diff --git a/.github/workflows/pica_crawler_actions.yml b/.github/workflows/pica_crawler_actions.yml
index 3984c3ab..c4309d7d 100644
--- a/.github/workflows/pica_crawler_actions.yml
+++ b/.github/workflows/pica_crawler_actions.yml
@@ -23,23 +23,12 @@ jobs:
PICA_SECRET_KEY: ${{secrets.PICA_SECRET_KEY}}
PICA_ACCOUNT: ${{secrets.PICA_ACCOUNT}}
PICA_PASSWORD: ${{secrets.PICA_PASSWORD}}
- # 过滤分区 用,分隔
- CATEGORIES: CG雜圖,生肉,耽美花園,偽娘哲學,扶他樂園,性轉換,SAO 刀劍神域,WEBTOON,Cosplay
- # CATEGORIES_RULE 过滤规则 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
- CATEGORIES_RULE: EXCLUDE
- # 订阅的关键词,会下载x天范围内上传的漫画 为空则关闭关键词订阅 用,分隔
- SUBSCRIBE_KEYWORD: ひぐま屋 (野良ヒグマ),アキレルショウジョ,オクモト悠太,ゐちぼっち,黒本君,もすきーと音
- # 订阅的x天范围 git actions运行时填小一点,免得漫画过多邮箱推送不了,本地运行时随便填
- SUBSCRIBE_DAYS: 7
# 允许在下载完成后发送自定义消息,为空则不发送 例: https://api.day.app/{your_keys}/picacg下载成功
BARK_URL: ${{secrets.BARK_URL}}
- #每下载一本漫画的间隔时间(秒),在下载大量漫画时可以设置的稍微大一些,免得哔咔服务器响应不过来
- INTERVAL_TIME: 5
- #下载阶段是否输出细节信息
- DETAIL: True
run: |
python ./src/main.py
git add ./data/downloaded.db
+ git add ./logs
# comics文件夹下的所有漫画都会被打成一个压缩包,并上传到actions artifact. 如果不配置邮箱推送功能,可以用这个来下载到漫画
- name: upload-artifact
uses: actions/upload-artifact@v4
diff --git a/src/Dockerfile b/Dockerfile
similarity index 55%
rename from src/Dockerfile
rename to Dockerfile
index 38cd1176..f0a52455 100644
--- a/src/Dockerfile
+++ b/Dockerfile
@@ -8,21 +8,14 @@ WORKDIR /app
#RUN apt-get update && apt-get install -y build-essential
# 设置环境变量
-ENV PICA_SECRET_KEY="" \
- REQUEST_PROXY="" \
- PACKAGE_TYPE="False" \
- BARK_URL="" \
- INTERVAL_TIME="5" \
- DETAIL="False" \
- REQUEST_TIME_OUT="10" \
- CHANGE_FAVOURITE="False" \
+ENV PACKAGE_TYPE="False" \
DELETE_COMIC="True"
# 将当前目录内容复制到工作目录中
COPY . /app
# 安装依赖项
-RUN pip install --no-cache-dir requests urllib3
+RUN pip install --progress-bar off requests urllib3
# 指定容器启动时执行的命令
-CMD ["python", "main.py"]
+CMD ["python", "./src/main.py"]
diff --git a/README.md b/README.md
index ab2f31e7..0c4268f6 100644
--- a/README.md
+++ b/README.md
@@ -3,116 +3,96 @@
一个哔咔漫画的下载程序,基于python实现,欢迎各位绅士来捉虫
* 目前已实现按 排行榜/收藏夹/指定关键词 进行下载的功能
* 本项目是基于[AnkiKong大佬开源的项目](https://github.com/AnkiKong/picacomic)编写的,仅供技术研究使用,请勿用于其他用途,有问题可以提issue
-* 可以fork这个项目,根据[api文档](https://www.apifox.cn/apidoc/shared-44da213e-98f7-4587-a75e-db998ed067ad/doc-1034189)自行开发功能
* 麻烦给个star支持一下:heart:
-# 本地运行
+## 下载的范围
-漫画直接下载到本地磁盘,免去了邮箱推送这个步骤
-需要手动运行,不支持定时运行,适合下载大量漫画
-1. clone项目到本地
-2. 把pica_crawler_actions.yml的`env`中所有环境变量配置到本地
-3. 开启科学上网
-4. 参考`./config/config_backup.ini`构建个人配置文件`./config/config.ini`
-5. 运行`main.py`,下载好的漫画在`/comics`这个文件夹内
-6. 下载过的漫画将被维护进`data/downloaded.db`文件中
+### 排行榜
+哔咔24小时排行榜内的所有漫画
+### 收藏夹
+收藏夹内的所有漫画,下载完成是否取消收藏取决于配置文件中的`CHANGE_FAVOURITE`, if ="True":自动取消收藏; elif ="False":不取消收藏
-# docker 运行
+### 关键词订阅
+`./config/config.ini`里的`subscribe_keyword`里配置若干个关键词,下载范围等同于在哔咔app里用关键词搜索到的所有漫画
-新增了环境变量 `PACKAGE_TYPE`, 参数为 True 和 False
-设置为True时, 会根据漫画名称压缩成zip包, 以供 Komga 等漫画库 使用, 也会删除comics文件夹 ( 避免docker容器占用过多硬盘 )
-```python
-# main.py
-if os.environ.get("PACKAGE_TYPE", "False") == "True":
- # 打包成zip文件, 并删除旧数据
- zip_subfolders('./comics', './output')
- shutil.rmtree('./comics')
-```
+### 部分漫画不会被下载的原因
