| marp | theme | title | math |
|---|---|---|---|
true |
gaia |
数据中心技术、计算机系统设计 |
mathjax |
施展 武汉光电国家研究中心 光电信息存储研究部
https://shizhan.github.io/ https://shi_zhan.gitee.io/
- 云服务背景
- 对系统的挑战
- 对系统设计的影响
- for (云应用的需求):
- 新的挑战
- 对系统的探索
<style scoped> h2 { padding-top: 500px; font-size: 72px; text-align: center; color: #F0F0F0; } p { font-size: 18px; } </style>

https://www.corporatecomplianceinsights.com/data-data-data-everywhere/
<style scoped> p { font-size: 20px; text-align: right; } </style>

Source: https://www.datanami.com/2018/11/27/global-datasphere-to-hit-175-zettabytes-by-2025-idc-says/

<style scoped> p { font-size: 20px; text-align: center; } </style>

Source: https://www.smartinsights.com/internet-marketing-statistics/happens-online-60-seconds/
<style scoped> p { padding-top: 100px; text-align: center; font-size: 72px; } </style>
扩展
<style scoped> th { font-size: 36px; } tr { font-size: 16px; vertical-align: bottom; } </style>
| 规模 | 种类 |
|---|---|
 |
 |
| Source: http://sancluster.com/scale-out-file-system/ | Source: http://storagegaga.com/the-future-is-intelligent-objects/ |
<style scoped> th { font-size: 36px; } tr { font-size: 30px; vertical-align: bottom; } </style>
| 规模 | 种类 |
|---|---|
|
|
| 检索地址 | 区分内容 |
<style scoped> p { font-size: 25px; text-align: right; } </style>
- Object storage originated in the late 1990s:
- Seagate specifications from 1999
- Dr. Garth Gibson, CMU & NASD project
- High-bandwidth, Low-latency, Scalable Storage Systems
- File Server Scaling with Network-Attached Secure Disks (NASD), 1997

Source: https://www.snia.org/educational-library/object-storage-what-how-and-why-2020
<style scoped> p { text-align: center; } </style>
 Source: https://usdc.vn/object-storage-vs-traditional-storage/
Source: https://usdc.vn/object-storage-vs-traditional-storage/
<style scoped> p { text-align: center; } </style>
 Source: https://www.ibm.com/cloud/learn/object-storage
Source: https://www.ibm.com/cloud/learn/object-storage
<style scoped> p { text-align: center; } tr { font-size: 25px; } </style>
| Object | File | Block | Archive |
|---|---|---|---|
| Object Storage | NAS | SAN | Tape |
| Videos, photos serving streaming | All kinds of file | Attach to server | The file needs to be saved permanently |
| Read (download) data regularly | Read data regularly, install as a network drive | Run data directly on Storage | Rarely to download |
| High upload / download speed | High upload / download speed | Very High upload / download speed | High upload speed, slow download |
| Use with CDN | Many usage scenarios | Use with server (VM) | Use independently |
Source: https://usdc.vn/object-storage-vs-traditional-storage/
- What is Object Storage?
- Object Storage is a method of storing and subsequently retrieving sets of data as collections of single, uniquely identifiable indivisible items or objects. It applies to any forms of data that can be wrapped up and managed as an object.
- Objects are treated as an atomic unit. There is no structure corresponding to a hierarchy of directories in a file system; each object is uniquely identified in the system by a unique object identifier.
- What is Object Storage?
- When you create an object on this type of storage, the entire set of data is handled and processed without regard to what sub-parts it may have.
- When reading from object storage, you can read either the whole object, or ask to read parts of it.
- There is often no capability to update to the object or parts of the object; the entire object is usually required to be re-written.
- Most object storage allows for objects to be deleted.
- What is Object Storage?
- Object storage often supports meta-data.
- This is data that is part of the object, but that is in addition to the object ID and the data.
- It is often expressed as an attribute-value pair; for instance, an attribute of COLOR in our collection of objects may have the value RED for some objects and BLUE for others.
- These permit collections of objects, individually addressable by their object ID, to be searched, filtered and read in groups without needing to know the specific object IDs.
- Object storage often supports meta-data.
- Storage Networking Industry Association - SNIA
- Object Storage: What, How and Why, 2020
- Object storage, as a definition, can be: A storage system that manages and manipulates data storage as distinct units, called objects
- CDMI Cloud Storage Standard, 2.0a, 2020
- The Cloud Data Management Interface (CDMI) defines the functional interface that applications will use to create, retrieve, update and delete data elements from the Cloud.
- Object Storage: What, How and Why, 2020
<style scoped> p { font-size: 18px; padding-top: 620px; } </style>




