-
Notifications
You must be signed in to change notification settings - Fork 0
/
Copy pathstatistical_models_20191127_152_chang.Rmd
373 lines (285 loc) · 16.8 KB
/
statistical_models_20191127_152_chang.Rmd
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
---
title: "R Notebook"
output: html_notebook
---
# Chapter 16 Statistical models
In this chapter we will demonstrate how poll aggregators collected and combined data reported by different experts to produce improved predictions. We will introduce ideas behind the statistical models, also known as __probability models__.
## 16.1 Poll aggregators
We will use a Monte Carlo simulation to illustrate the insight Mr. Silver(Nate Silver in FiveThirtyEight) had and others missed. To do this, we generate results for 12 polls taken the week before the election. We mimic sample sizes from actual polls and construct and report 95% confidence intervals for each of the 12 polls. We save the results from this simulation in a data frame and add a poll ID column.
```{r}
library(tidyverse)
library(dslabs)
d<-0.039
Ns<-c(1298, 533, 1342, 897, 774, 254, 812, 324, 1291, 1056, 2172, 516)
p<-(d+1)/2
polls<-map_df(Ns, function(N){
x<-sample(c(0,1), size = N, replace = TRUE, prob = c(1-p,p))
x_hat<-mean(x)
se_hat<-sqrt(x_hat*(1-x_hat)/N)
list(estimate=2*x_hat-1,
low=2*(x_hat - 1.96*se_hat)-1,
high=2*(x_hat + 1.96*se_hat)-1,
sample_size=N)
}) %>% mutate(poll=seq_along(Ns))
```
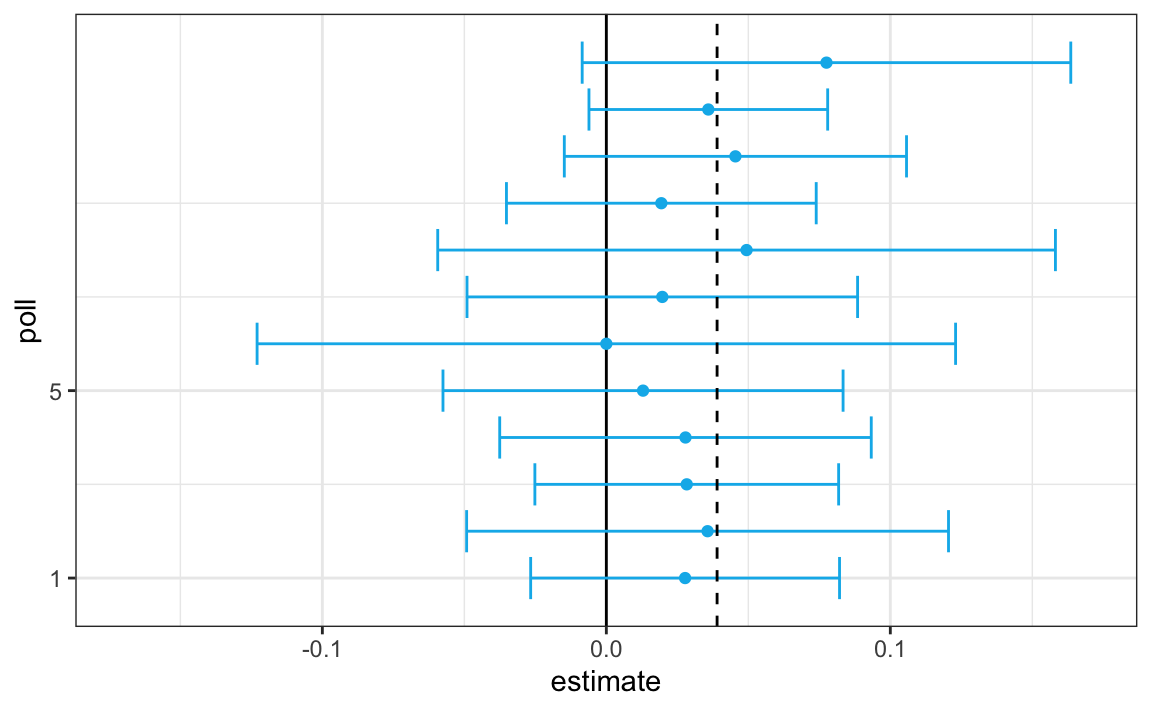
It is a visualization showing the intervals the pollsters would have reported for the difference between Obama and Romney. All 12 polls report confidence intervals that include the election night result (dashed line) and also include 0 (solid black line) as well.