+排行榜/订阅的漫画会受到以下过滤逻辑的影响,**收藏夹则不会**(如果下载到本地后文件丢失了,可以通过放入收藏夹把它全量下载下来)
-新增了环境变量 `REQUEST_PROXY`, 这样下载图片时允许使用代理了
-```python
-# client.py
-proxy = os.environ.get("REQUEST_PROXY")
-if proxy:
- proxies = {'http': proxy, 'https': proxy}
-else:
- proxies = None
-response = self.__s.request(method=method, url=url, verify=False, proxies=proxies, **kwargs)
-return response
-```
+#### 过滤重复下载
-新增了环境变量 `BARK_URL`, bark消息通知
- 允许打包完成 or 下载完成发送自定义消息, 例: `https://api.day.app/{your_keys}/picacg下载成功`
-```python
-# main.py
-if os.environ.get("BARK_URL"):
- # 发送消息通知
- request.get(os.environ.get("BARK_URL"))
-```
+`./data/downloaded.db`文件记录了已扫描过的漫画id, 并记录了成功下载过的漫画章节名和基本信息.
+如果数据库文件中存在该漫画id, **则触发增量下载,跳过已下载的章节**, 否则触发全量下载.
+若采用GitHub Actions方式运行, 会将`./data/downloaded.db`文件提交到代码仓库以保存本次的运行结果. 若`GIT_TOKEN`配置错误则代码提交失败,从而导致漫画被重复下载和推送
-可以挂载这两个目录
-工作目录为 `/app/comics` 存放下载漫画图片的文件夹, `/app/output` 存放输出zip的文件夹
+#### 过滤分区
+`config.ini`文件的``CATEGORIES``配置项可以配置0~n个哔咔的分区, 配置为空则代表不过滤
-1. `docker-compose.yml` 参考 docker-compose.yml 文件
+``CATEGORIES_RULE``可以配置为 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
-2. `docker cli` 最小运行
+> 部分漫画只打上了'短篇'/'长篇'这样单个分区,在配置为``INCLUDE``时,建议把比较常见的分区给填上,不然容易匹配不到漫画
-PICA_SECRET_KEY可以不用更改, 如果需要更改时, 注意是单引号内容
-新增了环境变量 `REQUEST_TIME_OUT`, 自定义限制每次请求最大时间;新增了环境变量 `DETAIL`, 下载阶段是否输出细节信息;新增了 `CHANGE_FAVOURITE`, 是否自动删除收藏夹;新增环境变量 `DELETE_COMIC`, 是否打包后删除漫画;
+#### 订阅的时间范围
+对于订阅的漫画,如果 当天 - 订阅漫画的上传日 > `subscribe_days`,这本漫画将不再被下载
-docker部署建议将PACKAGE_TYPE打开, 同时挂载/app/output目录
-```docker
-docker run --name picacg-download-container -d \
- -e PICA_ACCOUNT="账户名称" \
- -e PICA_PASSWORD="账户密码" \
- -e REQUEST_PROXY="http代理(可选)" \
- -e BARK_URL="bark消息通知(可选)" \
- -e PACKAGE_TYPE="True" \
- -e REQUEST_TIME_OUT="限制时间s: int(可选)"
- -e DETAIL="False" \
- -e CHANGE_FAVOURITE="True" \
- -e DELETE_COMIC="False" \
- -e PICA_SECRET_KEY='~d}$Q7$eIni=V)9\RK/P.RM4;9[7|@/CA}b~OW!3?EV`:<>M7pddUBL5n|0/*Cn' \
- -v ./comics:/app/comics \
- -v ./output:/app/output \
- yuanzhangzcc/picacg-download:latest
+
+#### 检查日志文件
+在文件夹`logs`下存储有运行日志文件,所有日志按天自动划分,自动删除超过`backup_count`天的日志。错误信息单独保存到`ERROR_*.log`中。
+
+# 运行方式
+
+## 本地运行
+1. 参考`./config/config_backup.ini`构建个人配置文件`./config/config.ini`,缺少该文件项目将无法运行
+2. 开启科学上网
+3. 在项目根目录下运行`python ./src/main.py`. 漫画将被下载到`./comics`文件夹下, 同时将已下载的漫画维护进`./data/downloaded.db`文件中
+
+## Docker 运行
+> 因为`./config/config.ini`要配置的东西有点多, 推荐把项目clone下来, 改完配置后自行构建镜像
+
+1. 参考`./config/config_backup.ini`构建个人配置文件`./config/config.ini`,缺少该文件项目将无法运行
+2. 修改`Dockerfile`文件中ENV环境变量的配置
+`PACKAGE_TYPE`: 参数为 True / False. 设置为True时, 会根据漫画名称压缩成zip包, 以供 Komga 等漫画库使用
+`DELETE_COMIC`: 参数为 True / False. 设置为True时, 会在压缩包生成后删除文件夹下的漫画( 避免docker容器占用过多硬盘 )
+3. 在项目根目录下运行`docker build -t picacg-download:latest .`
+4. 启动容器的脚本
+```shell
+docker run --name picacg-download-container -d
+ -v ./comics:/app/comics #挂载存放下载漫画图片的文件夹
+ -v ./output:/app/output #挂载存放压缩包的文件夹(如果配置了需要打包)
+ #-e 添加环境变量可以覆盖config.ini中的配置, 免去重新build的操作
+ picacg-download:latest
```
-# git actions运行
+## GitHub Actions运行
-漫画将会以压缩包附件的形式推送到邮箱上,受限于邮件的附件大小,漫画会被打包为若干个压缩包,一次性可能会收到若干个邮件
+漫画将会以压缩包附件的形式推送到邮箱上,受限于邮件的附件大小限制,漫画会被打包为若干个压缩包,一次性可能会收到若干个邮件
不同邮箱支持的最大邮件内容不同,qq/新浪是50mb,outlook是20mb,建议用大一点的,避免拆分的压缩包过多下载起来麻烦
-支持自动定时运行,适合每天推送少量的漫画
-* fork本仓库
-* 新增Actions secrets
+支持自动定时运行,无需搭建个人服务器,适合每天推送少量的漫画
+1. fork本仓库
+2. 新增Actions secrets
-| secret | 说明 |
+| Actions secrets | 说明 |
| --------------- | ------------------------------------------------------------ |
| PICA_SECRET_KEY | [AnkiKong提供的secret_key](https://zhuanlan.zhihu.com/p/547321040) |
| PICA_ACCOUNT | 哔咔登录的账号 |
| PICA_PASSWORD | 哔咔登录的密码 |
| EMAIL_ACCOUNT | 接收漫画的邮箱 |
-| BARK_URL | 允许打包完成 or 下载完成发送自定义消息 例: `https://api.day.app/{your_keys}/picacg下载成功` |
| EMAIL_AUTH_CODE | 邮箱的授权码,[参考qq邮箱的这篇文档](https://service.mail.qq.com/cgi-bin/help?subtype=1&&id=28&&no=1001256) |
| GIT_TOKEN | [参考这篇文章](http://t.zoukankan.com/joe235-p-15152380.html),只勾选repo的权限,Expiration设置为No Expiration |
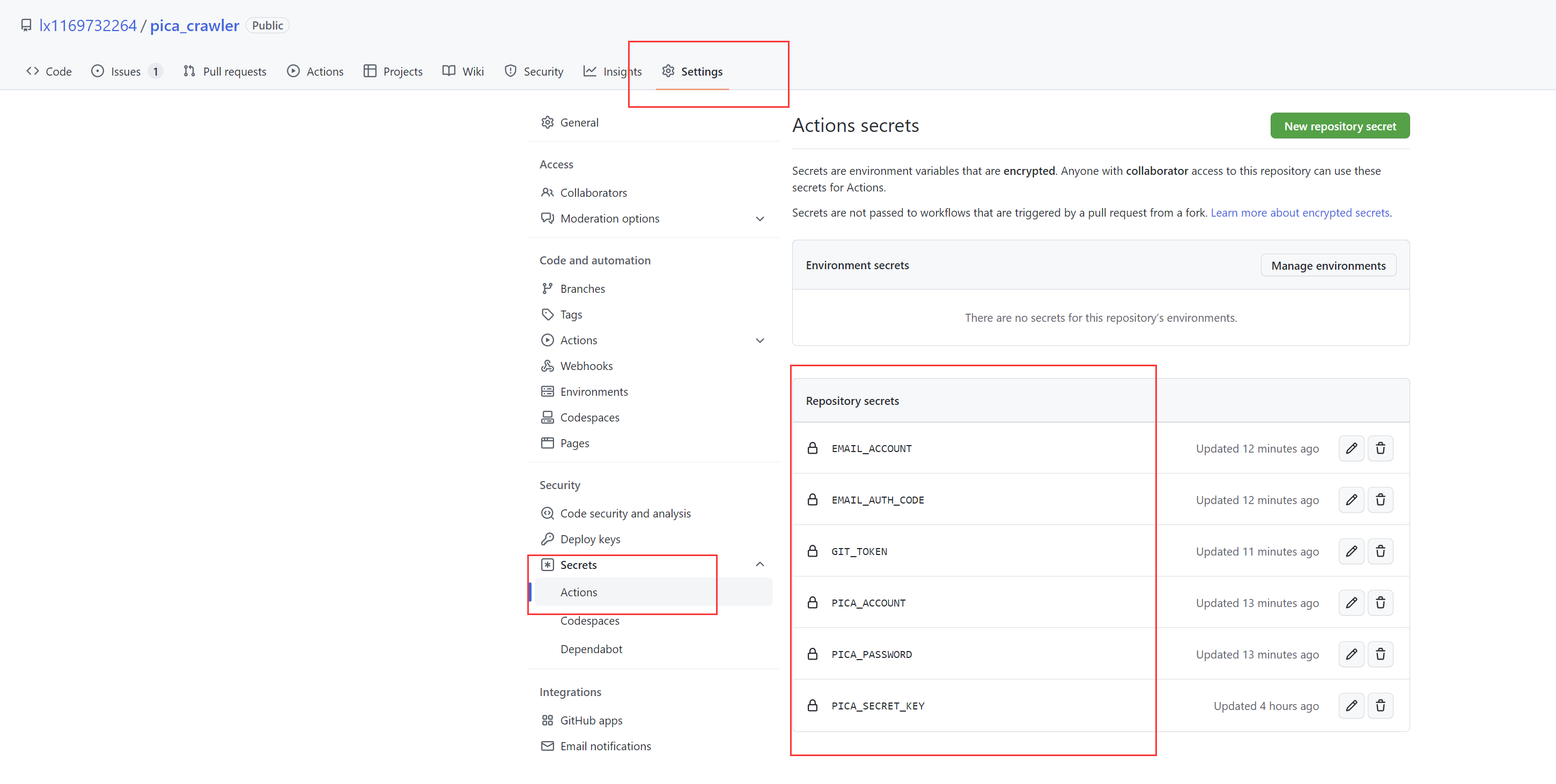 +3. 参考`./config/config_backup.ini`调整个人配置文件`./config/config.ini`并上传至GitHub代码仓库(Actions secrets中已配置的内容空着不填即可)
-
-* 打开fork项目的workFlow开关
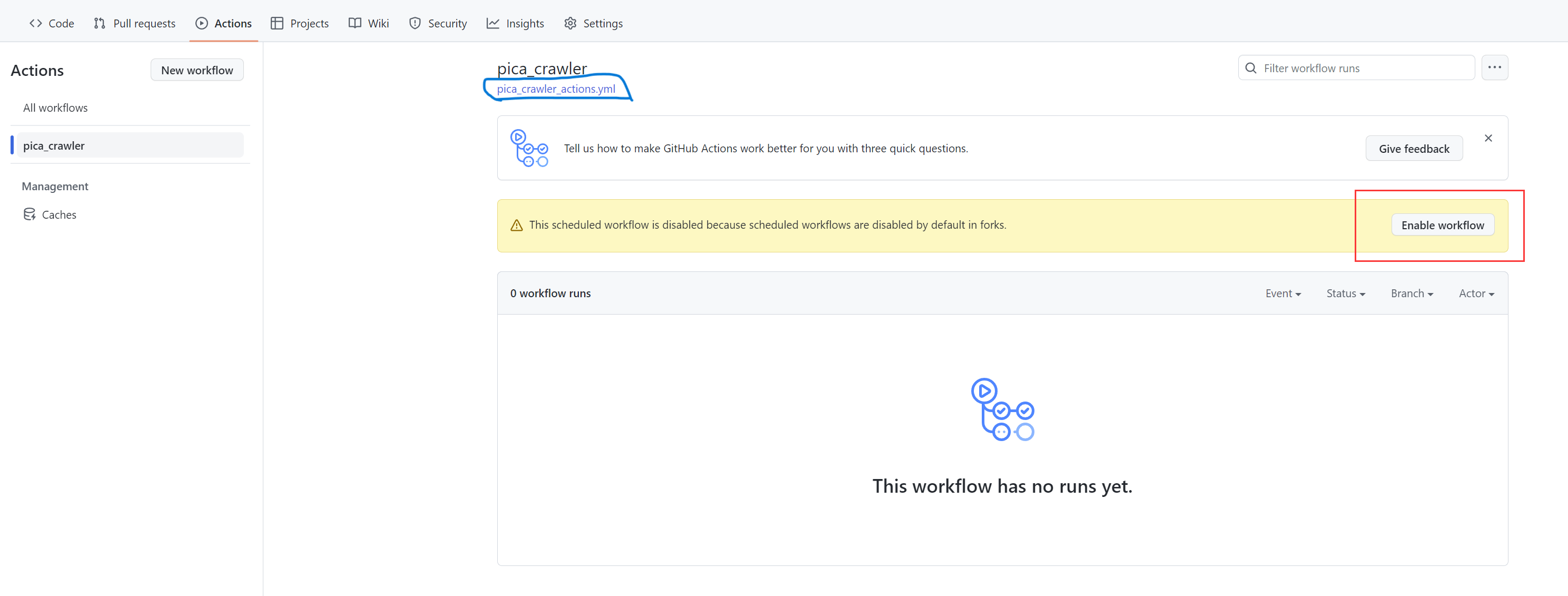
+4. 打开fork项目的workFlow开关
+3. 参考`./config/config_backup.ini`调整个人配置文件`./config/config.ini`并上传至GitHub代码仓库(Actions secrets中已配置的内容空着不填即可)
-
-* 打开fork项目的workFlow开关
+4. 打开fork项目的workFlow开关
 -* 点击pica_crawler_actions.yml,编辑git actions. 写了注释的配置项,都可以根据需求改动
-
-
-* 点击pica_crawler_actions.yml,编辑git actions. 写了注释的配置项,都可以根据需求改动
-
-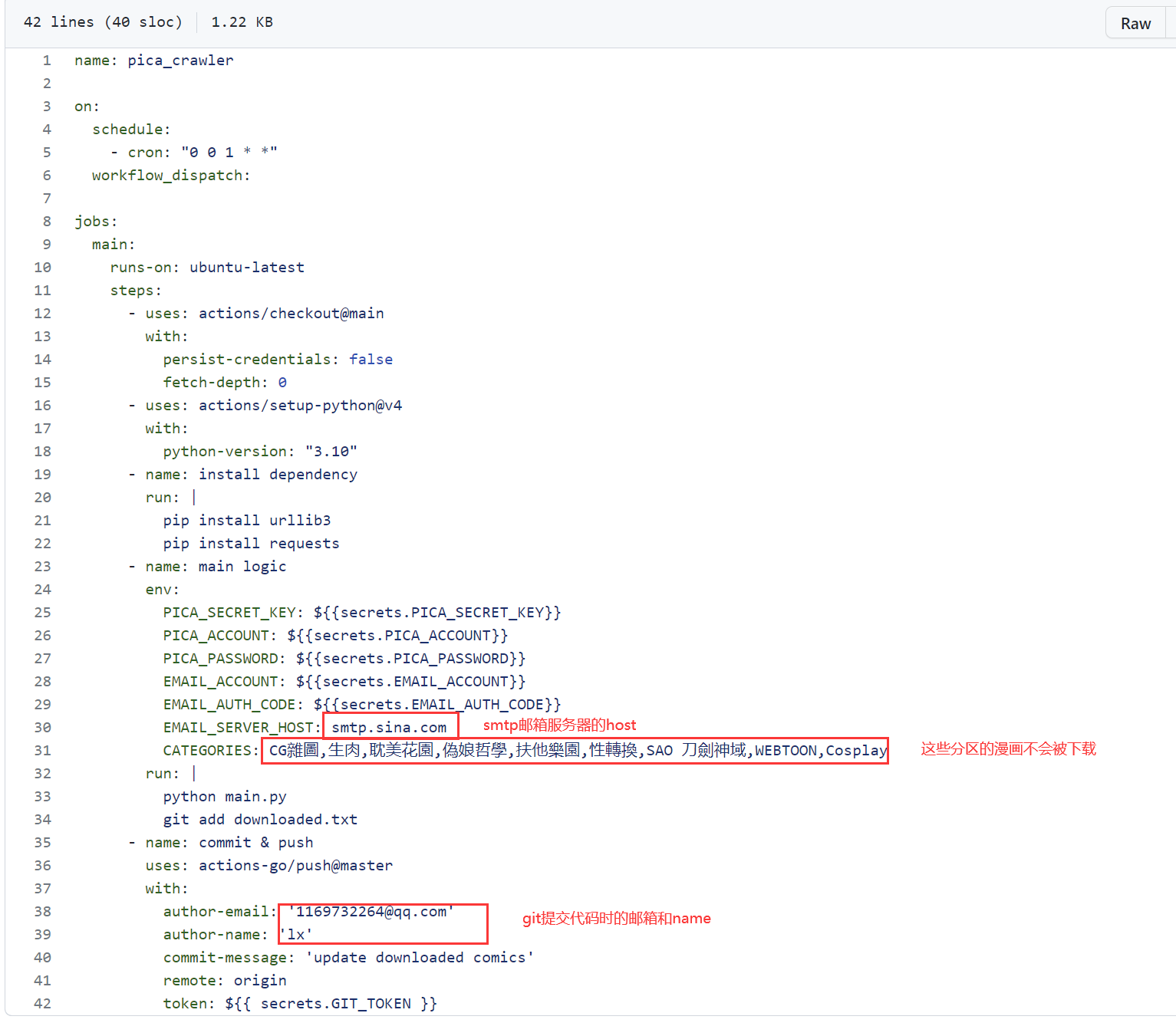 +5. 修改`./.github/workflows/pica_crawler_actions.yml`配置文件. 如果需要邮箱推送,请修改`EMAIL_SERVER_HOST`等邮箱相关的配置
-
-* 手动触发一次,测试下能不能跑通
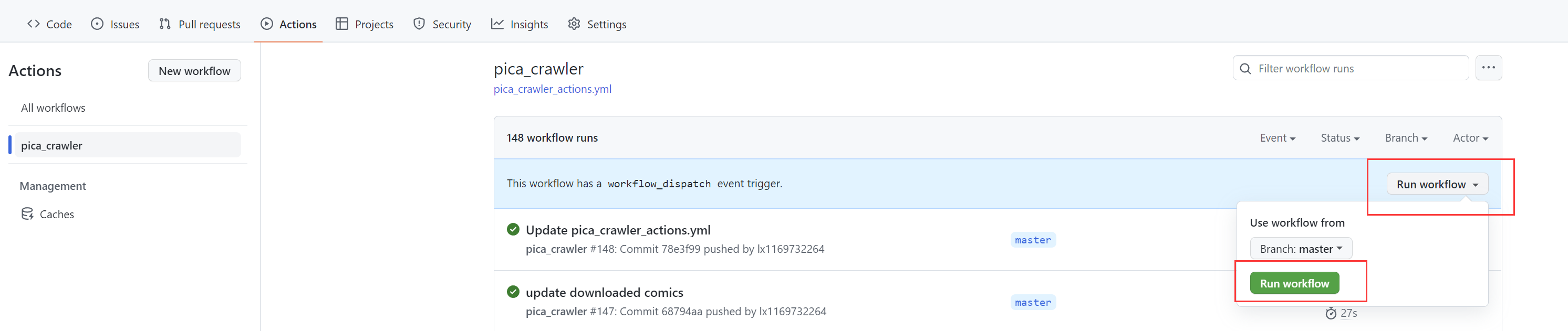
+6. 手动触发一次,测试下能不能跑通
+5. 修改`./.github/workflows/pica_crawler_actions.yml`配置文件. 如果需要邮箱推送,请修改`EMAIL_SERVER_HOST`等邮箱相关的配置
-
-* 手动触发一次,测试下能不能跑通
+6. 手动触发一次,测试下能不能跑通
 @@ -120,60 +100,18 @@ docker run --name picacg-download-container -d \
**成功运行的截图:**
@@ -120,60 +100,18 @@ docker run --name picacg-download-container -d \
**成功运行的截图:**
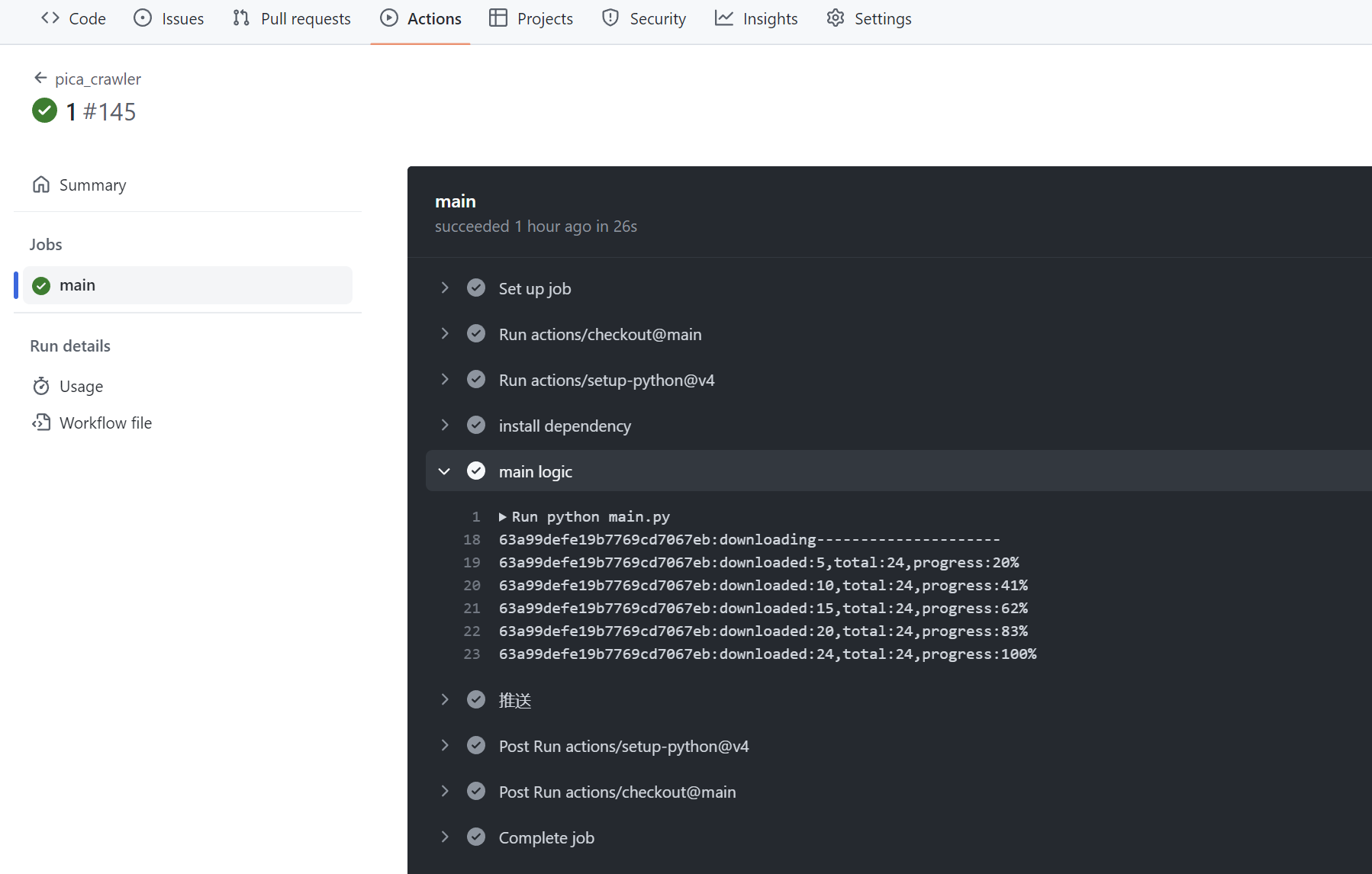 -* 成功运行后,可以在这里下载到漫画的压缩包. 如果配置了邮箱推送功能,还可以查收邮件里的附件
+7. 成功运行后,可以在这里下载到漫画的压缩包. 如果配置了邮箱推送功能,还可以查收邮件里的附件
-* 成功运行后,可以在这里下载到漫画的压缩包. 如果配置了邮箱推送功能,还可以查收邮件里的附件
+7. 成功运行后,可以在这里下载到漫画的压缩包. 如果配置了邮箱推送功能,还可以查收邮件里的附件
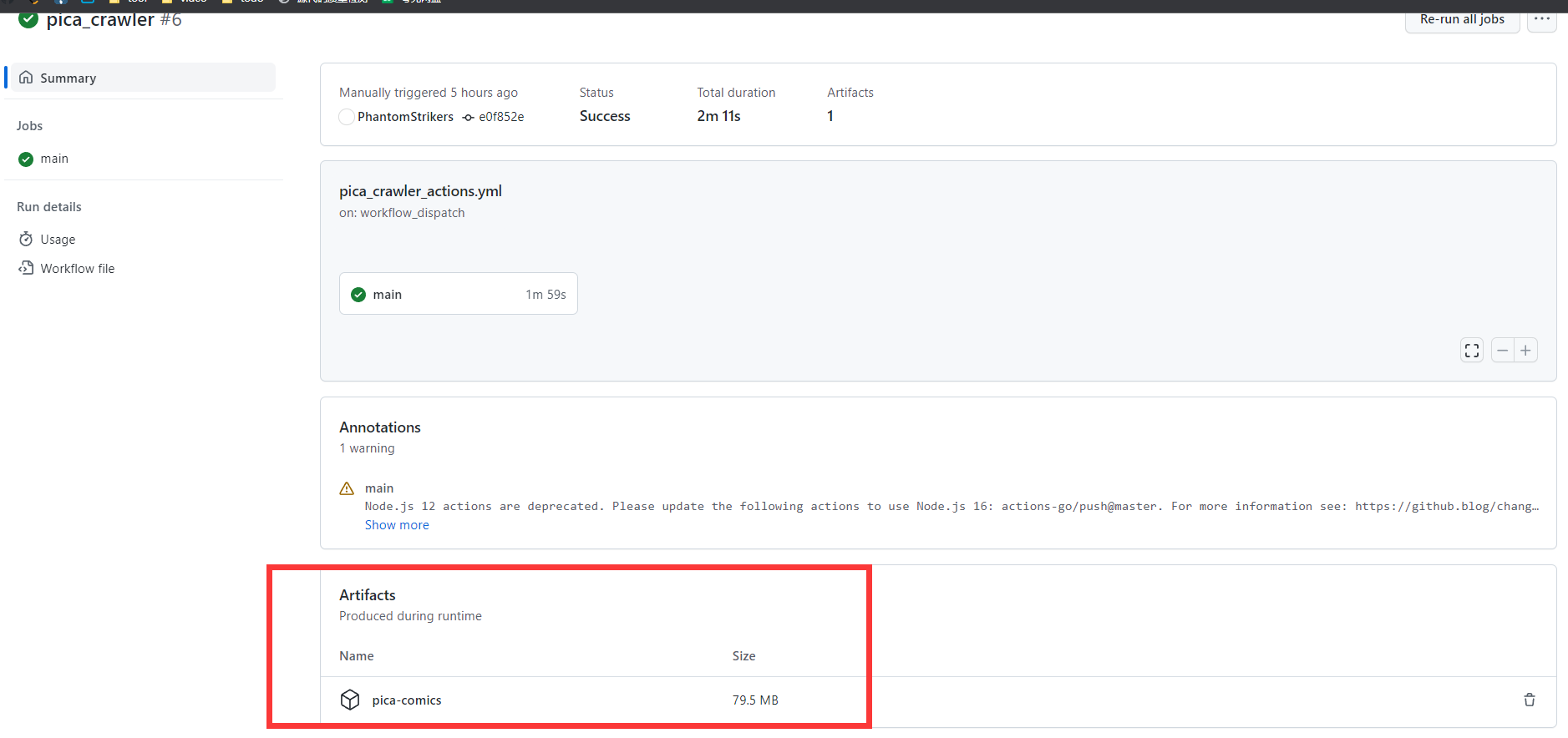 * [我自己也fork了一份](https://github.com/PhantomStrikers/pica_crawler.git),每天都在自动运行的,可以通过这个项目的actions运行记录判断这个项目是否还能work
-
-# 解压注意事项
+### 邮件压缩包的解压注意事项
1. 将所有邮件的压缩包下载至统一目录. (存在单个压缩包里可能只有半本漫画的情况),然后**全选**压缩包,右键**解压到当前文件夹**.
-2. 如果你在上个步骤选择右键解压文件,默认是以压缩包名创建一个新的文件夹,会出现漫画拆散在不同文件夹的情况
+2. 如果你在上个步骤选择右键**解压文件**,默认是以压缩包名创建一个新的文件夹,会出现漫画被拆散在不同文件夹的情况
3. 压缩包默认zip格式,无解压密码.遇到解不开的情况可能是下载时压缩包损坏了,尝试下重新下载
-# 下载的范围
-
-## 排行榜
-哔咔24小时排行榜内的所有漫画
-
-## 收藏夹
-收藏夹内的所有漫画,下载完成是否取消收藏取决于环境变量`CHANGE_FAVOURITE`, if ="True":自动取消收藏; elif ="False":不取消收藏
-
-## 关键词订阅
-`./config/config.ini`里的`subscribe_keyword`里配置若干个关键词,下载范围等同于在哔咔app里用关键词搜索到的所有漫画
-这个功能可能会下载过量的漫画,导致邮箱无法推送,可以调整`subscribe_days`缩小下载范围,或者是本地运行`main.py`
-
-# 部分漫画不会被下载的原因
-排行榜/订阅的漫画会受到以下过滤逻辑的影响,**收藏夹则不会**(如果下载到本地后文件丢失了,可以通过放入收藏夹把它全量下载下来)
-
-
-### 过滤重复下载
-
-`./data/downloaded.db`文件记录了已扫描过的漫画id, 并记录了成功下载过的漫画章节名和基本信息.
-**排行榜上已下载过的漫画会触发增量下载,跳过曾下载过的章节**,其余所有情况都是全量下载所有章节.
-每次运行代码后,都会通过git actions的指令提交代码,保存本次的运行结果.`GIT_TOKEN`配置错误将导致提交代码失败,这会导致漫画被重复下载和推送
-
-
-### 过滤分区
-
-支持通过分区自定义下载逻辑.
-
-git actions配置文件的``CATEGORIES``配置项可以配置0~n个哔咔的分区, 配置为空则代表不过滤
-
-``CATEGORIES_RULE``可以配置为 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
-
-> 部分漫画只打上了'短篇'/'长篇'这样单个分区,在配置为``INCLUDE``时,建议把比较常见的分区给填上,不然容易匹配不到漫画
-
-
-### 订阅的时间范围
-对于订阅的漫画,如果 当天 - 订阅漫画的上传日 > `subscribe_days`,这本漫画将不再被下载
-
-
-### 日志文件
-在文件夹`logs`下存储有运行日志文件,所有日志按天自动划分,自动删除超过`backup_count`天的日志。错误信息单独保存到`ERROR_*.log`中。
-
# 结尾
[清心寡欲在平时,坚守临期凛四知,鸩酒岂堪求止渴,光明正大好男儿:thumbsup:](https://tieba.baidu.com/f?kw=%E6%88%92%E8%89%B2&ie=utf-8)
@@ -190,9 +128,9 @@ git actions配置文件的``CATEGORIES``配置项可以配置0~n个哔咔的分
| 2023/10/02 | 1.补充了上次更新没写进去的运行时间的保存逻辑:laughing: 2.改用total_seconds()判断时间差,seconds算出来的结果有误 3.修复了分卷压缩函数KeyError的问题--创建的压缩包个数 = 文件总大小/压缩包的最大大小,但分卷压缩时每个包都不会被填满的,导致实际需要更多的包 |
| 2023/09/12 | 修复了漫画曾被下载一次后, 新增章节无法被下载的bug. 现在记录了上次运行的时间, 与漫画章节的上传时间进行比对, 有新章节时则触发增量下载 |
| 2023/03/28 | 修复了调用分页获取章节接口时,只获取了第一页的bug,这会导致总章节数>40的漫画下载不全 |
-| 2023/02/03 | 参考了[jiayaoO3O/18-comic-finder](https://github.com/jiayaoO3O/18-comic-finder),现在可以在git actions上下载到完整的压缩包 |
-| 2023/02/01 | 1.区分了git actions和本地运行两种运行方式 2.新增按关键词订阅功能 3.调整了邮箱的配置项,支持指定加密方式和端口 4.引入`狗屁不通文章`生成邮件正文的随机字符串 |
-| 2023/01/06 | 基于git actions重构了代码,并采用了邮件的形式推送漫画 |
+| 2023/02/03 | 参考了[jiayaoO3O/18-comic-finder](https://github.com/jiayaoO3O/18-comic-finder),现在可以在GitHub Actions上下载到完整的压缩包 |
+| 2023/02/01 | 1.区分了GitHub Actions和本地运行两种运行方式 2.新增按关键词订阅功能 3.调整了邮箱的配置项,支持指定加密方式和端口 4.引入`狗屁不通文章`生成邮件正文的随机字符串 |
+| 2023/01/06 | 基于GitHub Actions重构了代码,并采用了邮件的形式推送漫画 |
| 2022/12/08 | 启动项目时自动打卡 |
| 2022/11/27 | 实现按排行榜以及收藏夹进行下载的功能 |
diff --git a/config/config.ini b/config/config.ini
new file mode 100644
index 00000000..38d0cc6f
--- /dev/null
+++ b/config/config.ini
@@ -0,0 +1,56 @@
+#按实际需求改param,filter这两节下的配置即可,其余配置不改不影响运行
+#请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub
+
+[param]
+#哔咔账户名称
+pica_account:
+#哔咔账户密码
+pica_password:
+#哔咔请求时的密钥 参考AnkiKong提供的secret_key https://zhuanlan.zhihu.com/p/547321040
+pica_secret_key:
+#在下载完成后,是否自动取消收藏(推荐为True,避免收藏夹下的漫画被重复下载)
+change_favourite: True
+#运行结束后发送自定义消息进行通知(可为空) 例: `https://api.day.app/{your_keys}/picacg下载成功`
+bark_url:
+#使用代理(为空则不使用代理)
+request_proxy:
+#将同一本漫画的不同章节进行合并
+merge_episodes: False
+
+#自定义过滤规则
+[filter]
+#过滤分区 具体的分区列表可以从client.py的categories方法中获取 为空则不过滤 用,分隔
+categories: CG雜圖,生肉,耽美花園,偽娘哲學,扶他樂園,性轉換,SAO 刀劍神域,WEBTOON,Cosplay
+#过滤规则 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
+categories_rule: EXCLUDE
+# 订阅的关键词,会下载x天范围内上传的漫画 为空则不订阅 用,分隔
+subscribe_keyword:
+# 订阅的x天范围 GitHub Actions运行时填小一点,免得漫画过多邮箱推送不了,本地运行时随便填
+subscribe_days: 60
+
+#下载相关的配置
+[crawl]
+#下载同一本漫画中若干图片的线程并发数.下载是IO密集型操作,可以考虑设置为比cpu核心数稍大一些的值
+concurrency: 5
+#每下载一本漫画的间隔时间(秒),在下载大量漫画时可以设置的稍微大一些,免得哔咔服务器响应不过来
+interval_time: 5
+#下载阶段是否输出细节信息
+detail: True
+#限制每次请求的最大时间(秒)
+request_time_out: 10
+# 保留最近?天的日志文件
+backup_count: 30
+
+#访问哔咔服务器的固定请求头
+[header]
+api-key: C69BAF41DA5ABD1FFEDC6D2FEA56B
+accept: application/vnd.picacomic.com.v1+json
+app-channel: 2
+nonce: b1ab87b4800d4d4590a11701b8551afa
+app-version: 2.2.1.2.3.3
+app-uuid: defaultUuid
+app-platform: android
+app-build-version: 45
+Content-Type: application/json; charset=UTF-8
+User-Agent: okhttp/3.8.1
+image-quality: original
diff --git a/config/config_backup.ini b/config/config_backup.ini
index 481ee0ca..eebe5cf5 100644
--- a/config/config_backup.ini
+++ b/config/config_backup.ini
@@ -1,8 +1,48 @@
+#请根据这个文件配置`./config/config.ini`
+#按实际需求改param,filter这两节下的配置即可,其余配置不改不影响运行
+#请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub
+
+[param]
+#哔咔账户名称
+pica_account:
+#哔咔账户密码
+pica_password:
+#哔咔请求时的密钥 参考AnkiKong提供的secret_key https://zhuanlan.zhihu.com/p/547321040
+pica_secret_key:
+#在下载完成后,是否自动取消收藏(推荐为True,避免收藏夹下的漫画被重复下载)
+change_favourite: True
+#运行结束后发送自定义消息进行通知,为空则不通知 例: `https://api.day.app/{your_keys}/picacg下载成功`
+bark_url:
+#使用代理(为空则不使用代理)
+request_proxy:
+#将同一本漫画的不同章节进行合并
+merge_episodes: False
+
+#自定义过滤规则
+[filter]
+# 过滤分区,示例中有目前所有的分区,最新的分区列表可以从client.py的categories方法中获取 为空则不过滤 用,分隔
+categories: 全彩,長篇,同人,短篇,圓神領域,碧藍幻想,CG雜圖,英語 ENG,生肉,純愛,百合花園,耽美花園,偽娘哲學,後宮閃光,扶他樂園,單行本,姐姐系,妹妹系,SM,性轉換,足の恋,人妻,NTR,強暴,非人類,艦隊收藏,Love Live,SAO 刀劍神域,Fate,東方,WEBTOON,禁書目錄,歐美,Cosplay,重口地帶
+#过滤规则 填了categories参数的话这个必填 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
+categories_rule: EXCLUDE
+# 订阅的关键词,会下载x天范围内上传的漫画 为空则不订阅 用,分隔
+subscribe_keyword:
+# 订阅的x天范围 GitHub Actions运行时填小一点,免得漫画过多邮箱推送不了,本地运行时随便填
+subscribe_days: 60
+
+#下载相关的配置
[crawl]
-#下载同一本的不同分页的图片的并发数,并不是多本同时并发下载 具体多少并发数自己定义
-concurrency = 5
+#下载同一本漫画中若干图片的线程并发数.下载是IO密集型操作,可以考虑设置为比cpu核心数稍大一些的值
+concurrency: 5
+#每下载一本漫画的间隔时间(秒),在下载大量漫画时可以设置的稍微大一些,免得哔咔服务器响应不过来
+interval_time: 5
+#下载阶段是否输出细节信息
+detail: True
+#限制每次请求的最大时间(秒)
+request_time_out: 10
+# 保留最近?天的日志文件
+backup_count: 30
-#固定的请求头
+#访问哔咔服务器的固定请求头
[header]
api-key: C69BAF41DA5ABD1FFEDC6D2FEA56B
accept: application/vnd.picacomic.com.v1+json
@@ -16,18 +56,3 @@ Content-Type: application/json; charset=UTF-8
User-Agent: okhttp/3.8.1
image-quality: original
-[param]
-#哔咔账户名称
-pica_account:
-#哔咔账户密码
-pica_password:
-#过滤分区 用,分隔
-categories: A,B
-#过滤规则 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
-categories_rule: EXCLUDE
-# 订阅的关键词,会下载x天范围内上传的漫画 为空则关闭关键词订阅 用,分隔
-subscribe_keyword: A,B
-# 订阅的x天范围 git actions运行时填小一点,免得漫画过多邮箱推送不了,本地运行时随便填
-subscribe_days: 60
-# 保留最近?天的日志文件
-backup_count: 30
diff --git a/docker-compose.yml b/docker-compose.yml
index fa902948..e6e69a4e 100644
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -4,19 +4,16 @@ services:
image: yuanzhangzcc/picacg-download:latest
container_name: picacg-download-container
volumes:
- - ./comics/bika:/app/comics
+ - ./comics:/app/comics
- ./output:/app/output
- ./logs:/app/logs
- ./data:/app/data
- ./config:/app/config
environment:
- - PICA_SECRET_KEY=~d}$$Q7$$eIni=V)9\RK/P.RM4;9[7|@/CA}b~OW!3?EV`:<>M7pddUBL5n|0/*Cn #$字符存在转义问题,将密钥里的$替换为$$
+ - PICA_SECRET_KEY= #Dockerfile设置环境变量时,$字符好像存在转义问题,需要将密钥里的$替换为$$
- REQUEST_PROXY= #下载图片代理
- PACKAGE_TYPE=True #是否打包为zip, 推荐True
- - INTERVAL_TIME=5 #每下载一本漫画的间隔时间(秒)
- - REQUEST_TIME_OUT=10 #URL请求时间限制
- - DETAIL=False #是否打印详细信息
- - CHANGE_FAVOURITE=False #是否删除收藏夹内容
- DELETE_COMIC=False #是否打包后删除漫画
+ - CHANGE_FAVOURITE=False #是否删除收藏夹内容
- BARK_URL= #下载完成消息通知
restart: unless-stopped
diff --git a/src/client.py b/src/client.py
index a088a2ff..9da362e3 100644
--- a/src/client.py
+++ b/src/client.py
@@ -30,19 +30,19 @@ def __init__(self) -> None:
parser = ConfigParser()
parser.read('./config/config.ini', encoding='utf-8')
self.headers = dict(parser.items('header'))
- self.timeout = int(os.environ.get("REQUEST_TIME_OUT", 10))
+ self.timeout = int(get_cfg("crawl", "request_time_out", 10))
def http_do(self, method, url, **kwargs):
kwargs.setdefault("allow_redirects", True)
header = self.headers.copy()
ts = str(int(time()))
raw = url.replace(base, "") + str(ts) + header["nonce"] + method + header["api-key"]
- hc = hmac.new(os.environ["PICA_SECRET_KEY"].encode(), digestmod=hashlib.sha256)
+ hc = hmac.new(get_cfg("param", "pica_secret_key").encode(), digestmod=hashlib.sha256)
hc.update(raw.lower().encode())
header["signature"] = hc.hexdigest()
header["time"] = ts
kwargs.setdefault("headers", header)
- proxy = os.environ.get("REQUEST_PROXY")
+ proxy = get_cfg("param", "request_proxy")
if proxy:
proxies = {'http': proxy, 'https': proxy}
else:
@@ -153,7 +153,7 @@ def search_all(self, keyword):
datetime.now() -
datetime.strptime(comic["updated_at"], "%Y-%m-%dT%H:%M:%S.%fZ")
).days
- ) <= int(get_cfg('param', 'subscribe_days'))]
+ ) <= int(get_cfg('filter', 'subscribe_days'))]
