English | 中文
VisionLAN: From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network
视觉语言建模网络(VisionLAN)[1]是一种文本识别模型,它通过在训练阶段使用逐字符遮挡的特征图来同时学习视觉和语言信息。这种模型不需要额外的语言模型来提取语言信息,因为视觉和语言信息可以作为一个整体来学习。
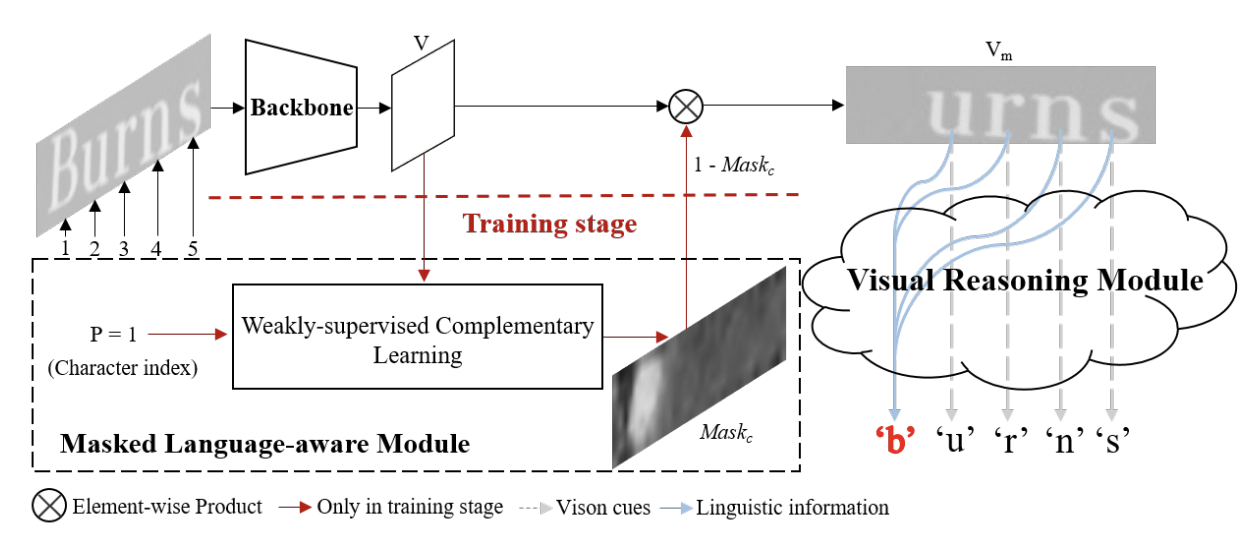
图 1. Visionlan 的模型结构 [1]
如上图所示,VisionLAN的训练流程由三个模块组成:
- 骨干网络从输入图像中提取视觉特征图;
- 掩码语言感知模块(MLM)以视觉特征图和一个随机选择的字符索引作为输入,并生成位置感知的字符掩码图,以创建逐字符遮挡的特征图;
- 最后,视觉推理模块(VRM)以遮挡的特征图作为输入,并在完整的单词级别的监督下进行预测。
但在测试阶段,MLM不被使用。只有骨干网络和VRM被用于预测。
| mindspore | ascend driver | firmware | cann toolkit/kernel |
|---|---|---|---|
| 2.3.1 | 24.1.RC2 | 7.3.0.1.231 | 8.0.RC2.beta1 |
请参考MindOCR中的安装说明。
训练集
VisionLAN的作者使用了两个合成文本数据集进行训练:SynthText(800k)和MJSynth。请按照原始VisionLAN repository的说明进行操作,下载这两个LMDB数据集。
下载SynthText.zip和MJSynth.zip后,请解压缩并将它们放置在./datasets/train目录下。训练集数据总共包括 14,200,701 个样本。更多关于训练集的信息如下:
验证集
VisionLAN的作者使用了六个真实文本数据集进行评估:IIIT5K Words(IIIT5K_3000)、ICDAR 2013(IC13_857)、Street View Text(SVT)、ICDAR 2015(IC15_1811)、Street View Text-Perspective(SVTP)、CUTE80(CUTE)。
请按照原始VisionLAN repository的说明进行操作,下载验证数据集。
下载evaluation.zip后,请解压缩并将其放置在./datasets目录下。在 ./datasets/evaluation路径下,一共有7个文件夹:
- IIIT5K: 50M, 3000 samples
- IC13: 72M, 857 samples
- SVT: 2.4M, 647 samples
- IC15: 21M, 1811 samples
- SVTP: 1.8M, 645 samples
- CUTE: 8.8M, 288 samples
- Sumof6benchmarks: 155M, 7248 samples
训练中,我们只用到了 ./datasets/evaluation/Sumof6benchmarks 作为验证集。 用户可以选择将 ./datasets/evaluation 下其他无关的文件夹删除。
测试集