Nate Silver realized that by combining the results of different polls you could greatly improve precision. By doing this, we are effectively conducting a poll with a huge sample size. We can therefore report a smaller 95% confidence interval and a more precise prediction.
Although as aggregators we do not have access to the raw poll data, we can use mathematics to reconstruct what we would have obtained had we made one large poll with:
```{r}
sum(polls$sample_size)
```
participants. Basically, we construct an estimate of the spread, let’s call it d, with a weighted average in the following way:
```{r}
d_hat<-polls %>%
summarize(avg=sum(estimate*sample_size)/sum(sample_size)) %>%
pull(avg)
```
Once we do this, we see that our margin of error is 0.018.
Thus, we can predict that the spread will be 3.1 plus or minus 1.8, which not only includes the actual result we eventually observed on election night, but is quite far from including 0. Once we combine the 12 polls, we become quite certain that Obama will win the popular vote.
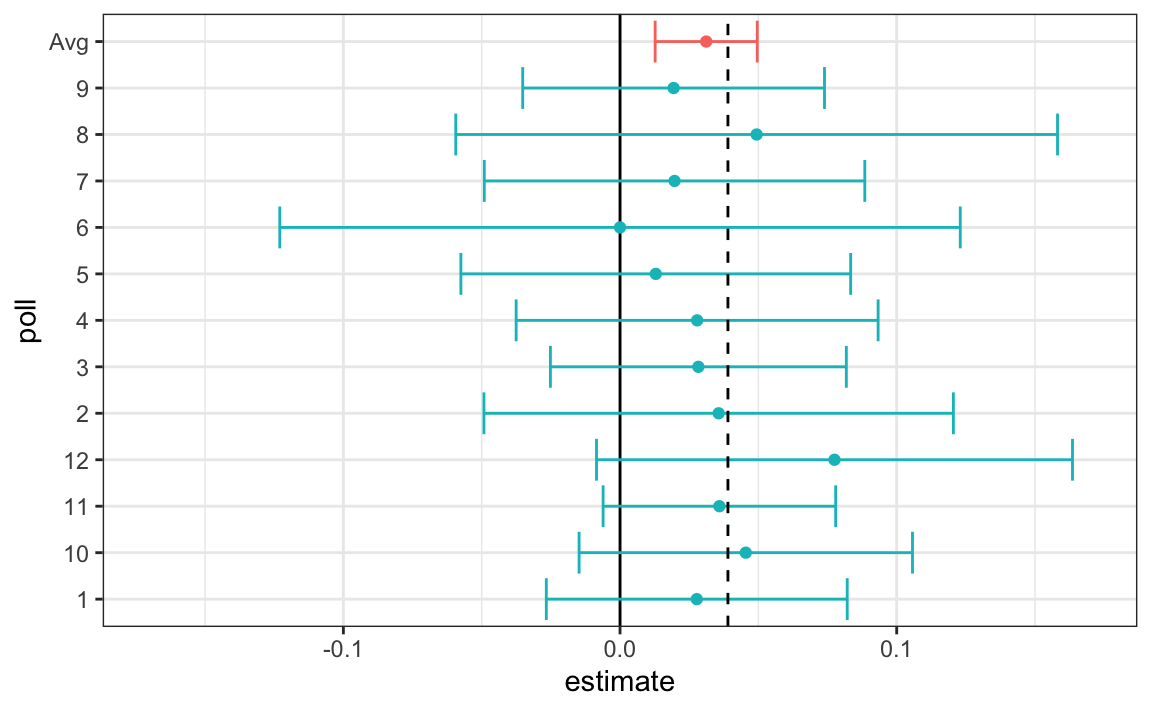
Of course, this was just a simulation to illustrate the idea. The actual data science exercise of forecasting elections is much more complicated and it involves modeling.
Since the 2008 elections, other organizations have started their own election forecasting group that uses statistical models to make predictions.
In 2016, forecasters underestimated Trump’s chances of winning greatly. In fact, four days before the election FiveThirtyEight published an article titled Trump Is Just A Normal Polling Error Behind Clinton.