<style scoped> p { font-size: 18px; padding-top: 620px; } </style>

Source: What are Restful Web Services
<style scoped> p { font-size: 18px; text-align: center; } li { font-size: 25px; text-align: left; } </style>
- GET on the API's root resource to list all of the Amazon S3 buckets of a caller.
- GET on a Folder resource to view a list of all of the objects in an Amazon S3 bucket.
- PUT on a Folder resource to add a bucket to Amazon S3.
- DELETE on a Folder resource to remove a bucket from Amazon S3.
- GET on a Folder/Item resource to view or download an object from an Amazon S3 bucket.
- PUT on a Folder/Item resource to upload an object to an Amazon S3 bucket.
- HEAD on a Folder/Item resource to get object metadata in an Amazon S3 bucket.
- DELETE on a Folder/Item resource to remove an object from an Amazon S3 bucket.
<style scoped> li, p { font-size: 18px; } </style>
To access the object-based storage system:
- secret-access-key and access-key-id – private/public pair of keys that you can generate using different tools or sometimes directly on the provider dashboard
- endpoint – the web address of the space
const AWS = require("aws-sdk");
const s3 = new AWS.S3({
endpoint: "provider-space-endpoint",
secretAccessKey: "my-secret-key",
accessKeyId: "my-access-key",
});
- https://lakefs.io/object-storage/
- https://docs.aws.amazon.com/apigateway/latest/developerguide/integrating-api-with-aws-services-s3.html
<style scoped> p { font-size: 20px; color: #F0F0F0; text-align: right; } </style>

Source: https://aws.amazon.com/cn/s3/storage-classes/
<style scoped> p { font-size: 18px; text-align: center; } </style>

Source: https://www.cloudhealthtech.com/blog/aws-cost-optimization-s3-storage-class
<style scoped> h2 { text-align: center; } </style>

<style scoped> h2, p { text-align: center; } </style>
 主动对象海量存储系统及关键技术
主动对象海量存储系统及关键技术
<style scoped> p { font-size: 18px; padding-top: 520px; } </style>


Source: https://www.snia.org/computationaltwg, https://www.snia.org/education/what-is-computational-storage
- Computational Storage is defined as architectures that provide Computational Storage Functions (CSF) coupled to storage, offloading host processing or reducing data movement.
- These architectures enable improvements in application performance and/or infrastructure efficiency through the integration of compute resources (outside of the traditional compute & memory architecture) either directly with storage or between the host and the storage.
<style scoped> h2 { padding-top: 200px; text-align: center; font-size: 70px; } </style>
- Amazon S3: Amazon S3 stores data as objects within resources called “buckets.” AWS S3 offers features like 99.999999999% durability, cross-region replication, event notifications, versioning, encryption, and flexible storage options (redundant and standard).
- Rackspace Cloud Files: Cloud Files provides online object storage for files and media. Cloud Files writes each file to three storage disks on separate nodes that have dual power supplies. All traffic between your application and Cloud Files uses SSL to establish a secure, encrypted channel. You can host static websites (for example: blogs, brochure sites, small company sites) entirely from Cloud Files with a global CDN.
- Azure Blob Storage: For users with large amounts of unstructured data to store in the cloud, Blob storage offers a cost-effective and scalable solution. Every blob is organized into a container with up to a 500 TB storage account capacity limit.
- Google cloud storage: Cloud Storage allows you to store data in Google’s cloud. Google Cloud Storage supports individual objects that are terabytes in size. It also supports a large number of buckets per account. Google Cloud Storage provides strong read-after-write consistency for all upload and delete operations. Two types of storage class are available: Standard Storage class and Storage Near line class (with Near Line being MUCH cheaper).
https://cloudacademy.com/blog/object-storage-block-storage/
- 阿里云对象存储OSS(Object Storage Service)是一款海量、安全、低成本、高可靠的云存储服务,提供99.9999999999%(12个9)的数据持久性,99.995%的数据可用性。多种存储类型供选择,全面优化存储成本。
- 腾讯对象存储(Cloud Object Storage,COS)是腾讯云提供的一种存储海量文件的分布式存储服务,具有高扩展性、低成本、可靠安全等优点。通过控制台、API、SDK 和工具等多样化方式,用户可简单、快速地接入 COS,进行多格式文件的上传、下载和管理,实现海量数据存储和管理。
- 华为对象存储服务(Object Storage Service)是一款稳定、安全、高效、易用的云存储服务,具备标准Restful API接口,可存储任意数量和形式的非结构化数据。
<style scoped> p { font-size: 16px; text-align: right; } </style>
- OpenStack was created during the first months of 2010. Rackspace wanted to rewrite the infrastructure code running its Cloud servers offering, and considered open sourcing the existing Cloud files code. At the same time, Anso Labs (contracting for NASA) had published beta code for Nova, a Python-based “cloud computing fabric controller”.
- Both efforts converged and formed the base for OpenStack. The first Design Summit was held in Austin, TX on July 13-14, 2010, and the project was officially announced at OSCON in Portland, OR, on July 21st, 2010.
https://docs.openstack.org/project-team-guide/introduction.html
- OpenStack Object Storage (swift) is used for redundant, scalable data storage using clusters of standardized servers to store petabytes of accessible data.
- Swift uses a distributed architecture with no central point of control, providing greater scalability, redundancy, and performance.
- Storage clusters scale horizontally by adding new nodes, uses software logic to ensure data replication and distribution across different devices, inexpensive commodity hard drives and servers.
<style scoped> p { font-size: 20px; text-align: right; } </style>
https://docs.openstack.org/swift/ https://github.com/openstack/swift Source: https://docs.openstack.org/security-guide/object-storage.html