subscribed_comics += recent_comics
# Check if any comics in the current page exceed the subscribe time limit.
diff --git a/src/data_migration.py b/src/data_migration.py
index ce39ea4b..85e00913 100644
--- a/src/data_migration.py
+++ b/src/data_migration.py
@@ -35,9 +35,9 @@
author = comic["author"]
episodes = pica_server.episodes_all(cid, title)
if episodes:
+ mark_comic_as_downloaded(cid, title)
for episode in episodes:
- mark_comic_as_downloaded(cid, title)
update_downloaded_episodes(cid, episode["title"], db_path)
- update_comic_data(comic, db_path)
+ update_comic_data(comic, db_path)
else:
print(f'该漫画可能已被删除,{cid}')
diff --git a/src/main.py b/src/main.py
index 6ae15bf2..a0e679f6 100644
--- a/src/main.py
+++ b/src/main.py
@@ -1,20 +1,18 @@
# encoding: utf-8
import io
-import json
import sys
-import threading
import time
-import traceback
-import shutil
-import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
-import logging
from logging.handlers import TimedRotatingFileHandler
from pathlib import Path
from client import Pica
from util import *
+#校验config.ini文件是否存在
+config_dir = './config/config.ini'
+if not os.path.isfile('./config/config.ini'):
+ raise Exception(f"配置文件`{config_dir}`不存在,请参考`./config/config_backup.ini`进行配置")
# 配置日志
log_folder = './logs'
@@ -30,7 +28,7 @@ def get_log_filename(name):
get_log_filename('runing'),
when='midnight', # 每天轮转一次
interval=1, # 轮转周期为1天
- backupCount=int(get_cfg('param', 'backup_count')) # 保留最近?天的日志文件
+ backupCount=int(get_cfg('crawl', 'backup_count', 30)) # 保留最近?天的日志文件
)
log_handler.setLevel(logging.INFO)
log_handler.setFormatter(log_formatter)
@@ -41,7 +39,7 @@ def get_log_filename(name):
get_log_filename('ERROR'),
when='midnight', # 每天轮转一次
interval=1, # 轮转周期为1天
- backupCount=int(get_cfg('param', 'backup_count')) # 保留最近?天的日志文件
+ backupCount=int(get_cfg('crawl', 'backup_count', 30)) # 保留最近?天的日志文件
)
error_log_handler.setLevel(logging.ERROR) # 只记录 ERROR 级别及以上的日志
error_log_handler.setFormatter(log_formatter)
@@ -56,13 +54,13 @@ def get_log_filename(name):
# only_latest: true增量下载 false全量下载
-def download_comic(comic, db_path, only_latest):
+def download_comic(comic, db_path, only_latest, executor: ThreadPoolExecutor):
cid = comic["_id"]
title = comic["title"]
author = comic["author"]
categories = comic["categories"]
episodes = pica_server.episodes_all(cid, title)
- is_detail = os.environ.get("DETAIL", "False") == "True"
+ is_detail = get_cfg("crawl", "detail", "True") == "True"
num_pages = comic["pagesCount"] if "pagesCount" in comic else -1
# 增量更新
if only_latest:
@@ -81,17 +79,15 @@ def download_comic(comic, db_path, only_latest):
comic_path = os.path.join(".",
"comics",
f"{convert_file_name(author)}",
- (f"[{convert_file_name(title)}]"
- f"[{convert_file_name(author)}]"
- f"[{convert_file_name(categories)}]")
+ f"{convert_file_name(title)}"
)
comic_path = ensure_valid_path(comic_path)
+
for episode in episodes:
chapter_title = convert_file_name(episode["title"])
chapter_path = os.path.join(comic_path, chapter_title)
chapter_path = Path(chapter_path)
chapter_path.mkdir(parents=True, exist_ok=True)
-
image_urls = []
current_page = 1
while True:
@@ -101,7 +97,7 @@ def download_comic(comic, db_path, only_latest):
current_page += 1
if page_data:
image_urls.extend(list(map(
- lambda i: i['media']['fileServer'] + '/static/' + i['media']['path'],
+ lambda i: i['media']['fileServer'] + '/static/' + i['media']['path'],
page_data
)))
else:
@@ -110,40 +106,36 @@ def download_comic(comic, db_path, only_latest):
logging.error(f"No images found of chapter:{chapter_title} in comic:{title}")
continue
- concurrency = int(get_cfg('crawl', 'concurrency'))
- image_urls_parts = list_partition(image_urls, concurrency)
- downloaded_count = 0.
- for image_urls_part in image_urls_parts:
- with ThreadPoolExecutor(max_workers=concurrency) as executor:
- futures = {
- executor.submit(download,
- pica_server, chapter_path,
- image_urls.index(image_url), image_url
- ): image_url
- for image_url in image_urls_part
- }
- for future in as_completed(futures):
- image_url = futures[future]
- try:
- future.result()
- downloaded_count += 1
- except Exception as e:
- current_image = image_urls.index(image_url) + 1
- episode_title = episode["title"]
- logging.error(f"Error downloading the {current_image}-th image"
- f"in episode:{episode_title}"
- f"in comic:{title}"
- f"Exception:{e}")
- continue
- if is_detail:
+ downloaded_count = 0
+ futures = {
+ executor.submit(download,
+ pica_server, chapter_path,
+ image_urls.index(image_url), image_url
+ ): image_url
+ for image_url in image_urls
+ }
+ for future in as_completed(futures):
+ image_url = futures[future]
+ try:
+ future.result()
+ downloaded_count += 1
+ except Exception as e:
+ current_image = image_urls.index(image_url) + 1
episode_title = episode["title"]
- print(
- f"[episode:{episode_title:<10}] "
- f"downloaded:{downloaded_count:>6}, "
- f"total:{len(image_urls):>4}, "
- f"progress:{int(downloaded_count / len(image_urls) * 100):>3}%",
- flush=True
- )
+ logging.error(f"Error downloading the {current_image}-th image"
+ f"in episode:{episode_title}"
+ f"in comic:{title}"
+ f"Exception:{e}")
+ continue
+ if is_detail:
+ episode_title = episode["title"]
+ print(
+ f"[episode:{episode_title:<10}] "
+ f"downloaded:{downloaded_count:>6}, "
+ f"total:{len(image_urls):>4}, "
+ f"progress:{int(downloaded_count / len(image_urls) * 100):>3}%",
+ flush=True
+ )
if downloaded_count == len(image_urls):
update_downloaded_episodes(cid, episode["title"], db_path)
else:
@@ -154,10 +146,11 @@ def download_comic(comic, db_path, only_latest):
f"Currently, {downloaded_count} images(total_images:{len(image_urls)}) "
"from this episode have been downloaded"
)
-
+ # 下载完成后,根据配置对漫画章节进行合并
+ if get_cfg("param", "merge_episodes", "False") == "True":
+ merge_episodes(comic_path)
# 下载每本漫画的间隔时间
- if os.environ.get("INTERVAL_TIME"):
- time.sleep(int(os.environ.get("INTERVAL_TIME")))
+ time.sleep(int(get_cfg('crawl', "interval_time", 1)))
# 登录并打卡
@@ -174,7 +167,7 @@ def download_comic(comic, db_path, only_latest):
# 关键词订阅的漫画
searched_comics = []
-keywords = get_cfg('param', 'subscribe_keyword').split(',')
+keywords = get_cfg('filter', 'subscribe_keyword').split(',')
for keyword in keywords:
searched_comics_ = pica_server.search_all(keyword)
print('关键词%s: 检索到%d本漫画' % (keyword, len(searched_comics_)), flush=True)
@@ -184,28 +177,31 @@ def download_comic(comic, db_path, only_latest):
favourited_comics = pica_server.my_favourite_all()
print('已下载共计%d本漫画' % get_downloaded_comic_count(db_path), flush=True)
print('收藏夹共计%d本漫画' % (len(favourited_comics)), flush=True)
-isChangeFavo = os.environ.get("CHANGE_FAVOURITE", False) == "True"
-
-for comic in (ranked_comics + favourited_comics + searched_comics):
- try:
- # 收藏夹:全量下载 其余:增量下载
- download_comic(comic, db_path, comic not in favourited_comics)
- info = pica_server.comic_info(comic['_id'])
- # 收藏夹中的漫画被下载后,自动取消收藏,避免下次运行时重复下载
- if info["data"]['comic']['isFavourite'] and isChangeFavo:
- pica_server.favourite(comic["_id"])
- update_comic_data(comic, db_path)
- except Exception as e:
- logging.error(
- 'Download failed for {}, with Exception:{}'.format(comic["title"], e)
- )
- continue
+isChangeFavo = get_cfg("param", "change_favourite", "True") == "True"
+
+concurrency = int(get_cfg('crawl', 'concurrency', 5))
+# 创建线程池的代码不要放for循环里面
+with ThreadPoolExecutor(max_workers=concurrency) as executor:
+ for comic in (ranked_comics + favourited_comics + searched_comics):
+ try:
+ # 收藏夹:全量下载 其余:增量下载
+ download_comic(comic, db_path, comic not in favourited_comics, executor)
+ info = pica_server.comic_info(comic['_id'])
+ # 在收藏夹的漫画下载完成后,根据配置决定是否需要自动取消收藏,避免下次运行时重复下载
+ if info["data"]['comic']['isFavourite'] and isChangeFavo:
+ pica_server.favourite(comic["_id"])
+ update_comic_data(comic, db_path)
+ except Exception as e:
+ logging.error(
+ 'Download failed for {}, with Exception:{}'.format(comic["title"], e)
+ )
+ continue
# 打包成zip文件, 并删除旧数据 , 删除comics文件夹会导致docker挂载报错
if os.environ.get("PACKAGE_TYPE", "False") == "True":
- print("The comic is being packaged")
for folderName in os.listdir('./comics'):
+ print(f"The comic [{folderName}] is being packaged")
folder_path = os.path.join('./comics', folderName)
if os.path.isdir(folder_path):
for chapter_folder in os.listdir(folder_path):
@@ -217,8 +213,8 @@ def download_comic(comic, db_path, only_latest):
# delete folders in comics
if os.environ.get("DELETE_COMIC", "True") == "True":
- print("The comic is being deleted")
for fileName in os.listdir('./comics'):
+ print(f"The comic [{fileName}] is being deleted")
file_path = os.path.join('./comics', fileName)
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path)
@@ -227,9 +223,10 @@ def download_comic(comic, db_path, only_latest):
# 发送消息通知
-if os.environ.get("BARK_URL"):
+bark_url = get_cfg("param", "bark_url")
+if bark_url:
requests.get(
- os.environ.get("BARK_URL") + " " +