我们选择用10个公开数据集来测试模型精度。用户可以从这里 (ref: deep-text-recognition-benchmark)下载测试集。测试中我们只需要用到 evaluation.zip。
在下载 evaluation.zip完成后, 请解压缩, 并把文件夹名称从 evaluation 改为 test。请把这个test文件夹放在 ./datasets/路径下
测试集总共包含 12,067 个样本。详细信息如下:
- CUTE80: 8.8 MB, 288 samples
- IC03_867: 4.9 MB, 867 samples
- IC13_857: 72 MB, 857 samples
- IC13_1015: 77 MB, 1015 samples
- IC15_1811: 21 MB, 1811 samples
- IC15_2077: 25 MB, 2077 samples
- IIIT5k_3000: 50 MB, 3000 samples
- SVT: 2.4 MB, 647 samples
- SVTP: 1.8 MB, 645 samples
准备好的数据集文件结构应如下所示:
datasets
├── test
│ ├── CUTE80
│ ├── IC03_860
│ ├── IC03_867
│ ├── IC13_857
│ ├── IC13_1015
│ ├── IC15_1811
│ ├── IC15_2077
│ ├── IIIT5k_3000
│ ├── SVT
│ ├── SVTP
├── evaluation
│ ├── Sumof6benchmarks
│ ├── ...
└── train
├── MJSynth
└── SynText
如果数据集放置在./datasets目录下,则无需更改yaml配置文件configs/rec/visionlan/visionlan_L*.yaml中的train.dataset.dataset_root。
否则,请相应地更改以下字段:
...
train:
dataset_sink_mode: False
dataset:
type: LMDBDataset
dataset_root: dir/to/dataset <--- 更新
data_dir: train <--- 更新
...
eval:
dataset_sink_mode: False
dataset:
type: LMDBDataset
dataset_root: dir/to/dataset <--- 更新
data_dir: evaluation/Sumof6benchmarks <--- 更新
...您也可以选择根据CPU的线程数量来修改
train.loader.num_workers.
除了数据集设定以外, 请检查下列的重要参数: system.distribute, system.val_while_train, common.batch_size。这些参数的含义解释如下:
system:
distribute: True # 分布式训练选择`True`, 单卡训练选择 `False`
amp_level: 'O0'
seed: 42
val_while_train: True # 训练途中进行验证
common:
...
batch_size: &batch_size 192 # 训练batch size
...