<style scoped> li { font-size: 30px } p { font-size: 20px; text-align: right; } </style>
- Ceph was developed at University of California, Santa Cruz, by Sage Weil in 2003 as a part of his PhD project.
- The initial project prototype was the Ceph filesystem, written in approximately 40,000 lines of C++ code, which was made open source in 2006 under LGPL to serve as a reference implementation and research platform.
- LLNL supported Sage's initial research work.
- The period from 2003 to 2007 was the research period of Ceph. By this time, its core components were emerging, and the community contribution to the project had begun at pace.
- Ceph uniquely delivers object, block, and file storage in one unified system.
- Ceph is highly reliable, easy to manage, and free.
- Ceph delivers extraordinary scalability–thousands of clients accessing petabytes to exabytes of data.
- A Ceph Node leverages commodity hardware and intelligent daemons, and a Ceph Storage Cluster accommodates large numbers of nodes, which communicate with each other to replicate and redistribute data dynamically.
<style scoped> p { font-size: 20px; text-align: right; } </style>
https://ceph.io/ https://github.com/ceph/ceph Source: https://icicimov.github.io/blog/images/CEPH-graphic.png
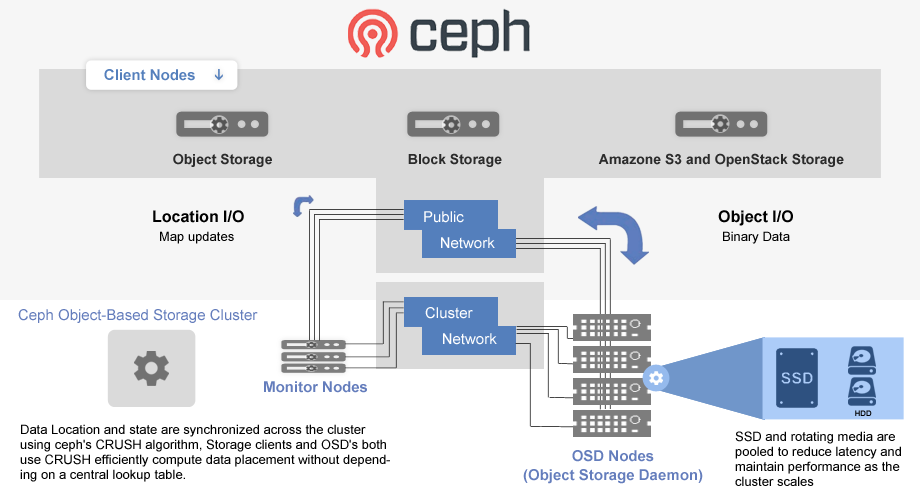{kind=link}

<style scoped> p { padding-top: 620px; font-size: 20px; } </style>

Source: Ceph Documentation » Architecture
<style scoped> p { padding-top: 620px; font-size: 20px; } </style>