+ bark_url + " " +
f"排行榜漫画共计{len(ranked_comics)}" +
f"关键词漫画共计{len(searched_comics)}" +
f"收藏夹漫画共计{len(favourited_comics)}"
diff --git a/src/mergeComic.py b/src/mergeComic.py
deleted file mode 100644
index 68e9238e..00000000
--- a/src/mergeComic.py
+++ /dev/null
@@ -1,32 +0,0 @@
-# 合并多个本子,将同一本放入相同文件夹,按章节顺序升序命名文件夹
-
-import os
-import shutil
-
-from pip._vendor.distlib.compat import raw_input
-
-path = './zips/'
-if not os.path.exists(path):
- os.makedirs(path)
-
-target = raw_input("目标目录:")
-if not os.path.exists(path + target):
- os.makedirs(path + target)
-
-target_files = os.listdir(path + target)
-target_files.sort(key=lambda x: str(x.split('.')[0]))
-index = 1 if not target_files else int(target_files[-1].split('.')[0]) + 1
-
-dirs = os.listdir(path)
-dirs.remove(target)
-for i in range(len(dirs)):
- d = dirs[i]
- pics = os.listdir(path + d)
- pics.sort(key=lambda x: str(x.split('.')[0]))
-
- source = path + d + '/'
- for p in pics:
- os.rename(source + p, path + target + '/' + str(index).zfill(4) + '.jpg')
- index += 1
- shutil.rmtree(source)
- print('merge finished,' + d + ' removed------------------------------------', flush=True)
diff --git a/src/util.py b/src/util.py
index 910193f8..271bf9f1 100644
--- a/src/util.py
+++ b/src/util.py
@@ -1,6 +1,7 @@
import operator
import os
import random
+import shutil
import zipfile
from configparser import ConfigParser
from datetime import datetime
@@ -13,22 +14,33 @@
def convert_file_name(name: str) -> str:
if isinstance(name, list):
name = "&".join(map(str, name))
- # windows的文件夹不能带特殊字符,需要处理下文件夹名
+ # 处理文件夹名中的特殊字符
for i, j in ("//", "\\\", "??", "|︱", "\""", "**", "<<", ">>", ":-"):
name = name.replace(i, j)
name = name.replace(" ", "")
+ # 操作系统对文件夹名最大长度有限制,这里对超长部分进行截断,避免file name too long报错
+ # linux是255字节,windows更大一些
+ name = truncate_string_by_bytes(name, 255)
return name
+# 该方法的配置读取优先级为 环境变量 > config.ini > default_value默认值
+# docker方式部署时, 只需配置环境变量, 无需重新构建镜像
+# GitHub Actions方式部署时, 部分敏感信息不适合填进config.ini文件并上传至代码仓库, 也请配置进环境变量中
+def get_cfg(section: str, key: str, default_value = ''):
+ # 项目中用到的环境变量名统一是大写的, 这里对入参key做了大写转换
+ config_value = os.environ.get(key.upper())
+ if config_value:
+ return config_value
-def get_cfg(section: str, key: str):
+ # 因为ConfigParser限制变量名是小写的, 在读取config.ini的配置,对入参key做了小写转换
parser = ConfigParser()
parser.read('./config/config.ini', encoding='utf-8')
- config_value = dict(parser.items(section))[key]
+ config_value = dict(parser.items(section))[key.lower()]
if config_value:
return config_value
- #如果是用git actions方式部署,部分敏感信息不适合填进config.ini文件并上传至代码仓库,此时可以从从环境变量取值作为兜底
- #ConfigParser读写配置项是按小写来的,但linux环境变量又是大小写敏感的.这里把入参key做了大写转换
- return os.environ[key.upper()]
+
+ # 最后取默认值作为兜底
+ return default_value
def get_latest_run_time():
@@ -44,11 +56,11 @@ def get_latest_run_time():
def filter_comics(comic, episodes, db_path) -> list:
# 已下载过的漫画,执行增量更新
if is_comic_downloaded(comic["_id"], db_path):
- episodes = [episode for episode in episodes
+ episodes = [episode for episode in episodes
if not is_episode_downloaded(comic["_id"], episode["title"], db_path)]
# 过滤掉指定分区的本子
- categories_rule = get_cfg('param', 'categories_rule')
- categories = get_cfg('param', 'categories').split(',')
+ categories_rule = get_cfg('filter', 'categories_rule')
+ categories = get_cfg('filter', 'categories').split(',')
# 漫画的分区和用户自定义分区的交集
intersection = set(comic['categories']).intersection(set(categories))
if categories:
@@ -345,3 +357,87 @@ def ensure_valid_path(path):
print(f"Path too long, truncating: {path}")
path = path[:(max_path_length)] # 截断路径
return path
+
+def truncate_string_by_bytes(s, max_bytes):
+ """
+ 截断字符串,使其字节长度不超过max_bytes。
+
+ 参数:
+ s (str): 要截断的字符串。
+ max_bytes (int): 字符串的最大字节长度。
+
+ 返回:
+ str: 截断后的字符串。
+ """
+ # 将字符串编码为字节串(默认使用utf-8编码)
+ encoded_str = s.encode('utf-8')
+
+ # 检查字节串的长度
+ if len(encoded_str) > max_bytes:
+ # 截断字节串
+ truncated_bytes = encoded_str[:max_bytes]
+
+ # 确保截断后的字节串是一个有效的UTF-8编码(可能需要移除最后一个字节以形成完整的字符)
+ # 这通过解码然后重新编码来实现,可能会丢失最后一个字符的一部分
+ truncated_str = truncated_bytes.decode('utf-8', 'ignore').encode('utf-8')
+
+ # 返回截断后的字符串(以字节形式编码然后解码回字符串)
+ return truncated_str.decode('utf-8')
+ else:
+ # 如果不需要截断,则返回原始字符串
+ return s
+
+def merge_episodes(dir):
+ """
+ 将漫画从各个章节子文件夹中提取出来, 合并到同一目录, 方便连续阅读
+ 合并前的目录结构: ./comics/漫画标题/章节名/图片
+ 合并后的目录结构: ./comics/漫画标题/图片
+
+ 参数:
+ dir (str): 漫画所在文件夹
+ """
+
+ # 获取目标目录下的所有子文件夹(章节信息),按章节名排序
+ subdirs = sorted([d for d in os.listdir(dir) if os.path.isdir(os.path.join(dir, d))])
+
+ # 存储每个子文件夹中的文件数量
+ counts = []
+
+ # 存储所有文件的完整路径,以便后续处理
+ all_files = []
+
+ # 遍历子文件夹,计算文件数量并收集文件路径
+ for subdir in subdirs:
+ subdir_path = os.path.join(dir, subdir)
+ count = len([f for f in os.listdir(subdir_path) if os.path.isfile(os.path.join(subdir_path, f))])
+ counts.append(count)
+
+ # 获取章节下的所有图片,按图片名排序
+ pics = os.listdir(subdir_path)
+ pics.sort(key=lambda x: str(x.split('.')[0]))
+ for filename in pics:
+ if os.path.isfile(os.path.join(subdir_path, filename)):
+ all_files.append((os.path.join(subdir_path, filename), subdir, count))
+
+ # 确定最大文件数量,用于确定文件名填充宽度
+ max_count = sum(counts) if counts else 0
+ width = len(str(max_count))
+ # 初始化全局文件计数器
+ global_counter = 1
+
+ # 遍历所有文件,复制并重命名
+ for src_file, subdir, count in all_files:
+ # 生成新的文件名,使用宽度进行零填充
+ new_filename = f"{global_counter:0{width}d}{os.path.splitext(src_file)[1]}"
+
+ # 复制文件到目标目录(这里直接复制到dir)
+ shutil.copy2(src_file, os.path.join(dir, new_filename))
+
+ # 更新全局计数器
+ global_counter += 1
+
+ # 删除各个章节的文件夹
+ for subdir in subdirs:
+ shutil.rmtree(os.path.join(dir,subdir))
+
+ print(f"{dir}合并章节完成,共处理了 {global_counter - 1} 个文件")
\ No newline at end of file
* [我自己也fork了一份](https://github.com/PhantomStrikers/pica_crawler.git),每天都在自动运行的,可以通过这个项目的actions运行记录判断这个项目是否还能work
-
-# 解压注意事项
+### 邮件压缩包的解压注意事项
1. 将所有邮件的压缩包下载至统一目录. (存在单个压缩包里可能只有半本漫画的情况),然后**全选**压缩包,右键**解压到当前文件夹**.
-2. 如果你在上个步骤选择右键解压文件,默认是以压缩包名创建一个新的文件夹,会出现漫画拆散在不同文件夹的情况
+2. 如果你在上个步骤选择右键**解压文件**,默认是以压缩包名创建一个新的文件夹,会出现漫画被拆散在不同文件夹的情况
3. 压缩包默认zip格式,无解压密码.遇到解不开的情况可能是下载时压缩包损坏了,尝试下重新下载
-# 下载的范围
-
-## 排行榜
-哔咔24小时排行榜内的所有漫画
-
-## 收藏夹
-收藏夹内的所有漫画,下载完成是否取消收藏取决于环境变量`CHANGE_FAVOURITE`, if ="True":自动取消收藏; elif ="False":不取消收藏
-
-## 关键词订阅
-`./config/config.ini`里的`subscribe_keyword`里配置若干个关键词,下载范围等同于在哔咔app里用关键词搜索到的所有漫画
-这个功能可能会下载过量的漫画,导致邮箱无法推送,可以调整`subscribe_days`缩小下载范围,或者是本地运行`main.py`
-
-# 部分漫画不会被下载的原因
-排行榜/订阅的漫画会受到以下过滤逻辑的影响,**收藏夹则不会**(如果下载到本地后文件丢失了,可以通过放入收藏夹把它全量下载下来)
-
-
-### 过滤重复下载
-
-`./data/downloaded.db`文件记录了已扫描过的漫画id, 并记录了成功下载过的漫画章节名和基本信息.
-**排行榜上已下载过的漫画会触发增量下载,跳过曾下载过的章节**,其余所有情况都是全量下载所有章节.
-每次运行代码后,都会通过git actions的指令提交代码,保存本次的运行结果.`GIT_TOKEN`配置错误将导致提交代码失败,这会导致漫画被重复下载和推送
-
-
-### 过滤分区
-
-支持通过分区自定义下载逻辑.
-
-git actions配置文件的``CATEGORIES``配置项可以配置0~n个哔咔的分区, 配置为空则代表不过滤
-
-``CATEGORIES_RULE``可以配置为 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
-
-> 部分漫画只打上了'短篇'/'长篇'这样单个分区,在配置为``INCLUDE``时,建议把比较常见的分区给填上,不然容易匹配不到漫画
-
-
-### 订阅的时间范围
-对于订阅的漫画,如果 当天 - 订阅漫画的上传日 > `subscribe_days`,这本漫画将不再被下载
-
-
-### 日志文件
-在文件夹`logs`下存储有运行日志文件,所有日志按天自动划分,自动删除超过`backup_count`天的日志。错误信息单独保存到`ERROR_*.log`中。
-
# 结尾
[清心寡欲在平时,坚守临期凛四知,鸩酒岂堪求止渴,光明正大好男儿:thumbsup:](https://tieba.baidu.com/f?kw=%E6%88%92%E8%89%B2&ie=utf-8)
@@ -190,9 +128,9 @@ git actions配置文件的``CATEGORIES``配置项可以配置0~n个哔咔的分
| 2023/10/02 | 1.补充了上次更新没写进去的运行时间的保存逻辑:laughing: 2.改用total_seconds()判断时间差,seconds算出来的结果有误 3.修复了分卷压缩函数KeyError的问题--创建的压缩包个数 = 文件总大小/压缩包的最大大小,但分卷压缩时每个包都不会被填满的,导致实际需要更多的包 |
| 2023/09/12 | 修复了漫画曾被下载一次后, 新增章节无法被下载的bug. 现在记录了上次运行的时间, 与漫画章节的上传时间进行比对, 有新章节时则触发增量下载 |
| 2023/03/28 | 修复了调用分页获取章节接口时,只获取了第一页的bug,这会导致总章节数>40的漫画下载不全 |
-| 2023/02/03 | 参考了[jiayaoO3O/18-comic-finder](https://github.com/jiayaoO3O/18-comic-finder),现在可以在git actions上下载到完整的压缩包 |
-| 2023/02/01 | 1.区分了git actions和本地运行两种运行方式 2.新增按关键词订阅功能 3.调整了邮箱的配置项,支持指定加密方式和端口 4.引入`狗屁不通文章`生成邮件正文的随机字符串 |
-| 2023/01/06 | 基于git actions重构了代码,并采用了邮件的形式推送漫画 |
+| 2023/02/03 | 参考了[jiayaoO3O/18-comic-finder](https://github.com/jiayaoO3O/18-comic-finder),现在可以在GitHub Actions上下载到完整的压缩包 |
+| 2023/02/01 | 1.区分了GitHub Actions和本地运行两种运行方式 2.新增按关键词订阅功能 3.调整了邮箱的配置项,支持指定加密方式和端口 4.引入`狗屁不通文章`生成邮件正文的随机字符串 |
+| 2023/01/06 | 基于GitHub Actions重构了代码,并采用了邮件的形式推送漫画 |
| 2022/12/08 | 启动项目时自动打卡 |
| 2022/11/27 | 实现按排行榜以及收藏夹进行下载的功能 |
diff --git a/config/config.ini b/config/config.ini
new file mode 100644
index 00000000..38d0cc6f
--- /dev/null
+++ b/config/config.ini
@@ -0,0 +1,56 @@
+#按实际需求改param,filter这两节下的配置即可,其余配置不改不影响运行
+#请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub
+
+[param]
+#哔咔账户名称
+pica_account:
+#哔咔账户密码
+pica_password:
+#哔咔请求时的密钥 参考AnkiKong提供的secret_key https://zhuanlan.zhihu.com/p/547321040
+pica_secret_key:
+#在下载完成后,是否自动取消收藏(推荐为True,避免收藏夹下的漫画被重复下载)
+change_favourite: True
+#运行结束后发送自定义消息进行通知(可为空) 例: `https://api.day.app/{your_keys}/picacg下载成功`
+bark_url:
+#使用代理(为空则不使用代理)
+request_proxy:
+#将同一本漫画的不同章节进行合并
+merge_episodes: False
+
+#自定义过滤规则
+[filter]
+#过滤分区 具体的分区列表可以从client.py的categories方法中获取 为空则不过滤 用,分隔
+categories: CG雜圖,生肉,耽美花園,偽娘哲學,扶他樂園,性轉換,SAO 刀劍神域,WEBTOON,Cosplay