FiveThirtyEight predicted a 3.6% advantage for Clinton, included the actual result of 2.1% (48.2% to 46.1%) in their interval, and was much more confident about Clinton winning the election, giving her an 81.4% chance. Their prediction was summarized with a chart like this:
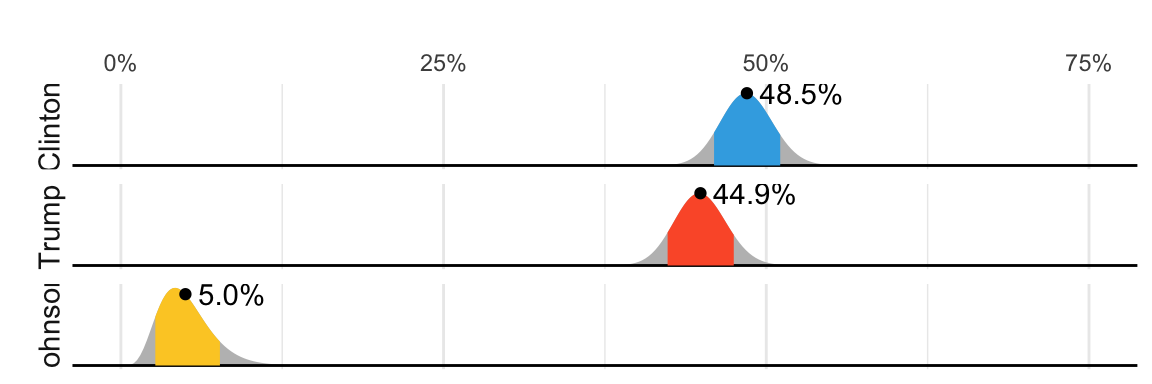
The colored areas represent values with an 80% chance of including the actual result, according to the FiveThirtyEight model.
We introduce actual data from the 2016 US presidential election to show how models are motivated and built to produce these predictions. To understand the “81.4% chance” statement we need to describe Bayesian statistics.
### 16.1.1 Poll data
We use public polling data organized by FiveThirtyEight for the 2016 presidential election. The data is included as part of the dslabs package:
```{r}
data("polls_us_election_2016")
```
The table includes results for national polls, as well as state polls, taken during the year prior to the election. For this first example, we will filter the data to include national polls conducted during the week before the election. We also remove polls that FiveThirtyEight has determined not to be reliable and graded with a “B” or less. Some polls have not been graded and we include those:
```{r}
polls<-polls_us_election_2016 %>%
filter(state =="U.S." & enddate >= "2016-10-31" & (grade %in% c("A+", "A", "A-", "B+") | is.na(grade)))
```
We add a spread estimate:
```{r}
polls<-polls %>%
mutate(spread =rawpoll_clinton/100 - rawpoll_trump/100)
```
For this example, we will assume that there are only two parties and call p the proportion voting for Clinton and 1−p the proportion voting for Trump. We are interested in the spread 2p−1. Let’s call the spread d(for difference).
We have 49 estimates of the spread. The theory we learned tells us that these estimates are a random variable with a probability distribution that is approximately normal.
expected value :velection night spread d
standard error : $2\sqrt{p(1-p)/N}$
Assuming the urn model we described earlier is a good one, we can use this information to construct a confidence interval based on the aggregated data. The estimated spread is:
```{r}
d_hat<-polls %>%
summarize(d_hat=sum(spread*samplesize) / sum(samplesize)) %>%
pull(d_hat)
d_hat
```
and the standard error is:
```{r}
p_hat<-(d_hat+1)/2
moe<-1.96*2*sqrt(p_hat*(1-p_hat)/sum(polls$samplesize))
moe
```
So we report a spread of 1.43% with a margin of error of 0.66%. On election night, we discover that the actual percentage was 2.1%, which is outside a 95% confidence interval. What happened?
A histogram of the reported spreads shows a problem:
```{r}
library(ggplot2)
polls %>%
ggplot(aes(spread)) +
geom_histogram(color="black", binwidth = .01)
```
The data does not appear to be normally distributed and the standard error appears to be larger than 0.007. The theory is not quite working here.