Source: Ceph storage on Ubuntu: An overview


- MinIO is a High Performance Object Storage released under GNU Affero General Public License v3.0.
- It is API compatible with Amazon S3 cloud storage service.
- Standalone MinIO servers are best suited for early development and evaluation.
- Certain features such as versioning, object locking, and bucket replication require distributed deploying MinIO with Erasure Coding.
<style scoped> p { font-size: 20px; text-align: right; } </style>
https://min.io/ http://www.minio.org.cn/ https://github.com/minio/minio
Source: http://www.minio.org.cn/static/picture/architecture_diagram.svg
{kind=link}

<style scoped> p { padding-top: 100px; text-align: center; font-size: 72px; } </style>
长尾

长尾(The Long Tail)这一概念是由《连线》杂志主编Chris Anderson在2004年10月的“长尾”一文中最早提出,用来描述诸如亚马逊和Netflix之类网站的商业和经济模式。
实际上是统计学中幂律(Power Laws)和帕累托分布(Pareto distributions)特征的一个口语化表达。
规模化业务中,“尾部”产生的总体效益甚至会超过“头部”。
- 冷门商品的销售量可以达到总额的半数
- 自然语言中的中低频词对信息量的贡献
- ...
<style scoped> p { padding-top: 600px; text-align: center; font-size: 18px; color: 0040FF; } </style>

https://newmedia.fandom.com/wiki/The_Long_Tail
<style scoped> p { padding-top: 200px; text-align: center; font-size: 72px; color: 0040FF; } </style>

系统以规模扩展应对需求增长
<style scoped> p { padding-top: 200px; text-align: center; font-size: 72px; color: 0040FF; } </style>


那么代价是?




<style scoped> p { padding-top: 200px; text-align: center; font-size: 72px; color: 0040FF; } </style>
唯一不变的是变化本身
毫末之变、扩展之鉴
- 大系统由小组件汇聚而成
- 汇聚改变的不仅仅是规模
- 还有伴随组件而来的变化


<style scoped> p { font-size: 20px; text-align: left; } </style>

- 必受各组件状态的影响
- 设备故障 Fail
- 性能波动 Tail
Source: https://nutrien-ekonomics.com/latest-fertilizer-research/liebigs-law-of-the-minimum/
<style scoped> p { font-size: 16px; text-align: center; } </style>
- 必受各组件状态的影响
- 设备故障——需要 Fault-Tolerant 容错!

- 必受各组件状态的影响
- 设备故障——需要 Fault-Tolerant 容错!
- 性能波动——需要 Tail-Tolerant 容滞?

<style scoped> p { padding-top: 620px; font-size: 20px; } </style>

Source: https://bravenewgeek.com/everything-you-know-about-latency-is-wrong/

- Everything You Know About Latency Is Wrong
- 中译版
- 小概率事件不能忽视
- 延迟可能"被平均"

- Everything You Know About Latency Is Wrong
- 中译版
- 小概率事件不能忽视
- 延迟可能"被平均"
- 任务可能被拖累

<style scoped> p { font-size: 20px; text-align: center; } </style>

https://blog.bramp.net/post/2018/01/16/measuring-percentile-latency/
- 必受各组件状态的影响
- 设备故障——容错——提供冗余部件 (回顾计算机系统结构课…)
- 性能波动——容滞——?