+#过滤规则 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
+categories_rule: EXCLUDE
+# 订阅的关键词,会下载x天范围内上传的漫画 为空则不订阅 用,分隔
+subscribe_keyword:
+# 订阅的x天范围 GitHub Actions运行时填小一点,免得漫画过多邮箱推送不了,本地运行时随便填
+subscribe_days: 60
+
+#下载相关的配置
+[crawl]
+#下载同一本漫画中若干图片的线程并发数.下载是IO密集型操作,可以考虑设置为比cpu核心数稍大一些的值
+concurrency: 5
+#每下载一本漫画的间隔时间(秒),在下载大量漫画时可以设置的稍微大一些,免得哔咔服务器响应不过来
+interval_time: 5
+#下载阶段是否输出细节信息
+detail: True
+#限制每次请求的最大时间(秒)
+request_time_out: 10
+# 保留最近?天的日志文件
+backup_count: 30
+
+#访问哔咔服务器的固定请求头
+[header]
+api-key: C69BAF41DA5ABD1FFEDC6D2FEA56B
+accept: application/vnd.picacomic.com.v1+json
+app-channel: 2
+nonce: b1ab87b4800d4d4590a11701b8551afa
+app-version: 2.2.1.2.3.3
+app-uuid: defaultUuid
+app-platform: android
+app-build-version: 45
+Content-Type: application/json; charset=UTF-8
+User-Agent: okhttp/3.8.1
+image-quality: original
diff --git a/config/config_backup.ini b/config/config_backup.ini
index 481ee0ca..eebe5cf5 100644
--- a/config/config_backup.ini
+++ b/config/config_backup.ini
@@ -1,8 +1,48 @@
+#请根据这个文件配置`./config/config.ini`
+#按实际需求改param,filter这两节下的配置即可,其余配置不改不影响运行
+#请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub 请不要将哔咔账密/哔咔密钥等敏感信息上传至GitHub
+
+[param]
+#哔咔账户名称
+pica_account:
+#哔咔账户密码
+pica_password:
+#哔咔请求时的密钥 参考AnkiKong提供的secret_key https://zhuanlan.zhihu.com/p/547321040
+pica_secret_key:
+#在下载完成后,是否自动取消收藏(推荐为True,避免收藏夹下的漫画被重复下载)
+change_favourite: True
+#运行结束后发送自定义消息进行通知,为空则不通知 例: `https://api.day.app/{your_keys}/picacg下载成功`
+bark_url:
+#使用代理(为空则不使用代理)
+request_proxy:
+#将同一本漫画的不同章节进行合并
+merge_episodes: False
+
+#自定义过滤规则
+[filter]
+# 过滤分区,示例中有目前所有的分区,最新的分区列表可以从client.py的categories方法中获取 为空则不过滤 用,分隔
+categories: 全彩,長篇,同人,短篇,圓神領域,碧藍幻想,CG雜圖,英語 ENG,生肉,純愛,百合花園,耽美花園,偽娘哲學,後宮閃光,扶他樂園,單行本,姐姐系,妹妹系,SM,性轉換,足の恋,人妻,NTR,強暴,非人類,艦隊收藏,Love Live,SAO 刀劍神域,Fate,東方,WEBTOON,禁書目錄,歐美,Cosplay,重口地帶
+#过滤规则 填了categories参数的话这个必填 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
+categories_rule: EXCLUDE
+# 订阅的关键词,会下载x天范围内上传的漫画 为空则不订阅 用,分隔
+subscribe_keyword:
+# 订阅的x天范围 GitHub Actions运行时填小一点,免得漫画过多邮箱推送不了,本地运行时随便填
+subscribe_days: 60
+
+#下载相关的配置
[crawl]
-#下载同一本的不同分页的图片的并发数,并不是多本同时并发下载 具体多少并发数自己定义
-concurrency = 5
+#下载同一本漫画中若干图片的线程并发数.下载是IO密集型操作,可以考虑设置为比cpu核心数稍大一些的值
+concurrency: 5
+#每下载一本漫画的间隔时间(秒),在下载大量漫画时可以设置的稍微大一些,免得哔咔服务器响应不过来
+interval_time: 5
+#下载阶段是否输出细节信息
+detail: True
+#限制每次请求的最大时间(秒)
+request_time_out: 10
+# 保留最近?天的日志文件
+backup_count: 30
-#固定的请求头
+#访问哔咔服务器的固定请求头
[header]
api-key: C69BAF41DA5ABD1FFEDC6D2FEA56B
accept: application/vnd.picacomic.com.v1+json
@@ -16,18 +56,3 @@ Content-Type: application/json; charset=UTF-8
User-Agent: okhttp/3.8.1
image-quality: original
-[param]
-#哔咔账户名称
-pica_account:
-#哔咔账户密码
-pica_password:
-#过滤分区 用,分隔
-categories: A,B
-#过滤规则 INCLUDE: 包含任意一个分区就下载 EXCLUDE: 包含任意一个分区就不下载
-categories_rule: EXCLUDE
-# 订阅的关键词,会下载x天范围内上传的漫画 为空则关闭关键词订阅 用,分隔
-subscribe_keyword: A,B
-# 订阅的x天范围 git actions运行时填小一点,免得漫画过多邮箱推送不了,本地运行时随便填
-subscribe_days: 60
-# 保留最近?天的日志文件
-backup_count: 30
diff --git a/docker-compose.yml b/docker-compose.yml
index fa902948..e6e69a4e 100644
--- a/docker-compose.yml
+++ b/docker-compose.yml
@@ -4,19 +4,16 @@ services:
image: yuanzhangzcc/picacg-download:latest
container_name: picacg-download-container
volumes:
- - ./comics/bika:/app/comics
+ - ./comics:/app/comics
- ./output:/app/output
- ./logs:/app/logs
- ./data:/app/data
- ./config:/app/config
environment:
- - PICA_SECRET_KEY=~d}$$Q7$$eIni=V)9\RK/P.RM4;9[7|@/CA}b~OW!3?EV`:<>M7pddUBL5n|0/*Cn #$字符存在转义问题,将密钥里的$替换为$$
+ - PICA_SECRET_KEY= #Dockerfile设置环境变量时,$字符好像存在转义问题,需要将密钥里的$替换为$$
- REQUEST_PROXY= #下载图片代理
- PACKAGE_TYPE=True #是否打包为zip, 推荐True
- - INTERVAL_TIME=5 #每下载一本漫画的间隔时间(秒)
- - REQUEST_TIME_OUT=10 #URL请求时间限制
- - DETAIL=False #是否打印详细信息
- - CHANGE_FAVOURITE=False #是否删除收藏夹内容
- DELETE_COMIC=False #是否打包后删除漫画
+ - CHANGE_FAVOURITE=False #是否删除收藏夹内容
- BARK_URL= #下载完成消息通知
restart: unless-stopped
diff --git a/src/client.py b/src/client.py
index a088a2ff..9da362e3 100644
--- a/src/client.py
+++ b/src/client.py
@@ -30,19 +30,19 @@ def __init__(self) -> None:
parser = ConfigParser()
parser.read('./config/config.ini', encoding='utf-8')
self.headers = dict(parser.items('header'))
- self.timeout = int(os.environ.get("REQUEST_TIME_OUT", 10))
+ self.timeout = int(get_cfg("crawl", "request_time_out", 10))
def http_do(self, method, url, **kwargs):
kwargs.setdefault("allow_redirects", True)
header = self.headers.copy()
ts = str(int(time()))
raw = url.replace(base, "") + str(ts) + header["nonce"] + method + header["api-key"]
- hc = hmac.new(os.environ["PICA_SECRET_KEY"].encode(), digestmod=hashlib.sha256)
+ hc = hmac.new(get_cfg("param", "pica_secret_key").encode(), digestmod=hashlib.sha256)
hc.update(raw.lower().encode())
header["signature"] = hc.hexdigest()
header["time"] = ts
kwargs.setdefault("headers", header)
- proxy = os.environ.get("REQUEST_PROXY")
+ proxy = get_cfg("param", "request_proxy")
if proxy:
proxies = {'http': proxy, 'https': proxy}
else:
@@ -153,7 +153,7 @@ def search_all(self, keyword):
datetime.now() -
datetime.strptime(comic["updated_at"], "%Y-%m-%dT%H:%M:%S.%fZ")
).days
- ) <= int(get_cfg('param', 'subscribe_days'))]
+ ) <= int(get_cfg('filter', 'subscribe_days'))]
subscribed_comics += recent_comics
# Check if any comics in the current page exceed the subscribe time limit.
diff --git a/src/data_migration.py b/src/data_migration.py
index ce39ea4b..85e00913 100644
--- a/src/data_migration.py
+++ b/src/data_migration.py
@@ -35,9 +35,9 @@
author = comic["author"]
episodes = pica_server.episodes_all(cid, title)
if episodes:
+ mark_comic_as_downloaded(cid, title)
for episode in episodes:
- mark_comic_as_downloaded(cid, title)
update_downloaded_episodes(cid, episode["title"], db_path)
- update_comic_data(comic, db_path)
+ update_comic_data(comic, db_path)
else:
print(f'该漫画可能已被删除,{cid}')
diff --git a/src/main.py b/src/main.py
index 6ae15bf2..a0e679f6 100644
--- a/src/main.py
+++ b/src/main.py
@@ -1,20 +1,18 @@
# encoding: utf-8
import io
-import json
import sys
-import threading
import time
-import traceback
-import shutil
-import requests
from concurrent.futures import ThreadPoolExecutor, as_completed
-import logging
from logging.handlers import TimedRotatingFileHandler
from pathlib import Path
from client import Pica
from util import *
+#校验config.ini文件是否存在
+config_dir = './config/config.ini'
+if not os.path.isfile('./config/config.ini'):
+ raise Exception(f"配置文件`{config_dir}`不存在,请参考`./config/config_backup.ini`进行配置")
# 配置日志
log_folder = './logs'
@@ -30,7 +28,7 @@ def get_log_filename(name):
get_log_filename('runing'),
when='midnight', # 每天轮转一次
interval=1, # 轮转周期为1天
- backupCount=int(get_cfg('param', 'backup_count')) # 保留最近?天的日志文件
+ backupCount=int(get_cfg('crawl', 'backup_count', 30)) # 保留最近?天的日志文件
)
log_handler.setLevel(logging.INFO)
log_handler.setFormatter(log_formatter)
@@ -41,7 +39,7 @@ def get_log_filename(name):
get_log_filename('ERROR'),
when='midnight', # 每天轮转一次
interval=1, # 轮转周期为1天
- backupCount=int(get_cfg('param', 'backup_count')) # 保留最近?天的日志文件
+ backupCount=int(get_cfg('crawl', 'backup_count', 30)) # 保留最近?天的日志文件
)
error_log_handler.setLevel(logging.ERROR) # 只记录 ERROR 级别及以上的日志
error_log_handler.setFormatter(log_formatter)
@@ -56,13 +54,13 @@ def get_log_filename(name):
# only_latest: true增量下载 false全量下载
-def download_comic(comic, db_path, only_latest):
+def download_comic(comic, db_path, only_latest, executor: ThreadPoolExecutor):
cid = comic["_id"]
title = comic["title"]
author = comic["author"]
categories = comic["categories"]
episodes = pica_server.episodes_all(cid, title)
- is_detail = os.environ.get("DETAIL", "False") == "True"
+ is_detail = get_cfg("crawl", "detail", "True") == "True"
num_pages = comic["pagesCount"] if "pagesCount" in comic else -1
# 增量更新
if only_latest:
@@ -81,17 +79,15 @@ def download_comic(comic, db_path, only_latest):
comic_path = os.path.join(".",
"comics",
f"{convert_file_name(author)}",
- (f"[{convert_file_name(title)}]"
- f"[{convert_file_name(author)}]"
- f"[{convert_file_name(categories)}]")
+ f"{convert_file_name(title)}"
)
comic_path = ensure_valid_path(comic_path)
+
for episode in episodes:
chapter_title = convert_file_name(episode["title"])
chapter_path = os.path.join(comic_path, chapter_title)
chapter_path = Path(chapter_path)
chapter_path.mkdir(parents=True, exist_ok=True)
-
image_urls = []
current_page = 1
while True:
@@ -101,7 +97,7 @@ def download_comic(comic, db_path, only_latest):
current_page += 1
if page_data:
image_urls.extend(list(map(
- lambda i: i['media']['fileServer'] + '/static/' + i['media']['path'],
+ lambda i: i['media']['fileServer'] + '/static/' + i['media']['path'],
page_data
)))
else:
@@ -110,40 +106,36 @@ def download_comic(comic, db_path, only_latest):
logging.error(f"No images found of chapter:{chapter_title} in comic:{title}")
continue
- concurrency = int(get_cfg('crawl', 'concurrency'))
- image_urls_parts = list_partition(image_urls, concurrency)
- downloaded_count = 0.