### 16.1.2 Pollster bias
Notice that various pollsters are involved and some are taking several polls a week:
```{r}
polls %>% group_by(pollster) %>% summarize(n())
```
Let’s visualize the data for the pollsters that are regularly polling:
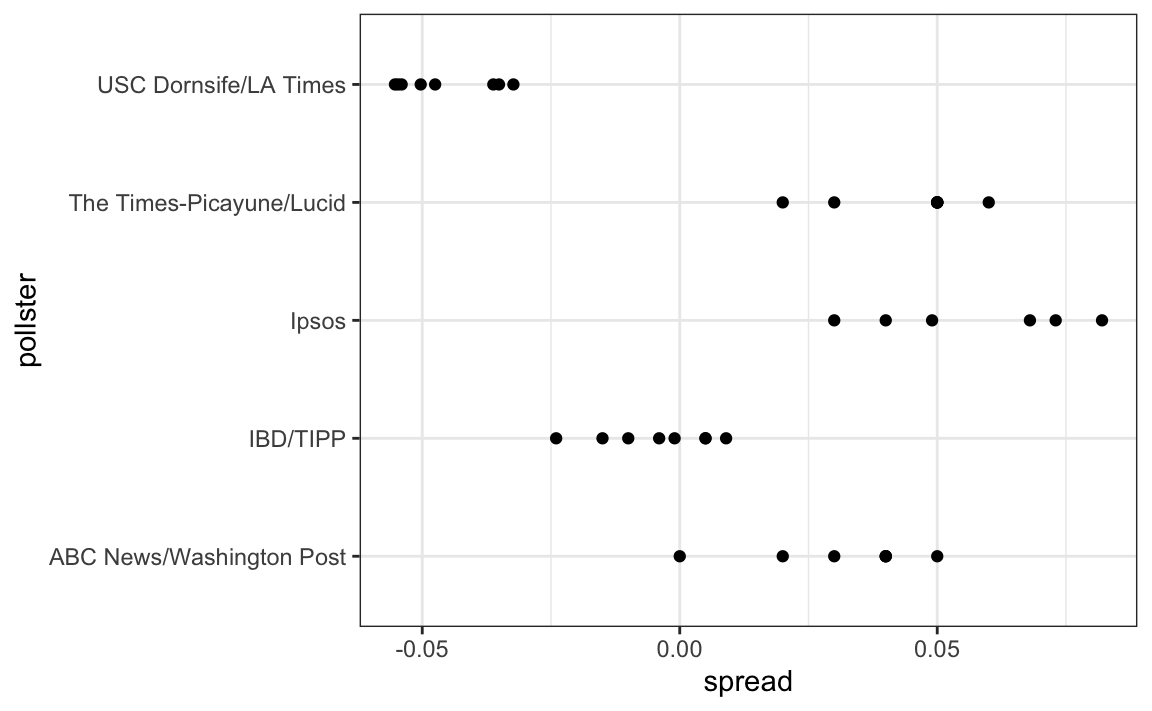
This plot reveals an unexpected result. First, consider that the standard error predicted by theory for each poll:
```{r}
polls %>% group_by(pollster) %>%
filter(n() >= 6) %>%
summarize(se=2*sqrt(p_hat*(1-p_hat) / median(samplesize)))
```
is between 0.018 and 0.033, which agrees with the within poll variation we see. However, there appears to be differences across the polls. FiveThirtyEight refers to these differences as “house effects”. We also call them pollster bias.
## 16.2 Data-driven models
For each pollster, let’s collect their last reported result before the election:
```{r}
one_poll_per_pollster <-polls %>% group_by(pollster) %>%
filter(enddate == max(enddate)) %>%
ungroup()
```
Here is a histogram of the data for these 15 pollsters:
```{r}
qplot(spread, data = one_poll_per_pollster, binwidth = 0.01)
```
In the previous section, we saw that using the urn model theory to combine these results might not be appropriate due to the pollster effect. Instead, we will model this spread data directly.
Our urn now contains poll results from all possible pollsters. We assume that the expected value of our urn is the actual spread d=2p-1.
the standard error now includes the pollster-to-pollster variability. Our new urn also includes the sampling variability from the polling. Regardless, this standard deviation is now an unknown parameter. In statistics textbooks, the Greek symbol σ is used to represent this parameter.
> In summary, we have two unknown parameters: the expected value d and the standard deviation σ.
estimating d: for a large enough sample size N, average $\bar{X}$ is approximately normal with expected value $\mu$ and standard error $\sigma/ \sqrt{N}$.
we do not know $\sigma$ but we can estimate with the sample standard deviation defined as
$$
s=\sqrt{\sum{_{i=1}^N}((X_i-\bar{X}))^2 / (N-1)}
$$
Unlike for the population standard deviation definition, we now divide by N-1. This makes s a better estimate of $\sigma$.