loader:
shuffle: False
batch_size: 64 # 验证/测试 batch size
...注意:
- 由于全局批大小 (batch_size x num_devices) 是对结果复现很重要,因此当NPU卡数发生变化时,调整batch_size以保持全局批大小不变,或将学习率线性调整为新的全局批大小。
训练阶段包括无语言(LF)和有语言(LA)过程,总共有三个训练步骤:
LF_1:训练骨干网络和VRM,不训练MLM
LF_2:训练MLM并微调骨干网络和VRM
LA:使用MLM生成的掩码遮挡特征图,训练骨干网络、MLM和VRM
我们接下来使用分布式训练进行这三个步骤。对于单卡训练,请参考识别教程。
mpirun --allow-run-as-root -n 4 python tools/train.py --config configs/rec/visionlan/visionlan_resnet45_LF_1.yaml
mpirun --allow-run-as-root -n 4 python tools/train.py --config configs/rec/visionlan/visionlan_resnet45_LF_2.yaml
mpirun --allow-run-as-root -n 4 python tools/train.py --config configs/rec/visionlan/visionlan_resnet45_LA.yaml训练结果(包括checkpoints、每个阶段的性能和loss曲线)将保存在yaml配置文件中由参数ckpt_save_dir解析的目录中。默认目录为./tmp_visionlan。
在完成上述三个训练步骤以后, 用户需要在测试前,将 configs/rec/visionlan/visionlan_resnet45_LA.yaml 文件中的system.distribute改为 False。
若要评估已训练模型的准确性, 有以下两个方法可供选择:
- 方法一: 先对每一个数据集进行评估: CUTE80, IC03_860, IC03_867, IC13_857, IC131015, IC15_1811, IC15_2077, IIIT5k_3000, SVT, SVTP。 然后再计算平均精度。
CUTE80 数据集的评估脚本如下:
model_name="e8"
yaml_file="configs/rec/visionlan/visionlan_resnet45_LA.yaml"
training_step="LA"
python tools/eval.py --config $yaml_file --opt eval.dataset.data_dir=test/CUTE80 eval.ckpt_load_path="./tmp_visionlan/${training_step}/${model_name}.ckpt"
- 方法二: 先将全部的测试集放在同一个文件夹下,例如
datasets/test/, 然后用tools/benchmarking/multi_dataset_eval.py进行多数据集评估。示例脚本如下:
model_name="e8"
yaml_file="configs/rec/visionlan/visionlan_resnet45_LA.yaml"
training_step="LA"
python tools/benchmarking/multi_dataset_eval.py --config $yaml_file --opt eval.dataset.data_dir="test" eval.ckpt_load_path="./tmp_visionlan/${training_step}/${model_name}.ckpt"根据我们实验结果,在10个公开数据集上的评估结果如下:
| model name | backbone | train dataset | params(M) | cards | batch size | jit level | graph compile | ms/step | img/s | accuracy | recipe | weight |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| visionlan | Resnet45 | MJ+ST | 42.22 | 4 | 128 | O2 | 191.52 s | 280.29 | 1826.63 | 90.62% | yaml(LF_1) yaml(LF_2) yaml(LA) | ckpt files | mindir(LA) |
Detailed accuracy results for ten benchmark datasets
| model name | backbone | cards | IC03_860 | IC03_867 | IC13_857 | IC13_1015 | IC15_1811 | IC15_2077 | IIIT5k_3000 | SVT | SVTP | CUTE80 | average |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| visionlan | Resnet45 | 1 | 96.16% | 95.16% | 95.92% | 94.19% | 84.04% | 77.47% | 95.53% | 92.27% | 85.89% | 89.58% | 90.62% |
注
- 训练数据集:
MJ+ST代表两个合成数据集SynthText(800k)和MJSynth的组合。 - 要在其他训练环境中重现结果,请确保全局批量大小相同。
- 这些模型是从头开始训练的,没有任何预训练。有关训练和评估的更多数据集详细信息,请参阅数据集准备部分。
- VisionLAN的MindIR导出时的输入Shape均为(1, 3, 64, 256)。
请参考MindOCR 推理教程,基于MindSpore Lite在Ascend 310上进行模型的推理,包括以下步骤:
模型导出
请先下载已导出的MindIR文件,或者参考模型导出教程,使用以下命令将训练完成的ckpt导出为MindIR文件:
# 有关更多参数使用详细信息,请执行 `python tools/export.py -h`
python tools/export.py --model_name_or_config visionlan_resnet45 --data_shape 64 256 --local_ckpt_path /path/to/visionlan-ckpt其中,data_shape是导出MindIR时的模型输入Shape的height和width,下载链接中MindIR对应的shape值见注释。
环境搭建
请参考环境安装教程,配置MindSpore Lite推理运行环境。
模型转换
请参考模型转换教程,使用converter_lite工具对MindIR模型进行离线转换。
执行推理
假设在模型转换后得到output.mindir文件,在deploy/py_infer目录下使用以下命令进行推理:
python infer.py \
--input_images_dir=/your_path_to/test_images \
--rec_model_path=your_path_to/output.mindir \
--rec_model_name_or_config=../../configs/rec/visionlan/visionlan_resnet45_LA.yaml \
--res_save_dir=results_dir[1] Yuxin Wang, Hongtao Xie, Shancheng Fang, Jing Wang, Shenggao Zhu, Yongdong Zhang: From Two to One: A New Scene Text Recognizer with Visual Language Modeling Network. ICCV 2021: 14174-14183