diff --git a/README.md b/README.md
index 52eda092c8..69f751b9e5 100644
--- a/README.md
+++ b/README.md
@@ -159,6 +159,7 @@ Results and models are available in the [model zoo](docs/en/model_zoo.md).
- [x] [K-Net (NeurIPS'2021)](configs/knet)
- [x] [MaskFormer (NeurIPS'2021)](configs/maskformer)
- [x] [Mask2Former (CVPR'2022)](configs/mask2former)
+- [x] [PIDNet (ArXiv'2022)](configs/pidnet)
diff --git a/README_zh-CN.md b/README_zh-CN.md
index 167ecbdc40..709e6ef195 100644
--- a/README_zh-CN.md
+++ b/README_zh-CN.md
@@ -140,6 +140,7 @@ MMSegmentation 是一个基于 PyTorch 的语义分割开源工具箱。它是 O
- [x] [K-Net (NeurIPS'2021)](configs/knet)
- [x] [MaskFormer (NeurIPS'2021)](configs/maskformer)
- [x] [Mask2Former (CVPR'2022)](configs/mask2former)
+- [x] [PIDNet (ArXiv'2022)](configs/pidnet)
diff --git a/configs/pidnet/README.md b/configs/pidnet/README.md
new file mode 100644
index 0000000000..545b76e8b0
--- /dev/null
+++ b/configs/pidnet/README.md
@@ -0,0 +1,50 @@
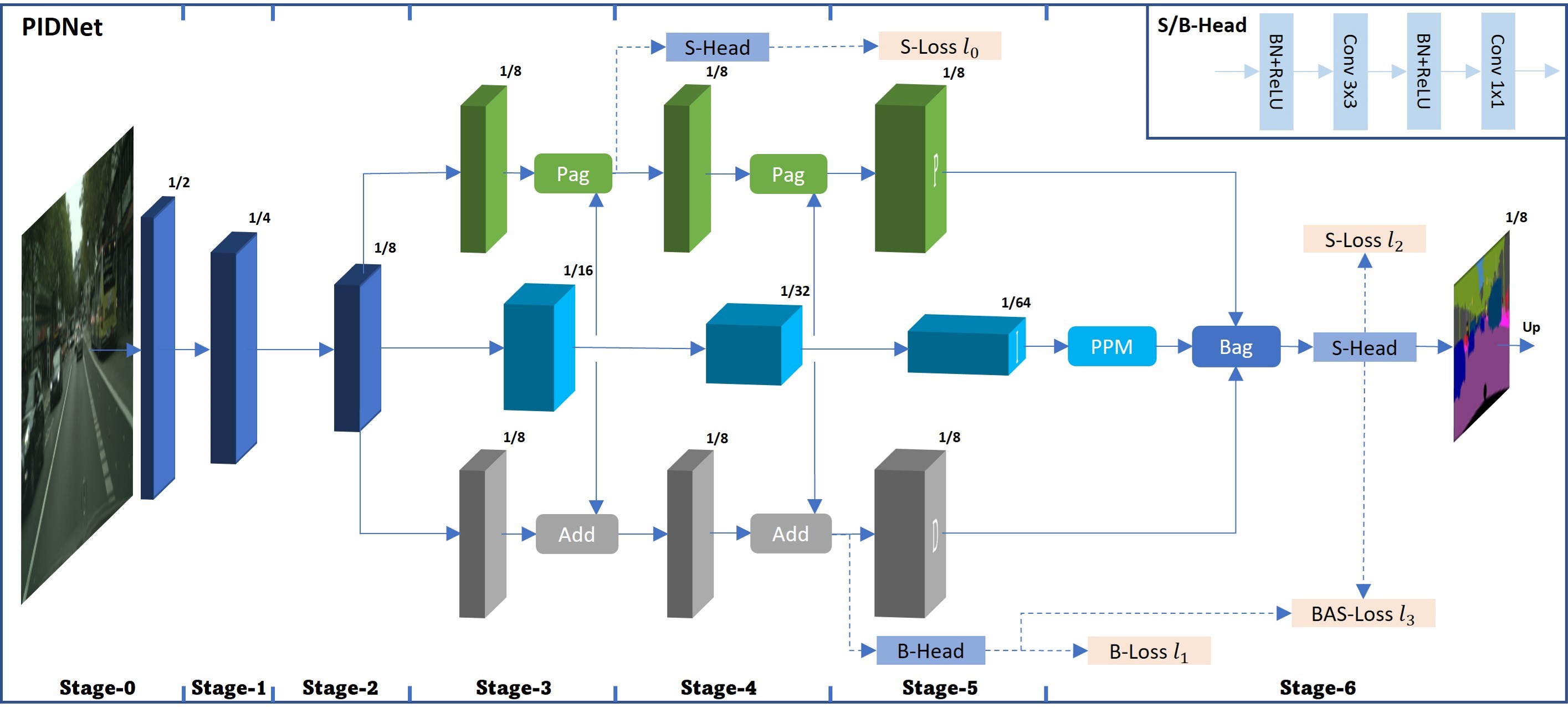
+# PIDNet
+
+> [PIDNet: A Real-time Semantic Segmentation Network Inspired from PID Controller](https://arxiv.org/pdf/2206.02066.pdf)
+
+## Introduction
+
+
+
+Official Repo
+
+Code Snippet
+
+## Abstract
+
+
+
+Two-branch network architecture has shown its efficiency and effectiveness for real-time semantic segmentation tasks. However, direct fusion of low-level details and high-level semantics will lead to a phenomenon that the detailed features are easily overwhelmed by surrounding contextual information, namely overshoot in this paper, which limits the improvement of the accuracy of existed two-branch models. In this paper, we bridge a connection between Convolutional Neural Network (CNN) and Proportional-IntegralDerivative (PID) controller and reveal that the two-branch network is nothing but a Proportional-Integral (PI) controller, which inherently suffers from the similar overshoot issue. To alleviate this issue, we propose a novel threebranch network architecture: PIDNet, which possesses three branches to parse the detailed, context and boundary information (derivative of semantics), respectively, and employs boundary attention to guide the fusion of detailed and context branches in final stage. The family of PIDNets achieve the best trade-off between inference speed and accuracy and their test accuracy surpasses all the existed models with similar inference speed on Cityscapes, CamVid and COCO-Stuff datasets. Especially, PIDNet-S achieves 78.6% mIOU with inference speed of 93.2 FPS on Cityscapes test set and 80.1% mIOU with speed of 153.7 FPS on CamVid test set.
+
+
+
+
+
+