The `sd` function in R computes the sample standard deviation:
```{r}
sd(one_poll_per_pollster$spread)
```
We are now ready to form a new confidence interval based on our new data-driven model:
```{r}
results <- one_poll_per_pollster %>%
summarize(avg = mean(spread), se = sd(spread)/sqrt(length(spread))) %>%
mutate(start = avg -1.96*se, end =avg+1.96*se)
round(results*100, 1)
```
## 16.3 Exercises
We have been using urn models to motivate the use of probability models. More common are data that come from individuals.
Let’s revisit the heights dataset. Suppose we consider the males in our course the population.
```{r}
library(dslabs)
data("heights")
x<-heights %>% filter(sex == "Male") %>%
pull(height)
```
1. Mathematically speaking, x is our population. Using the urn analogy, we have an urn with the values of x in it. What are the average and standard deviation of our population?
```{r}
mean(x)
sd(x)
```
2. Call the population average computed above μ and the standard deviation σ. Now take a sample of size 50, with replacement, and construct an estimate for μ and σ.
```{r}
X<-sample(x, size=50, replace = TRUE)
mean(X)
sd(X)
```
3. What does the theory tell us about the sample average $\bar{X}$ and how it is related to $\mu$?
a. It is practically identical to $\mu$.
__b. It is a random variable with expected value $\mu$ and standard error $\sigma/\sqrt{N}$.__
c. It is a random variable with expected value $\mu$ and standard error $\sigma$.
d. Contains no information.
4. So how is this useful? We are going to use an oversimplified yet illustrative example. Suppose we want to know the average height of our male students, but we only get to measure 50 of the 708. We will use $\bar{X}$ as our estimate. We know from the answer to exercise 3 that the standard estimate of our error $\bar{X}-\mu$ is $\sigma/\sqrt{N}$. We want to compute this, but we don't know $\sigma$. Based on what is described in this section, show your estimate of $\sigma$.
```{r}
sd(X)
```
5. Now that we have an estimate of $\sigma$, let's call our estimate $s$. Construct a 95% confidence interval for $\mu$.
```{r}
m <- mean(X)
se <- sd(X)/sqrt(length(X))
c(m - 1.96 * se, m + 1.96 * se)
```
6. Now run a Monte Carlo simulation in which you compute 10,000 confidence intervals as you have just done. What proportion of these intervals include $\mu$?
```{r}
s<-sd(X)/sqrt(N)
N <- 50
B <- 10000
S <- replicate(B, {
X <- sample(x, N, replace=TRUE)
interval <- c(mean(X) - 1.96 * s, mean(X) + 1.96 *s)
between(X, interval[1], interval[2])
})
mean(S)
```
7. In this section, we talked about pollster bias. We used visualization to motivate the presence of such bias. Here we will give it a more rigorous treatment. We will consider two pollsters that conducted daily polls. We will look at national polls for the month before the election.
```{r}
data(polls_us_election_2016)
polls <- polls_us_election_2016 %>%
filter(pollster %in% c("Rasmussen Reports/Pulse Opinion Research", "The Times-Picayune/Lucid") & enddate >= "2016-10-15" & state == "U.S.") %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100)
```
We want to answer the question: is there a poll bias? Make a plot showing the spreads for each poll.
```{r}
polls %>% ggplot(aes(pollster, spread)) +
geom_boxplot() +
geom_point()
```
8. The data does seem to suggest there is a difference. However, these
data are subject to variability. Perhaps the differences we observe are due to chance.
The urn model theory says nothing about pollster effect. Under the urn model, both pollsters have the same expected value: the election day difference, that we call $d$.
To answer the question "is there an urn model?", we will model the observed data $Y_{i,j}$ in the following way:
$$
Y_{i,j} = d + b_i + \varepsilon_{i,j}
$$
with $i=1,2$ indexing the two pollsters, $b_i$ the bias for pollster $i$ and $\varepsilon_ij$ poll to poll chance variability. We assume the $\varepsilon$ are independent from each other, have expected value $0$ and standard deviation $\sigma_i$ regardless of $j$.
Which of the following best represents our question?
a. Is $\varepsilon_{i,j}$ = 0?
b. How close are the $Y_{i,j}$ to $d$?
__c. Is $b_1 \neq b_2$?__
d. Are $b_1 = 0$ and $b_2 = 0$ ?