- for image_urls_part in image_urls_parts:
- with ThreadPoolExecutor(max_workers=concurrency) as executor:
- futures = {
- executor.submit(download,
- pica_server, chapter_path,
- image_urls.index(image_url), image_url
- ): image_url
- for image_url in image_urls_part
- }
- for future in as_completed(futures):
- image_url = futures[future]
- try:
- future.result()
- downloaded_count += 1
- except Exception as e:
- current_image = image_urls.index(image_url) + 1
- episode_title = episode["title"]
- logging.error(f"Error downloading the {current_image}-th image"
- f"in episode:{episode_title}"
- f"in comic:{title}"
- f"Exception:{e}")
- continue
- if is_detail:
+ downloaded_count = 0
+ futures = {
+ executor.submit(download,
+ pica_server, chapter_path,
+ image_urls.index(image_url), image_url
+ ): image_url
+ for image_url in image_urls
+ }
+ for future in as_completed(futures):
+ image_url = futures[future]
+ try:
+ future.result()
+ downloaded_count += 1
+ except Exception as e:
+ current_image = image_urls.index(image_url) + 1
episode_title = episode["title"]
- print(
- f"[episode:{episode_title:<10}] "
- f"downloaded:{downloaded_count:>6}, "
- f"total:{len(image_urls):>4}, "
- f"progress:{int(downloaded_count / len(image_urls) * 100):>3}%",
- flush=True
- )
+ logging.error(f"Error downloading the {current_image}-th image"
+ f"in episode:{episode_title}"
+ f"in comic:{title}"
+ f"Exception:{e}")
+ continue
+ if is_detail:
+ episode_title = episode["title"]
+ print(
+ f"[episode:{episode_title:<10}] "
+ f"downloaded:{downloaded_count:>6}, "
+ f"total:{len(image_urls):>4}, "
+ f"progress:{int(downloaded_count / len(image_urls) * 100):>3}%",
+ flush=True
+ )
if downloaded_count == len(image_urls):
update_downloaded_episodes(cid, episode["title"], db_path)
else:
@@ -154,10 +146,11 @@ def download_comic(comic, db_path, only_latest):
f"Currently, {downloaded_count} images(total_images:{len(image_urls)}) "
"from this episode have been downloaded"
)
-
+ # 下载完成后,根据配置对漫画章节进行合并
+ if get_cfg("param", "merge_episodes", "False") == "True":
+ merge_episodes(comic_path)
# 下载每本漫画的间隔时间
- if os.environ.get("INTERVAL_TIME"):
- time.sleep(int(os.environ.get("INTERVAL_TIME")))
+ time.sleep(int(get_cfg('crawl', "interval_time", 1)))
# 登录并打卡
@@ -174,7 +167,7 @@ def download_comic(comic, db_path, only_latest):
# 关键词订阅的漫画
searched_comics = []
-keywords = get_cfg('param', 'subscribe_keyword').split(',')
+keywords = get_cfg('filter', 'subscribe_keyword').split(',')
for keyword in keywords:
searched_comics_ = pica_server.search_all(keyword)
print('关键词%s: 检索到%d本漫画' % (keyword, len(searched_comics_)), flush=True)
@@ -184,28 +177,31 @@ def download_comic(comic, db_path, only_latest):
favourited_comics = pica_server.my_favourite_all()
print('已下载共计%d本漫画' % get_downloaded_comic_count(db_path), flush=True)
print('收藏夹共计%d本漫画' % (len(favourited_comics)), flush=True)
-isChangeFavo = os.environ.get("CHANGE_FAVOURITE", False) == "True"
-
-for comic in (ranked_comics + favourited_comics + searched_comics):
- try:
- # 收藏夹:全量下载 其余:增量下载
- download_comic(comic, db_path, comic not in favourited_comics)
- info = pica_server.comic_info(comic['_id'])
- # 收藏夹中的漫画被下载后,自动取消收藏,避免下次运行时重复下载
- if info["data"]['comic']['isFavourite'] and isChangeFavo:
- pica_server.favourite(comic["_id"])
- update_comic_data(comic, db_path)
- except Exception as e:
- logging.error(
- 'Download failed for {}, with Exception:{}'.format(comic["title"], e)
- )
- continue
+isChangeFavo = get_cfg("param", "change_favourite", "True") == "True"
+
+concurrency = int(get_cfg('crawl', 'concurrency', 5))
+# 创建线程池的代码不要放for循环里面
+with ThreadPoolExecutor(max_workers=concurrency) as executor:
+ for comic in (ranked_comics + favourited_comics + searched_comics):
+ try:
+ # 收藏夹:全量下载 其余:增量下载
+ download_comic(comic, db_path, comic not in favourited_comics, executor)
+ info = pica_server.comic_info(comic['_id'])
+ # 在收藏夹的漫画下载完成后,根据配置决定是否需要自动取消收藏,避免下次运行时重复下载
+ if info["data"]['comic']['isFavourite'] and isChangeFavo:
+ pica_server.favourite(comic["_id"])
+ update_comic_data(comic, db_path)
+ except Exception as e:
+ logging.error(
+ 'Download failed for {}, with Exception:{}'.format(comic["title"], e)
+ )
+ continue
# 打包成zip文件, 并删除旧数据 , 删除comics文件夹会导致docker挂载报错
if os.environ.get("PACKAGE_TYPE", "False") == "True":
- print("The comic is being packaged")
for folderName in os.listdir('./comics'):
+ print(f"The comic [{folderName}] is being packaged")
folder_path = os.path.join('./comics', folderName)
if os.path.isdir(folder_path):
for chapter_folder in os.listdir(folder_path):
@@ -217,8 +213,8 @@ def download_comic(comic, db_path, only_latest):
# delete folders in comics
if os.environ.get("DELETE_COMIC", "True") == "True":
- print("The comic is being deleted")
for fileName in os.listdir('./comics'):
+ print(f"The comic [{fileName}] is being deleted")
file_path = os.path.join('./comics', fileName)
if os.path.isfile(file_path) or os.path.islink(file_path):
os.unlink(file_path)
@@ -227,9 +223,10 @@ def download_comic(comic, db_path, only_latest):
# 发送消息通知
-if os.environ.get("BARK_URL"):
+bark_url = get_cfg("param", "bark_url")
+if bark_url:
requests.get(
- os.environ.get("BARK_URL") + " " +
+ bark_url + " " +
f"排行榜漫画共计{len(ranked_comics)}" +
f"关键词漫画共计{len(searched_comics)}" +
f"收藏夹漫画共计{len(favourited_comics)}"
diff --git a/src/mergeComic.py b/src/mergeComic.py
deleted file mode 100644
index 68e9238e..00000000
--- a/src/mergeComic.py
+++ /dev/null
@@ -1,32 +0,0 @@
-# 合并多个本子,将同一本放入相同文件夹,按章节顺序升序命名文件夹
-
-import os
-import shutil
-
-from pip._vendor.distlib.compat import raw_input
-
-path = './zips/'
-if not os.path.exists(path):
- os.makedirs(path)
-
-target = raw_input("目标目录:")
-if not os.path.exists(path + target):
- os.makedirs(path + target)
-
-target_files = os.listdir(path + target)
-target_files.sort(key=lambda x: str(x.split('.')[0]))
-index = 1 if not target_files else int(target_files[-1].split('.')[0]) + 1
-
-dirs = os.listdir(path)
-dirs.remove(target)
-for i in range(len(dirs)):
- d = dirs[i]
- pics = os.listdir(path + d)
- pics.sort(key=lambda x: str(x.split('.')[0]))
-
- source = path + d + '/'
- for p in pics:
- os.rename(source + p, path + target + '/' + str(index).zfill(4) + '.jpg')
- index += 1
- shutil.rmtree(source)
- print('merge finished,' + d + ' removed------------------------------------', flush=True)
diff --git a/src/util.py b/src/util.py
index 910193f8..271bf9f1 100644
--- a/src/util.py
+++ b/src/util.py
@@ -1,6 +1,7 @@
import operator
import os
import random
+import shutil
import zipfile
from configparser import ConfigParser
from datetime import datetime
@@ -13,22 +14,33 @@
def convert_file_name(name: str) -> str:
if isinstance(name, list):
name = "&".join(map(str, name))
- # windows的文件夹不能带特殊字符,需要处理下文件夹名
+ # 处理文件夹名中的特殊字符
for i, j in ("//", "\\\", "??", "|︱", "\""", "**", "<<", ">>", ":-"):
name = name.replace(i, j)
name = name.replace(" ", "")
+ # 操作系统对文件夹名最大长度有限制,这里对超长部分进行截断,避免file name too long报错
+ # linux是255字节,windows更大一些
+ name = truncate_string_by_bytes(name, 255)
return name
+# 该方法的配置读取优先级为 环境变量 > config.ini > default_value默认值
+# docker方式部署时, 只需配置环境变量, 无需重新构建镜像
+# GitHub Actions方式部署时, 部分敏感信息不适合填进config.ini文件并上传至代码仓库, 也请配置进环境变量中
+def get_cfg(section: str, key: str, default_value = ''):
+ # 项目中用到的环境变量名统一是大写的, 这里对入参key做了大写转换
+ config_value = os.environ.get(key.upper())
+ if config_value:
+ return config_value
-def get_cfg(section: str, key: str):
+ # 因为ConfigParser限制变量名是小写的, 在读取config.ini的配置,对入参key做了小写转换
parser = ConfigParser()
parser.read('./config/config.ini', encoding='utf-8')
- config_value = dict(parser.items(section))[key]
+ config_value = dict(parser.items(section))[key.lower()]
if config_value:
return config_value
- #如果是用git actions方式部署,部分敏感信息不适合填进config.ini文件并上传至代码仓库,此时可以从从环境变量取值作为兜底
- #ConfigParser读写配置项是按小写来的,但linux环境变量又是大小写敏感的.这里把入参key做了大写转换
- return os.environ[key.upper()]
+
+ # 最后取默认值作为兜底
+ return default_value
def get_latest_run_time():
@@ -44,11 +56,11 @@ def get_latest_run_time():
def filter_comics(comic, episodes, db_path) -> list:
# 已下载过的漫画,执行增量更新
if is_comic_downloaded(comic["_id"], db_path):
- episodes = [episode for episode in episodes
+ episodes = [episode for episode in episodes
if not is_episode_downloaded(comic["_id"], episode["title"], db_path)]
# 过滤掉指定分区的本子
- categories_rule = get_cfg('param', 'categories_rule')
- categories = get_cfg('param', 'categories').split(',')
+ categories_rule = get_cfg('filter', 'categories_rule')
+ categories = get_cfg('filter', 'categories').split(',')
# 漫画的分区和用户自定义分区的交集
intersection = set(comic['categories']).intersection(set(categories))
if categories:
@@ -345,3 +357,87 @@ def ensure_valid_path(path):
print(f"Path too long, truncating: {path}")
path = path[:(max_path_length)] # 截断路径
return path
+
+def truncate_string_by_bytes(s, max_bytes):
+ """
+ 截断字符串,使其字节长度不超过max_bytes。
+
+ 参数:
+ s (str): 要截断的字符串。
+ max_bytes (int): 字符串的最大字节长度。
+
+ 返回:
+ str: 截断后的字符串。
+ """
+ # 将字符串编码为字节串(默认使用utf-8编码)
+ encoded_str = s.encode('utf-8')
+
+ # 检查字节串的长度
+ if len(encoded_str) > max_bytes:
+ # 截断字节串
+ truncated_bytes = encoded_str[:max_bytes]
+
+ # 确保截断后的字节串是一个有效的UTF-8编码(可能需要移除最后一个字节以形成完整的字符)
+ # 这通过解码然后重新编码来实现,可能会丢失最后一个字符的一部分
+ truncated_str = truncated_bytes.decode('utf-8', 'ignore').encode('utf-8')
+
+ # 返回截断后的字符串(以字节形式编码然后解码回字符串)
+ return truncated_str.decode('utf-8')
+ else:
+ # 如果不需要截断,则返回原始字符串
+ return s
+
+def merge_episodes(dir):
+ """
+ 将漫画从各个章节子文件夹中提取出来, 合并到同一目录, 方便连续阅读
+ 合并前的目录结构: ./comics/漫画标题/章节名/图片
+ 合并后的目录结构: ./comics/漫画标题/图片
+
+ 参数:
+ dir (str): 漫画所在文件夹
+ """
+
+ # 获取目标目录下的所有子文件夹(章节信息),按章节名排序
+ subdirs = sorted([d for d in os.listdir(dir) if os.path.isdir(os.path.join(dir, d))])
+
+ # 存储每个子文件夹中的文件数量
+ counts = []
+
+ # 存储所有文件的完整路径,以便后续处理
+ all_files = []
+
+ # 遍历子文件夹,计算文件数量并收集文件路径
+ for subdir in subdirs:
+ subdir_path = os.path.join(dir, subdir)
+ count = len([f for f in os.listdir(subdir_path) if os.path.isfile(os.path.join(subdir_path, f))])
+ counts.append(count)
+
+ # 获取章节下的所有图片,按图片名排序
+ pics = os.listdir(subdir_path)
+ pics.sort(key=lambda x: str(x.split('.')[0]))
+ for filename in pics:
+ if os.path.isfile(os.path.join(subdir_path, filename)):
+ all_files.append((os.path.join(subdir_path, filename), subdir, count))
+
+ # 确定最大文件数量,用于确定文件名填充宽度
+ max_count = sum(counts) if counts else 0
+ width = len(str(max_count))
+ # 初始化全局文件计数器
+ global_counter = 1
+
+ # 遍历所有文件,复制并重命名
+ for src_file, subdir, count in all_files:
+ # 生成新的文件名,使用宽度进行零填充
+ new_filename = f"{global_counter:0{width}d}{os.path.splitext(src_file)[1]}"
+
+ # 复制文件到目标目录(这里直接复制到dir)
+ shutil.copy2(src_file, os.path.join(dir, new_filename))
+
+ # 更新全局计数器
+ global_counter += 1
+
+ # 删除各个章节的文件夹
+ for subdir in subdirs:
+ shutil.rmtree(os.path.join(dir,subdir))
+
+ print(f"{dir}合并章节完成,共处理了 {global_counter - 1} 个文件")
\ No newline at end of file