functions are as follows:
def import_weights()
"""
Imports the trained weights
"""def initalize_new_weights()
"""
Initializes new weights to the network
""" def train(number_of_iterations, batch_size, data)
"""
Trains the network depending on certain hyperparameters
"""
# Args:
# number_of_iterations: determines the number of iterations
# the model trains for
# batch_size: determines the batch size
# data: the data on which the model trains def predict(data)
"""
Predicts the class of the data
"""
# Args:
# data: the data on which the model has to predictMore functions will be added on further discussion.
Before 1st May:
I will go through the required DNS concepts as well as the essential features of Prometheus.
1st May to 31st May:
I will communicate with the CoreDNS community and participate in any interesting discussion that comes up. I will further finalize the ideas regarding the project by corresponding with the mentors as well as the members of the community.
1st June to 14th June:
In this period, data collection will be the main priority. Data would be collected from the simulation software. Moreover, a production server would be created (if it's not readily available), and the data would be collected from the same. In addition to that, the data will be filtered and preprocessed for training for the three machine learning models
15th June to 24th June:
The first model will be created and training for the same will begin. Note that training will encompass hyperparameter tuning using Talos.
25th June to 4th July:
The second model will be created and training for the same will begin. Note that training will encompass hyperparameter tuning using Talos.
5th July to 14th July:
The third model will be created and training for the same will begin. Note that training will encompass hyperparameter tuning using Talos.
15 July to 26th July:
The results are compiled in this section and discussed further with the mentors. The models are then retrained depending on mentor feedback as well as the results obtained.
27th July to 23rd August:
The results are again compiled and then a model is shortlisted. The model is then packaged as a class and documentation is provided for the same.
24th to 30th August:
Period to account for any unforeseen delays.
- Should I create a classification model that can also detect what type of anomaly it is? This can be created as an extension on top of the previous models.