9. In the right side of this model only $\varepsilon_{i,j}$ is a random variable. The other two are constants. What is the expected value of $Y_{1,j}$?
$$
d + b_1
$$
10. Suppose we define $\bar{Y}_1$ as the average of poll results from the first poll, $Y_{1,1},\dots,Y_{1,N_1}$ with $N_1$ the number of polls conducted by the first pollster:
```{r}
Y_1<-polls %>%
filter(pollster=="Rasmussen Reports/Pulse Opinion Research") %>%
summarize(N_1 = n())
```
What is the expected values $\bar{Y}_1$?
$$
d + b_1
$$
11. What is the standard error of $\bar{Y}_1$ ?
$$
\sigma_1/\sqrt{N_1}
$$
12. Suppose we define $\bar{Y}_2$ as the average of poll results from the first poll, $Y_{2,1},\dots,Y_{2,N_2}$ with $N_2$ the number of polls conducted by the first pollster. What is the expected value $\bar{Y}_2$?
$$
d + b_2
$$
13. What is the standard error of $\bar{Y}_2$ ?
$$
\sigma_2/\sqrt{N_2}
$$
14. Using what we learned by answering the questions above, what is the expected value of $\bar{Y}_{2} - \bar{Y}_1$?
$$
(d + b_2) - (d + b_1) = b_2 - b1
$$
15. Using what we learned by answering the questions above, what is the standard error of $\bar{Y}_{2} - \bar{Y}_1$?
$$
\sqrt{\sigma_2^2/N_2 + \sigma_1^2/N_1}
$$
16. The answer to the question above depends on $\sigma_1$ and $\sigma_2$, which we don't know. We learned that we can estimate these with the sample standard deviation. Write code that computes these two estimates.
```{r}
polls %>% group_by(pollster) %>%
summarize(s = sd(spread))
```
17. What does the CLT tell us about the distribution of $\bar{Y}_2 - \bar{Y}_1$?
a. Nothing because this is not the average of a sample.
b. Because the $Y_{ij}$ are approximately normal, so are the averages.
__c. Note that $\bar{Y}_2$ and $\bar{Y}_1$ are sample averages, so if we assume $N_2$ and $N_1$ are large enough, each is approximately normal. The difference of normals is also normal.__
d. The data are not 0 or 1, so CLT does not apply.
18. We have constructed a random variable that has expected value $b_2 - b_1$, the pollster bias difference. If our model holds, then this random variable has an approximately normal distribution and we know its standard error. The standard error depends on $\sigma_1$ and $\sigma_2$, but we can plug the sample standard deviations we computed above. We started off by asking: is $b_2 - b_1$ different from 0? Use all the information we have learned above to construct a 95% confidence interval for the difference $b_2$ and $b_1$.
```{r}
poll <- polls %>%
group_by(pollster) %>%
summarize(m = mean(spread), s = sd(spread), N = n())
e <- poll$m[2] - poll$m[1]
se <- sqrt(poll$s[2]^2/poll$N[2]-poll$s[1]^2/poll$N[1])
c(e - 1.96 * se, e + 1.96 * se)
```
19. The confidence interval tells us there is relatively strong pollster effect resulting in a difference of about 5%. Random variability does not seem to explain it. We can compute a p-value to relay the fact that chance does not explain it. What is the p-value?
```{r}
z <- sqrt(N)*0.05/sqrt(e*(1-e))
1 - (pnorm(z) - pnorm(-z))
```
20. The statistic formed by dividing our estimate of $b_2-b_1$ by its estimated standard error:
$$
\frac{\bar{Y}_2 - \bar{Y}_1}{\sqrt{s_2^2/N_2 + s_1^2/N_1}}
$$
is called the t-statistic. Now notice that we have more than two pollsters. We can also test for pollster effect using all pollsters, not just two. The idea is to compare the variability across polls to variability within polls. We can actually construct statistics to test for effects and approximate their distribution. The area of statistics that does this is called Analysis of Variance or ANOVA. We do not cover it here, but ANOVA provides a very useful set of tools to answer questions such as: is there a pollster effect?
For this exercise, create a new table:
```{r}
polls <- polls_us_election_2016 %>%
filter(enddate >= "2016-10-15" &
state == "U.S.") %>%
group_by(pollster) %>%
filter(n() >= 5) %>%
mutate(spread = rawpoll_clinton/100 - rawpoll_trump/100) %>%
ungroup()
```
Compute the average and standard deviation for each pollster and examine the variability across the averages and how it compares to the variability within the pollsters, summarized by the standard deviation.
```{r}
polls %>% group_by(pollster) %>%
summarize(avg = mean(spread), sd = sd(spread))
```