- 必受各组件状态的影响
- 设备故障——容错——提供冗余部件
- 性能波动——容滞——执行冗余操作


- SNIA: Avoiding tail latency by failing IO operations on purpose
- One of these initiatives is adding a per I/O tag that indicates whether a drive can fail fast and return an error if it takes too long to retrieve the data.
- If there’s a replica of the data somewhere else, it might just be faster to retrieve the data from there, instead of waiting for the slow drive to respond.
- The other side of the coin is a “try really hard” I/O tag, that indicates you’ve exhausted all other options and really need the data from this drive.
<style scoped> li { font-size: 25px; } p { font-size: 16px; text-align: right; } </style>
- 对冲请求 Hedged Request
- Issue the same request to multiple replicas and use the results from whichever replica responds first.
- "hedged" - a client first sends one request to the replica believed to be the most appropriate, but then falls back on sending a secondary request after some brief delay.
- The client cancels remaining outstanding requests once the first result is received.
- 关联请求 Tied Request
- The hedged-requests technique also has a window of vulnerability in which multiple servers can execute the same request unnecessarily.
- Can be capped by waiting for the P95 expected latency before issuing the hedged request, but limits the benefits to only a small fraction of requests.
- Permitting more aggressive use of hedged requests with moderate resource consumption requires faster cancellation of requests.
- The hedged-requests technique also has a window of vulnerability in which multiple servers can execute the same request unnecessarily.
The Tail at Scale, CACM 2013.
<style scoped> p { font-size: 16px; text-align: right; } </style>
- HDFS (2.4+)
- If a read from a block is slow, start up another parallel, 'hedged' read against a different block replica.
- We then take the result of which ever read returns first (the outstanding read is cancelled).
- This 'hedged' read feature will help rein in the outliers, the odd read that takes a long time because it hit a bad patch on the disc, etc.
<style scoped> p { font-size: 16px; text-align: right; } </style>
- mongodb (4.4+)
- With hedged reads, the mongos instances can route read operations to two replica set members per each queried shard and return results from the first respondent per shard.
- The additional read sent to hedge the read operation uses the maxTimeMS value of maxTimeMSForHedgedReads.
https://docs.mongodb.com/manual/core/read-preference-hedge-option/
<style scoped> th { font-size: 25px; } td { font-size: 25px; } </style>
| Host:X.X.X.X | 3 副本Switch Read | 2 副本 Hedged Read | 3 副本 Hedged Read | 3 副本 Fast Switch Read(优化) |
|---|---|---|---|---|
| 读取时长 p999 | 977 ms | 549 ms | 192 ms | 128 ms |
| 最长读取时间 | 300 s | 125 s | 60 s | 15.5 s |
| 长尾出现次数(大于 500ms) | 238 次/天 | 75 次/天 | 15 次/天 | 3 次/天 |
| 长尾出现次数(大于 1000ms) | 196 次/天 | 64 次/天 | 6 次/天 | 3 次/天 |
- 优化:根据当前的读取状况动态地调整阈值,动态改变时间窗口的长度以及吞吐量阈值的大小。
- 实验说明
- 实验内容
- 熟悉性能指标:吞吐率、带宽、延迟
- 分析不同负载下的指标、延迟的分布
- 观测尾延迟现象
- 尝试对冲请求方案
<style scoped> p { padding-top: 100px; text-align: center; font-size: 72px; } </style>
预测
- 容错的代价
- …
- …
- …
- …
- 容滞的代价
- …
- …
- …
- …
- 容错的代价
- 浪费的空间
- …
- …
- 浪费的空间
- 容滞的代价
- 浪费的吞吐
- …
- …
- 浪费的吞吐
- 容错的代价
- 浪费的空间
- 从副本到纠删码、动态重编码
- …
- 浪费的空间
- 容滞的代价
- 浪费的吞吐
- 积极对冲加剧拥塞
- …
- 浪费的吞吐
- 容错的代价
- 浪费的空间
- 从副本到纠删码、动态重编码
- 故障预测
- 浪费的空间
- 容滞的代价
- 浪费的吞吐
- 积极对冲加剧拥塞
- 性能预测
- 浪费的吞吐
<style scoped> li { font-size: 25px; } </style>

- 故障预前处理优于故障事后处理
- 数据不丢失、服务不中断、不降级
- 处理开销小、处理时间充足易于分摊开销
- 故障后处理(数据冗余策略的部署)是保底机制
- 故障预测模型的检测率难以达到100%,存在故障漏报现象
- 预测到故障的存储设备已经出现数据丢失或出错
- 能够处理更多种类的异常情况,如软件错误、网络异常等

<style scoped> li { font-size: 25px; } </style>
- 副本和纠删码动态转换
- Non-Sequential Striping for Distributed Storage Systems with Different Redundancy Schemes, ICPP 2017.
- Non-sequential Striping Encoder from Replication to Erasure Coding for Distributed Storage System, Frontiers of Computer Science (FCS), 2019.
- 磁盘故障预测



<style scoped> li { font-size: 25px; } </style>
- Understanding the latency distribution of cloud object storage systems, JPDC 2019.
- Predicting Response Latency Percentiles for Cloud Object Storage Systems, ICPP 2017.

<style scoped> li { font-size: 20px; } </style>
- Tail Latency in Datacenter Networks, MASCOTS 2020.
- A Black-Box Fork-Join Latency Prediction Model for Data-Intensive Applications, TPDS 2020.
- The Fast and The Frugal: Tail Latency Aware Provisioning for Coping with Load Variations, WWW 2020.
- Managing Tail Latency in Datacenter-Scale File Systems Under Production Constraints, EuroSys 2019.
- Amdahl's Law for Tail Latency, CACM 2018.
- The Tail at Scale: How to Predict It?, HotCloud 16.
- The Tail at Scale, CACM 2013.