- Multihead attention:
- Attention: 这里是把query和key做矩阵乘法,scaled,然后再和value做加权,得到一个Tq * d_v的矩阵,每一行是对应query的attention
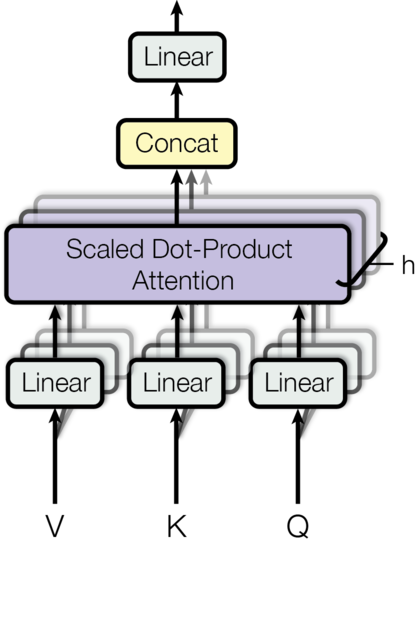
- Multihead attention: 把query,key以及value的每个维度再细分到不同的head上面
示意图
- Encoder Decoder的组合方式:Decoder的每一层对自己做attention,然后对encoder做attention,每次都是residual的方式连接,最后ff输出,也是residual连接
- Residual connection:x + sublayer(x)
- Greedy解码:每次把当前解码好的序列输入,得到下一个的解码,里面用了一个start symbol把seq向右整体平移一位
- BLEU算法: