diff --git a/docs/en-US/handbook/action-template-print/index.md b/docs/en-US/handbook/action-template-print/index.md
new file mode 100644
index 000000000..aa3eacd09
--- /dev/null
+++ b/docs/en-US/handbook/action-template-print/index.md
@@ -0,0 +1,2546 @@
+# Template Printing
+
+
+
+## Introduction
+
+The Template Printing plugin is a powerful tool that allows you to edit template files in Word, Excel, and PowerPoint (supporting `.docx`, `.xlsx`, `.pptx` formats), set placeholders and logical structures within the templates, and dynamically generate pre-formatted files such as `.docx`, `.xlsx`, `.pptx`, and PDF files. This plugin is widely used for generating various business documents, such as quotations, invoices, contracts, etc., significantly improving the efficiency and accuracy of document generation.
+
+### Key Features
+
+- **Multi-format Support**: Compatible with Word, Excel, and PowerPoint templates to meet different document generation needs.
+- **Dynamic Data Filling**: Automatically fills and generates document content through placeholders and logical structures.
+- **Flexible Template Management**: Supports adding, editing, deleting, and categorizing templates for easy maintenance and use.
+- **Rich Template Syntax**: Supports basic replacement, array access, loops, conditional output, and other template syntax to meet complex document generation needs.
+- **Formatter Support**: Provides conditional output, date formatting, number formatting, and other functions to enhance the readability and professionalism of documents.
+- **Efficient Output Formats**: Supports direct generation of PDF files for easy sharing and printing.
+
+## Configuration Instructions
+
+### Activating Template Printing
+
+1. **Open the Detail Block**:
+ - Navigate to the detail block in the application where you need to use the template printing feature.
+
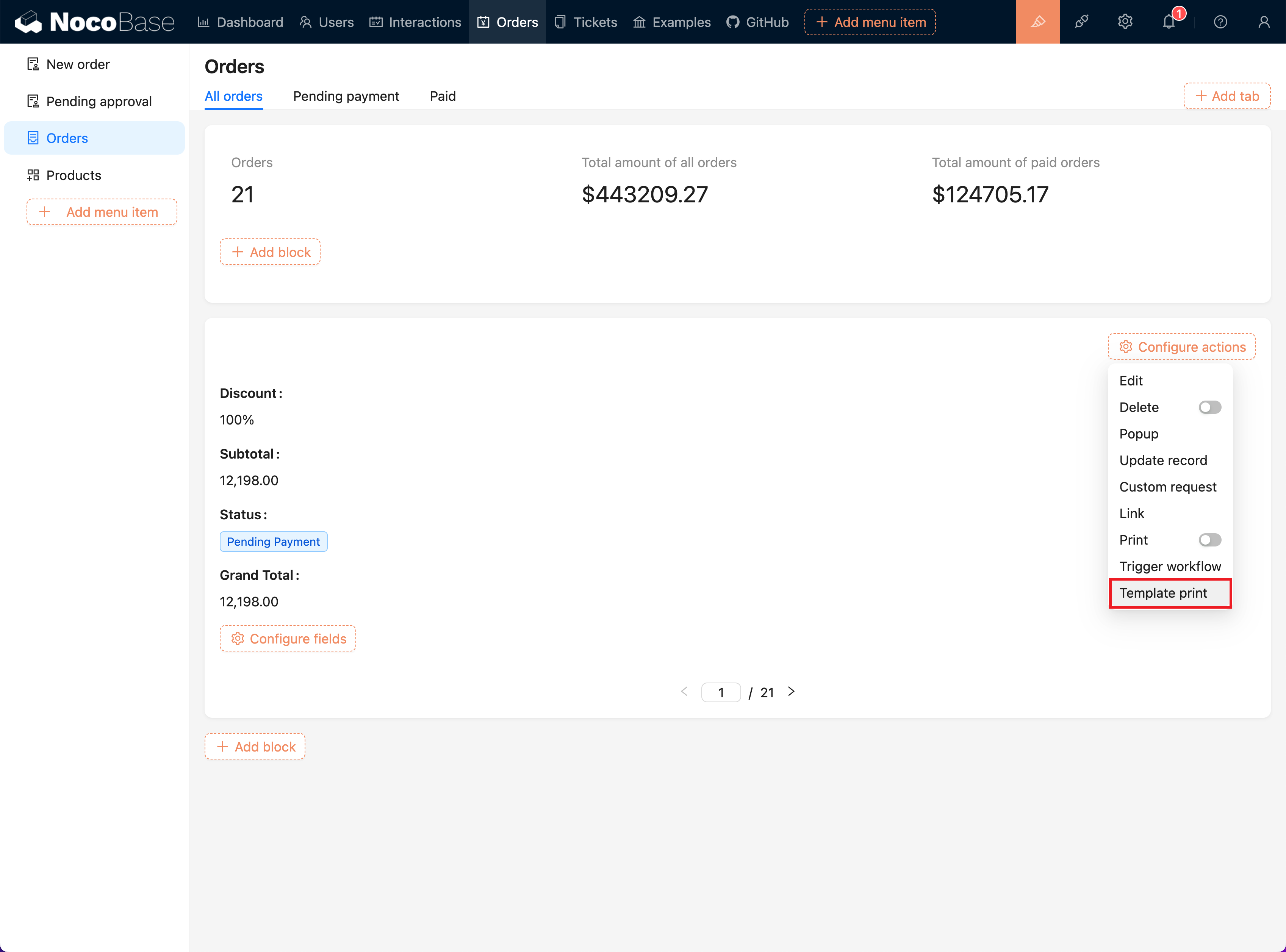
+2. **Access the Configuration Operation Menu**:
+ - Click the "Configuration Operation" menu at the top of the interface.
+
+3. **Select "Template Printing"**:
+ - Click the "Template Printing" option in the dropdown menu to activate the plugin.
+
+ 
+
+### Configuring Templates
+
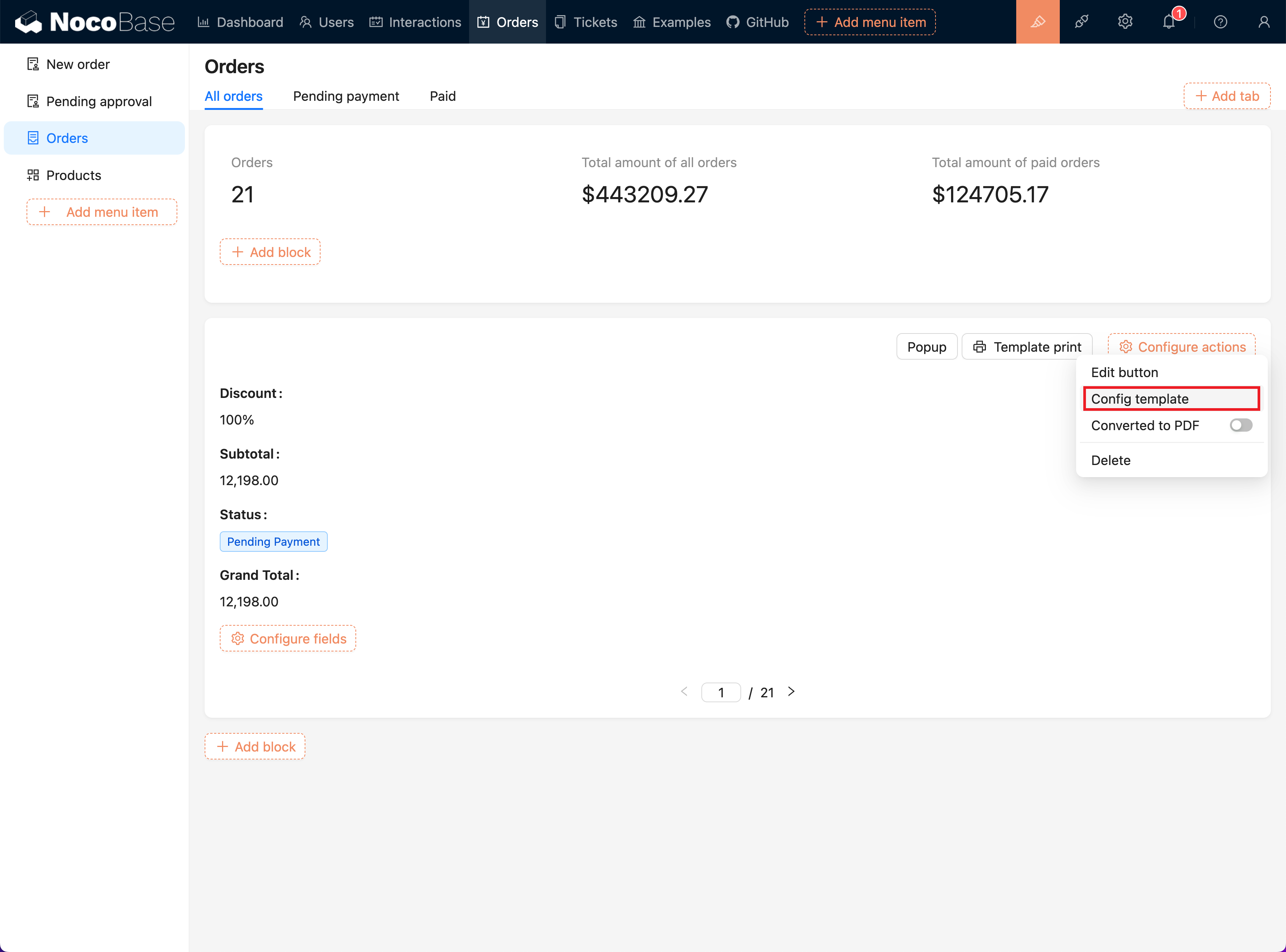
+1. **Access the Template Configuration Page**:
+ - In the configuration menu of the "Template Printing" button, select the "Template Configuration" option.
+
+ 
+
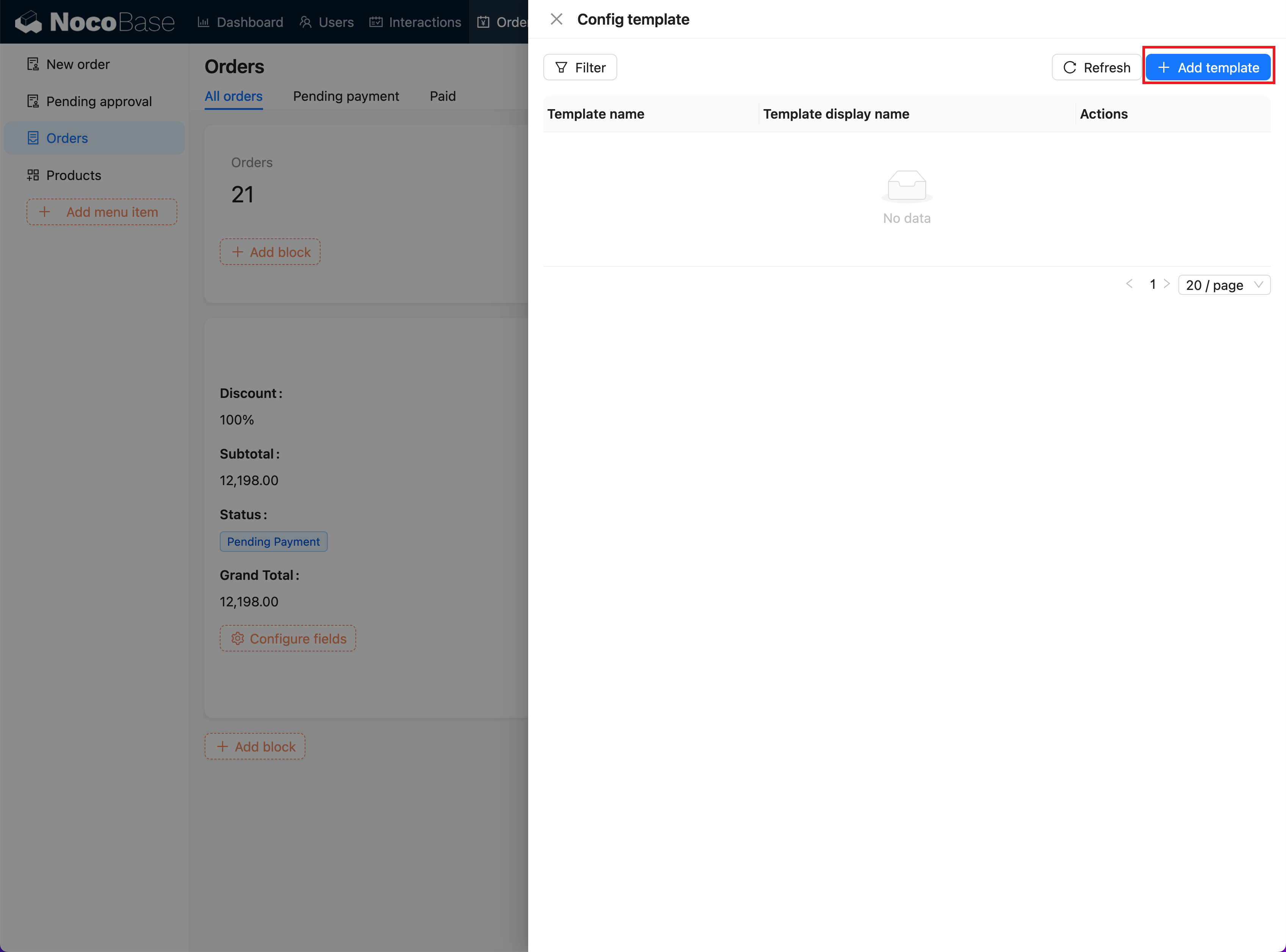
+2. **Add a New Template**:
+ - Click the "Add Template" button to enter the template addition page.
+
+ 
+
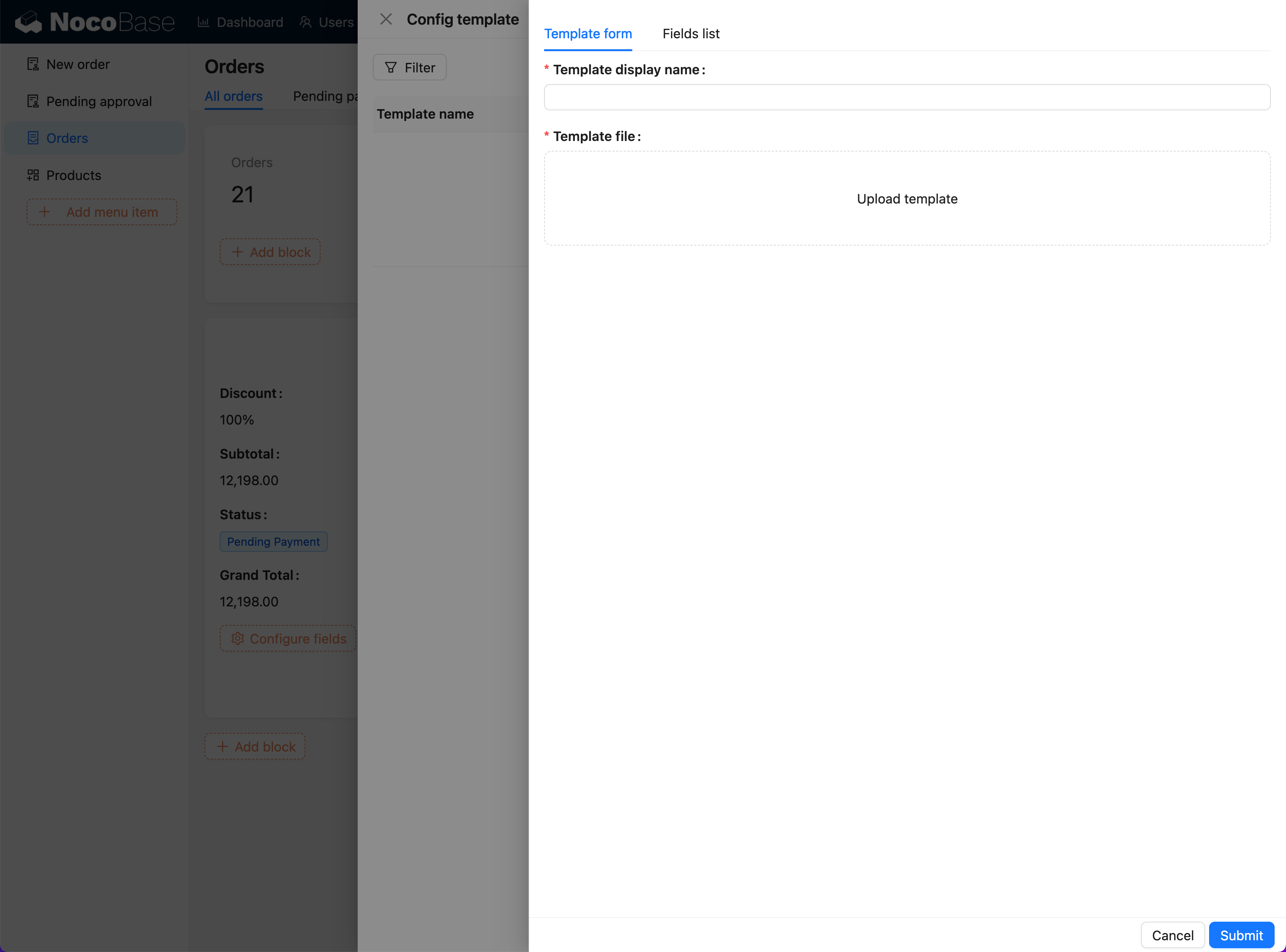
+3. **Fill in Template Information**:
+ - In the template form, fill in the template name and select the template type (Word, Excel, PowerPoint).
+ - Upload the corresponding template file (supports `.docx`, `.xlsx`, `.pptx` formats).
+
+ 
+
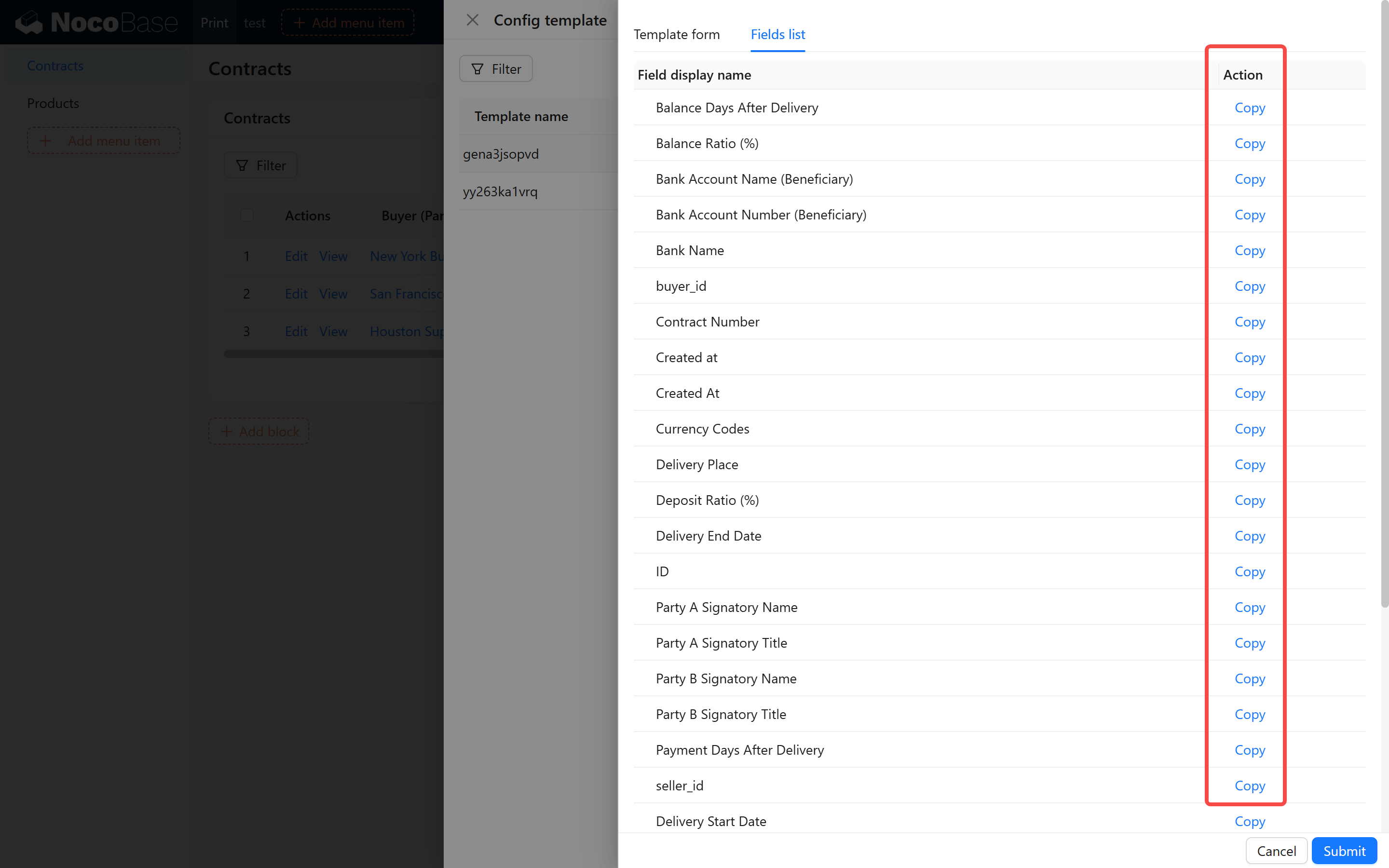
+4. **Edit and Save the Template**:
+ - Go to the "Field List" page, copy fields, and fill them into the template.
+ 
+ 
+ - After filling in the details, click the "Save" button to complete the template addition.
+
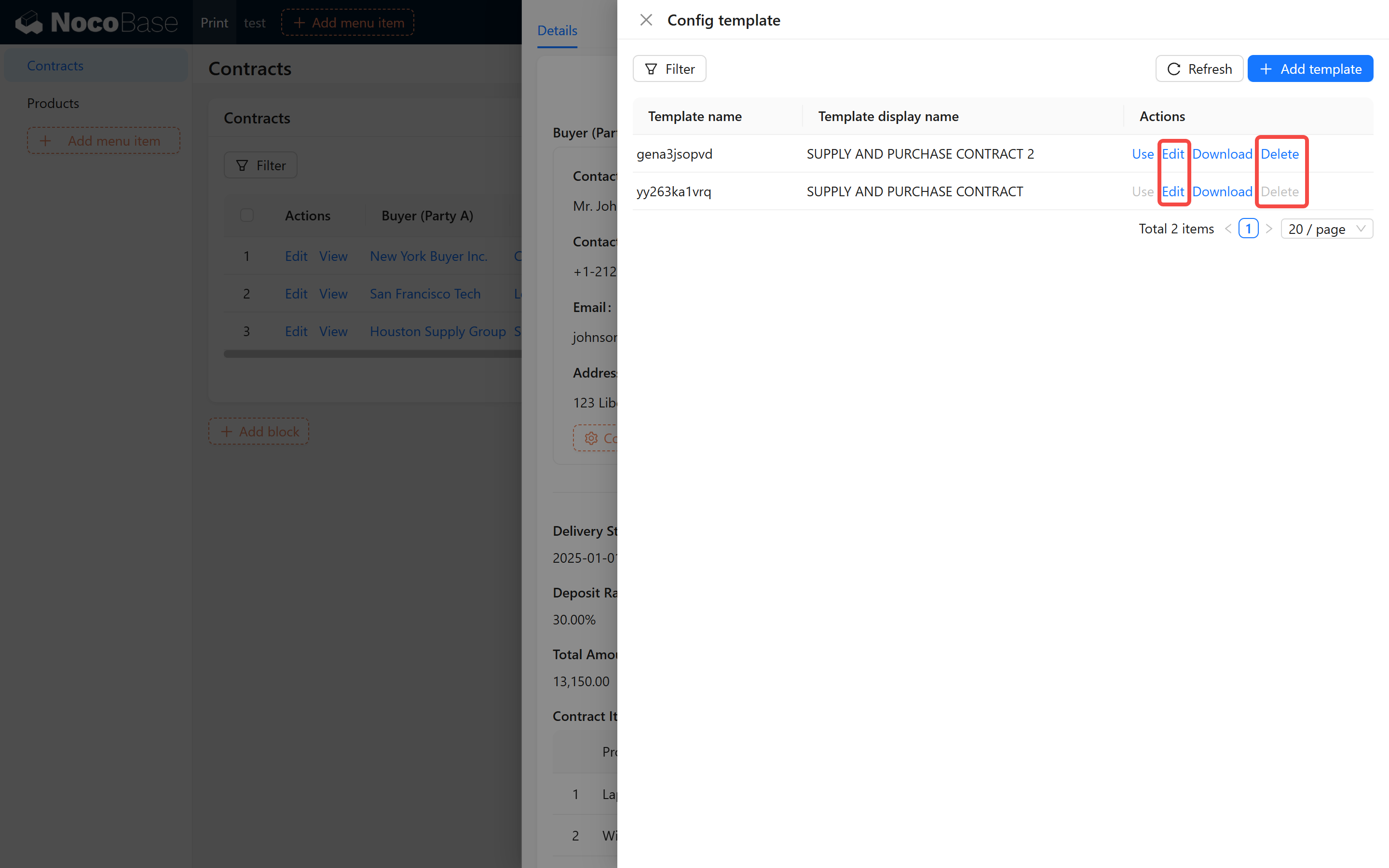
+5. **Template Management**:
+ - Click the "Use" button on the right side of the template list to activate the template.
+ - Click the "Edit" button to modify the template name or replace the template file.
+ - Click the "Download" button to download the configured template file.
+ - Click the "Delete" button to remove unnecessary templates. The system will prompt for confirmation to avoid accidental deletion.
+ 
+
+## Template Syntax
+
+The Template Printing plugin provides various syntaxes to flexibly insert dynamic data and logical structures into templates. Below are detailed syntax explanations and usage examples.
+
+### Basic Replacement
+
+Use placeholders in the format `{d.xxx}` for data replacement. For example:
+
+- `{d.title}`: Reads the `title` field from the dataset.
+- `{d.date}`: Reads the `date` field from the dataset.
+
+**Example**:
+
+Template Content:
+```
+Dear Customer,
+
+Thank you for purchasing our product: {d.productName}.
+Order ID: {d.orderId}
+Order Date: {d.orderDate}
+
+Wish you a pleasant experience!
+```
+
+Dataset:
+```json
+{
+ "productName": "Smart Watch",
+ "orderId": "A123456789",
+ "orderDate": "2025-01-01"
+}
+```
+
+Rendered Result:
+```
+Dear Customer,
+
+Thank you for purchasing our product: Smart Watch.
+Order ID: A123456789
+Order Date: 2025-01-01
+
+Wish you a pleasant experience!
+```
+
+### Accessing Sub-objects
+
+If the dataset contains sub-objects, you can access the properties of the sub-objects using dot notation.
+
+**Syntax**: `{d.parent.child}`
+
+**Example**:
+
+Dataset:
+```json
+{
+ "customer": {
+ "name": "Li Lei",
+ "contact": {
+ "email": "lilei@example.com",
+ "phone": "13800138000"
+ }
+ }
+}
+```
+
+Template Content:
+```
+Customer Name: {d.customer.name}
+Email Address: {d.customer.contact.email}
+Phone Number: {d.customer.contact.phone}
+```
+
+Rendered Result:
+```
+Customer Name: Li Lei
+Email Address: lilei@example.com
+Phone Number: 13800138000
+```
+
+### Accessing Arrays
+
+If the dataset contains arrays, you can use the reserved keyword `i` to access elements in the array.
+
+**Syntax**: `{d.arrayName[i].field}`
+
+**Example**:
+
+Dataset:
+```json
+{
+ "staffs": [
+ { "firstname": "James", "lastname": "Anderson" },
+ { "firstname": "Emily", "lastname": "Roberts" },
+ { "firstname": "Michael", "lastname": "Johnson" }
+ ]
+}
+```
+
+Template Content:
+```
+The first employee's last name is {d.staffs[i=0].lastname}, and the first name is {d.staffs[i=0].firstname}
+```
+
+Rendered Result:
+```
+The first employee's last name is Anderson, and the first name is James
+```
+
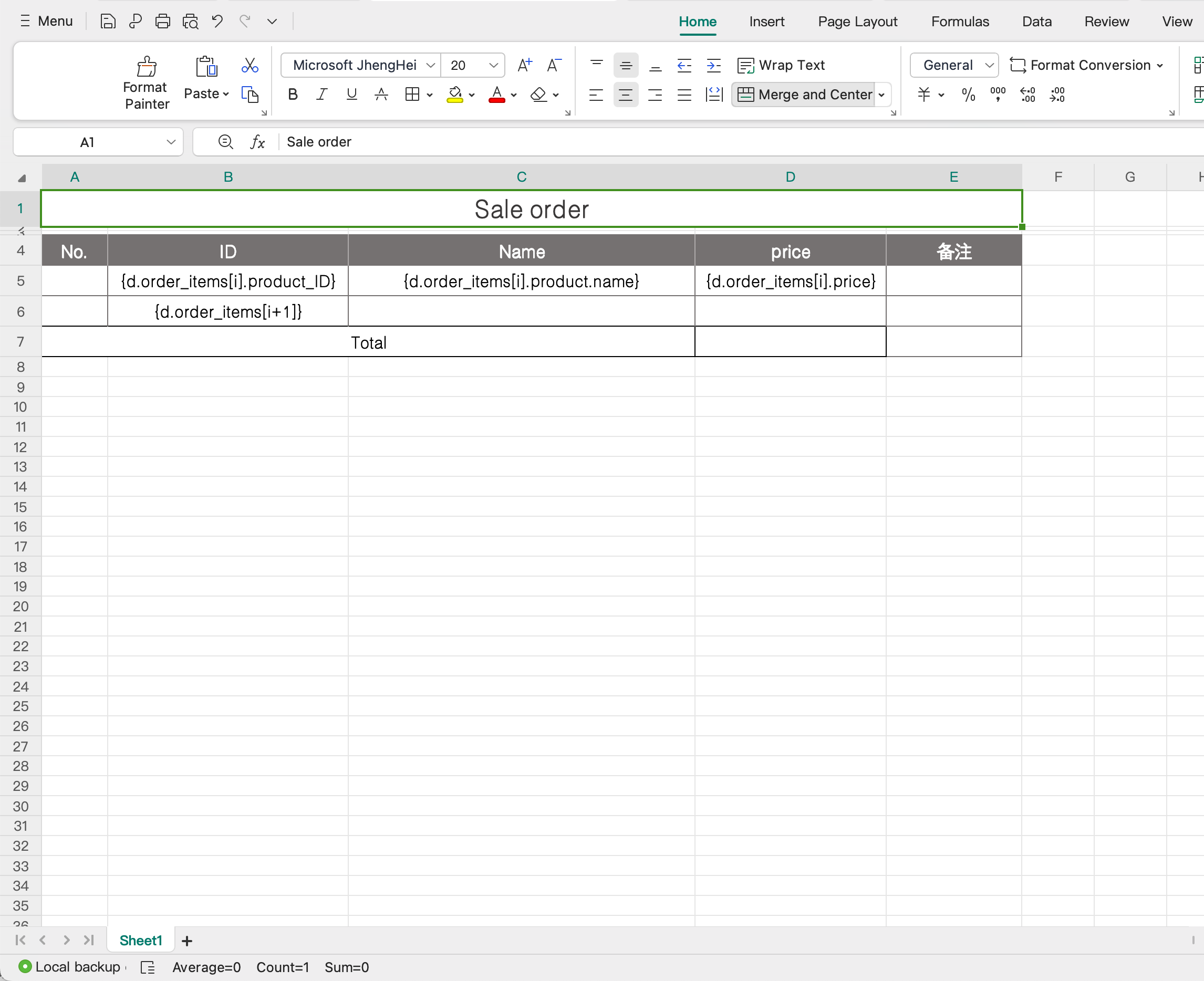
+### Loop Output
+
+The Template Printing plugin supports looping through arrays to output data. There is no need to explicitly mark the start and end of the loop; simply use the reserved keywords `i` and `i+1` in the template. The plugin will automatically recognize and process the loop section.
+
+#### Simple Array Loop
+
+**Example**: Generating a table of company employee data
+
+**Dataset**:
+```json
+{
+ "staffs": [
+ { "firstname": "James", "lastname": "Anderson" },
+ { "firstname": "Emily", "lastname": "Roberts" },
+ { "firstname": "Michael", "lastname": "Johnson" }
+ ]
+}
+```
+
+**Template**:
+
+| First Name | Last Name |
+|---|---|
+| {d.staffs[i].firstname} | {d.staffs[i].lastname} |
+| {d.staffs[i+1]} | |
+
+**Rendered Result**:
+
+| First Name | Last Name |
+|---|---|
+| James | Anderson |
+| Emily | Roberts |
+| Michael | Johnson |
+
+**Explanation**: The template uses `{d.staffs[i].firstname}` and `{d.staffs[i].lastname}` to loop through and fill in the first and last names of each employee. `{d.staffs[i+1]}` marks the start of the next row in the loop.
+
+#### Nested Array Loop
+
+The Template Printing plugin supports processing nested arrays, allowing for infinite levels of nested loops, suitable for displaying complex data structures.
+
+**Example**: Displaying car brands and their models
+
+**Dataset**:
+```json
+{
+ "cars": [
+ {
+ "brand": "Toyota",
+ "models": [{ "size": "Prius 2" }, { "size": "Prius 3" }]
+ },
+ {
+ "brand": "Tesla",
+ "models": [{ "size": "S" }, { "size": "X" }]
+ }
+ ]
+}
+```
+
+**Template**:
+
+```
+Brand: {d.cars[i].brand}
+Models:
+{d.cars[i].models[j].size}
+{d.cars[i].models[j+1].size}
+
+---
+```
+
+
+**Rendered Result**:
+```
+Brand: Toyota
+Models:
+Prius 2
+Prius 3
+
+---
+Brand: Tesla
+Models:
+S
+X
+
+---
+```
+
+**Explanation**: The outer loop uses `i` to iterate through each brand, while the inner loop uses `j` to iterate through each model under the brand. `{d.cars[i].models[j].size}` and `{d.cars[i].models[j+1].size}` are used to fill in the current and next models, respectively. This allows for infinite levels of nested loops to accommodate complex data structures.
+
+### Sorting Function
+
+The Template Printing plugin allows sorting arrays based on object properties, not limited to using the iterator `i`. Currently, it supports ascending order by a specified property but does not support descending order.
+
+**Example**: Sorting cars by "power" in ascending order
+
+**Dataset**:
+```json
+{
+ "cars" : [
+ { "brand" : "Lumeneo" , "power" : 3 },
+ { "brand" : "Tesla" , "power" : 1 },
+ { "brand" : "Toyota" , "power" : 2 }
+ ]
+}
+```
+
+**Template**:
+```
+{d.cars:sort(power)}
+Brand: {d.cars[i].brand}
+Power: {d.cars[i].power} kW
+
+---
+```
+
+**Rendered Result**:
+```
+Brand: Tesla
+Power: 1 kW
+
+---
+Brand: Toyota
+Power: 2 kW
+
+---
+Brand: Lumeneo
+Power: 3 kW
+
+---
+```
+
+**Explanation**: The `:sort(power)` function sorts the `cars` array by the `power` property in ascending order, and then renders each car's brand and power.
+
+## Formatters
+
+Formatters are used to convert data into specific formats or perform conditional checks, enhancing the flexibility and expressiveness of templates.
+
+### Conditional Output
+
+Control the display and hiding of specific content using `showBegin` and `showEnd`.
+
+**Syntax**:
+```
+{d.field:condition:showBegin}
+Content
+{d.field:showEnd}
+```
+
+**Example**: Displaying special terms in a contract template based on customer type
+
+**Dataset**:
+```json
+{
+ "customerType": "VIP"
+}
+```
+
+**Template Content**:
+```
+{d.customerType:ifEQ('VIP'):showBegin}
+Special Terms:
+As our VIP customer, you will enjoy additional benefits and exclusive services, including free upgrades, priority support, etc.
+{d.customerType:showEnd}
+```
+
+**Rendered Result** (when `customerType` is "VIP"):
+```
+Special Terms:
+As our VIP customer, you will enjoy additional benefits and exclusive services, including free upgrades, priority support, etc.
+```
+
+**Explanation**: When the value of the `customerType` field is "VIP", the content between `showBegin` and `showEnd` will be rendered; otherwise, it will be hidden.
+
+### Date Formatting
+
+Use formatters to convert date fields into more readable formats.
+
+**Syntax**:
+```
+{d.dateField:format(YYYY年MM月DD日)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "orderDate": "2025-01-03T10:30:00Z"
+}
+```
+
+**Template Content**:
+```
+Order Date: {d.orderDate:format(YYYY年MM月DD日)}
+```
+
+**Rendered Result**:
+```
+Order Date: 2025年01月03日
+```
+
+**Explanation**: The `format` formatter converts the ISO-formatted date into a more readable format.
+
+### Number Formatting
+
+Use formatters to format numbers, such as adding thousand separators or controlling decimal places.
+
+**Syntax**:
+```
+{d.numberField:format(0,0.00)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "totalAmount": 1234567.89
+}
+```
+
+**Template Content**:
+```
+Total Amount: {d.totalAmount:format('0,0.00')} yuan
+```
+
+**Rendered Result**:
+```
+Total Amount: 1,234,567.89 yuan
+```
+
+**Explanation**: The `format` formatter adds thousand separators and retains two decimal places for the number.
+
+## String Formatter Examples
+
+### 1. lowerCase( )
+
+**Syntax**:
+```
+{d.someField:lowerCase()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "title": "My Car"
+}
+```
+
+**Template Content**:
+```
+Vehicle Name: {d.title:lowerCase()}
+```
+
+**Rendered Result**:
+```
+Vehicle Name: my car
+```
+
+**Explanation**: Converts all English letters to lowercase. If the value is not a string (e.g., a number, null, etc.), it is output as is.
+
+---
+
+### 2. upperCase( )
+
+**Syntax**:
+```
+{d.someField:upperCase()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "title": "my car"
+}
+```
+
+**Template Content**:
+```
+Vehicle Name: {d.title:upperCase()}
+```
+
+**Rendered Result**:
+```
+Vehicle Name: MY CAR
+```
+
+**Explanation**: Converts all English letters to uppercase. If the value is not a string, it is output as is.
+
+---
+
+### 3. ucFirst( )
+
+**Syntax**:
+```
+{d.someField:ucFirst()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "note": "hello world"
+}
+```
+
+**Template Content**:
+```
+Note: {d.note:ucFirst()}
+```
+
+**Rendered Result**:
+```
+Note: Hello world
+```
+
+**Explanation**: Converts only the first letter to uppercase, leaving the rest of the letters unchanged. If the value is null or undefined, it returns null or undefined.
+
+---
+
+### 4. ucWords( )
+
+**Syntax**:
+```
+{d.someField:ucWords()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "description": "my cAR"
+}
+```
+
+**Template Content**:
+```
+Description: {d.description:ucWords()}
+```
+
+**Rendered Result**:
+```
+Description: My CAR
+```
+
+**Explanation**: Converts the first letter of each word in the string to uppercase. The rest of the letters remain unchanged.
+
+---
+
+### 5. print( message )
+
+**Syntax**:
+```
+{d.someField:print('Fixed Output')}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "unusedField": "whatever"
+}
+```
+
+**Template Content**:
+```
+Prompt: {d.unusedField:print('This will always display a fixed prompt')}
+```
+
+**Rendered Result**:
+```
+Prompt: This will always display a fixed prompt
+```
+
+**Explanation**: Regardless of the original data, the specified `message` string will be output, effectively "forcing" the output.
+
+---
+
+### 6. printJSON( )
+
+**Syntax**:
+```
+{d.someField:printJSON()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "items": [
+ { "id": 2, "name": "homer" },
+ { "id": 3, "name": "bart" }
+ ]
+}
+```
+
+**Template Content**:
+```
+Raw Data: {d.items:printJSON()}
+```
+
+**Rendered Result**:
+```
+Raw Data: [{"id":2,"name":"homer"},{"id":3,"name":"bart"}]
+```
+
+**Explanation**: Serializes an object or array into a JSON-formatted string for direct output in the template.
+
+---
+
+### 7. convEnum( type )
+
+**Syntax**:
+```
+{d.someField:convEnum('ENUM_NAME')}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "orderStatus": 1
+}
+```
+Assume the following configuration in `carbone.render(data, options)`'s `options.enum`:
+```json
+{
+ "enum": {
+ "ORDER_STATUS": [
+ "pending", // 0
+ "sent", // 1
+ "delivered" // 2
+ ]
+ }
+}
+```
+
+**Template Content**:
+```
+Order Status: {d.orderStatus:convEnum('ORDER_STATUS')}
+```
+
+**Rendered Result**:
+```
+Order Status: sent
+```
+
+**Explanation**: Converts a number or defined enum value into readable text; if the value is not defined in the enum, it is output as is.
+
+---
+
+### 8. unaccent( )
+
+**Syntax**:
+```
+{d.someField:unaccent()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "food": "crème brûlée"
+}
+```
+
+**Template Content**:
+```
+Food Name: {d.food:unaccent()}
+```
+
+**Rendered Result**:
+```
+Food Name: creme brulee
+```
+
+**Explanation**: Removes accent marks, commonly used for processing text with special characters in French, Spanish, etc.
+
+---
+
+### 9. convCRLF( )
+
+**Syntax**:
+```
+{d.someField:convCRLF()}
+```
+> **Note**: Applicable to DOCX, PDF, ODT, ODS (ODS functionality is experimental).
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "content": "Multi-line text:\nFirst line\nSecond line\r\nThird line"
+}
+```
+
+**Template Content**:
+```
+Converted Content:
+{d.content:convCRLF()}
+```
+**Rendering Result** (DOCX Scenario):
+```
+Converted Content:
+Multi-line Text:
+First Line
+Second Line
+Third Line
+```
+> The actual XML will insert line break tags such as ``.
+
+**Note**: Convert `\n` or `\r\n` to the correct line break tags in the document to accurately display multi-line text in the final file.
+
+---
+
+### 10. substr( begin, end, wordMode )
+
+**Syntax**:
+```
+{d.someField:substr(begin, end, wordMode)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "text": "abcdefg hijklmnop"
+}
+```
+
+**Template Content**:
+```
+Substring (from index 0 to 5): {d.text:substr(0, 5)}
+Substring (from index 6 to end): {d.text:substr(6)}
+```
+
+**Rendering Result**:
+```
+Substring (from index 0 to 5): abcde
+Substring (from index 6 to end): fg hijklmnop
+```
+
+**Note**:
+- `begin` is the starting index, `end` is the ending index (exclusive).
+- If `wordMode=true`, it tries not to split words; if `wordMode='last'`, it extracts from `begin` to the end of the string.
+
+---
+
+### 11. split( delimiter )
+
+**Syntax**:
+```
+{d.someField:split(delimiter)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "path": "ab/cd/ef"
+}
+```
+
+**Template Content**:
+```
+Split Array: {d.path:split('/')}
+```
+
+**Rendering Result**:
+```
+Split Array: ["ab","cd","ef"]
+```
+
+**Note**: Use the specified `delimiter` to split the string into an array. Can be used with other array operations such as `arrayJoin`, index access, etc.
+
+---
+
+### 12. padl( targetLength, padString )
+
+**Syntax**:
+```
+{d.someField:padl(targetLength, padString)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "code": "abc"
+}
+```
+
+**Template Content**:
+```
+Left Padding (length 8, character '0'): {d.code:padl(8, '0')}
+```
+
+**Rendering Result**:
+```
+Left Padding (length 8, character '0'): 00000abc
+```
+
+**Note**: If `targetLength` is less than the original string length, the original string is returned; the default padding character is a space.
+
+---
+
+### 13. padr( targetLength, padString )
+
+**Syntax**:
+```
+{d.someField:padr(targetLength, padString)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "code": "abc"
+}
+```
+
+**Template Content**:
+```
+Right Padding (length 10, character '#'): {d.code:padr(10, '#')}
+```
+
+**Rendering Result**:
+```
+Right Padding (length 10, character '#'): abc#######
+```
+
+**Note**: Opposite of `padl`, padding is done at the end of the string. The default padding character is a space.
+
+---
+
+### 14. ellipsis( maximum )
+
+**Syntax**:
+```
+{d.someField:ellipsis(maximum)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "articleTitle": "Carbone Report Extended Version"
+}
+```
+
+**Template Content**:
+```
+Article Title (max 5 characters): {d.articleTitle:ellipsis(5)}
+```
+
+**Rendering Result**:
+```
+Article Title (max 5 characters): Carbo...
+```
+
+**Note**: When the string length exceeds `maximum`, it truncates and adds `...`.
+
+---
+
+### 15. prepend( textToPrepend )
+
+**Syntax**:
+```
+{d.someField:prepend(textToPrepend)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "username": "john"
+}
+```
+
+**Template Content**:
+```
+Username: {d.username:prepend('Mr. ')}
+```
+
+**Rendering Result**:
+```
+Username: Mr. john
+```
+
+**Note**: Appends specified text before the original string, commonly used for prefixes.
+
+---
+
+### 16. append( textToAppend )
+
+**Syntax**:
+```
+{d.someField:append(textToAppend)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "filename": "document"
+}
+```
+
+**Template Content**:
+```
+Filename: {d.filename:append('.pdf')}
+```
+
+**Rendering Result**:
+```
+Filename: document.pdf
+```
+
+**Note**: Appends specified text after the original string, commonly used for suffixes.
+
+---
+
+### 17. replace( oldText, newText )
+
+**Syntax**:
+```
+{d.someField:replace(oldText, newText)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "sentence": "abcdef abcde"
+}
+```
+
+**Template Content**:
+```
+Replacement Result: {d.sentence:replace('cd', 'OK')}
+```
+
+**Rendering Result**:
+```
+Replacement Result: abOKef abOKe
+```
+
+**Note**: Replaces all occurrences of `oldText` with `newText`; if `newText` is not specified or is `null`, the matched parts are deleted.
+
+---
+
+### 18. len( )
+
+**Syntax**:
+```
+{d.someField:len()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "greeting": "Hello World",
+ "numbers": [1, 2, 3, 4, 5]
+}
+```
+
+**Template Content**:
+```
+Text Length: {d.greeting:len()}
+Array Length: {d.numbers:len()}
+```
+
+**Rendering Result**:
+```
+Text Length: 11
+Array Length: 5
+```
+
+**Note**: Can be used for both strings and arrays, returning their length or number of elements.
+
+---
+
+### 19. t( )
+
+**Syntax**:
+```
+{d.someField:t()}
+```
+
+**Example**:
+
+Assume you have defined a translation dictionary in Carbone configuration, translating the text `"Submit"` to `"提交"`.
+
+**Dataset**:
+```json
+{
+ "buttonLabel": "Submit"
+}
+```
+
+**Template Content**:
+```
+Button: {d.buttonLabel:t()}
+```
+
+**Rendering Result**:
+```
+Button: 提交
+```
+
+**Note**: Translates the string based on the translation dictionary. Requires providing the corresponding translation mapping during rendering.
+
+---
+
+### 20. preserveCharRef( )
+
+**Syntax**:
+```
+{d.someField:preserveCharRef()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "legalSymbol": "§"
+}
+```
+
+**Template Content**:
+```
+Symbol: {d.legalSymbol:preserveCharRef()}
+```
+
+**Rendering Result**:
+```
+Symbol: §
+```
+
+**Note**: Preserves character references in the form of `&#xxx;` or `&#xXXXX;`, preventing them from being escaped or replaced in XML. This is useful for generating specific character sets or special symbols.
+
+---
+The following examples follow the document style described above to help you better understand and apply **number operation** formatters. Examples will include **syntax**, **examples** (including "dataset", "template content", "rendering result"), and brief **notes**. Some examples will also mention optional rendering configurations (`options`) to demonstrate how they affect the output.
+
+---
+
+
+## Number Operation Formatter Examples
+
+### 1. convCurr( target, source )
+
+**Syntax**:
+```
+{d.numberField:convCurr(target, source)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "amount": 1000
+}
+```
+
+> Assume the following settings in `Carbone.render(data, options)`:
+> ```json
+> {
+> "currency": {
+> "source": "EUR",
+> "target": "USD",
+> "rates": {
+> "EUR": 1,
+> "USD": 2
+> }
+> }
+> }
+> ```
+
+**Template Content**:
+```
+Default conversion from EUR to USD: {d.amount:convCurr()}
+Directly specify target as USD: {d.amount:convCurr('USD')}
+Directly specify target as EUR: {d.amount:convCurr('EUR')}
+EUR->USD, then force USD->USD: {d.amount:convCurr('USD','USD')}
+```
+
+**Rendering Result**:
+```
+Default conversion from EUR to USD: 2000
+Directly specify target as USD: 2000
+Directly specify target as EUR: 1000
+EUR->USD, then force USD->USD: 1000
+```
+
+**Note**:
+- If `target` is not specified, it defaults to `options.currencyTarget` ("USD" in the example).
+- If `source` is not specified, it defaults to `options.currencySource` ("EUR" in the example).
+- If `options.currencySource` is not defined, no conversion is performed, and the original value is output.
+
+---
+
+### 2. round( precision )
+
+**Syntax**:
+```
+{d.numberField:round(precision)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "price": 10.05123,
+ "discount": 1.05
+}
+```
+
+**Template Content**:
+```
+Price rounded to 2 decimal places: {d.price:round(2)}
+Discount rounded to 1 decimal place: {d.discount:round(1)}
+```
+
+**Rendering Result**:
+```
+Price rounded to 2 decimal places: 10.05
+Discount rounded to 1 decimal place: 1.1
+```
+
+**Note**:
+Unlike `toFixed()`, `round()` uses correct rounding for decimals, e.g., `1.05` rounded to one decimal place becomes `1.1`.
+
+---
+
+### 3. formatN( precision )
+
+**Syntax**:
+```
+{d.numberField:formatN(precision)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "total": 1000.456
+}
+```
+
+> Assume in `Carbone.render(data, options)`, `options.lang` is `en-us`, and the document type is not ODS/XLSX (e.g., DOCX, PDF, etc.).
+
+**Template Content**:
+```
+Number Formatting: {d.total:formatN()}
+Number Formatting (2 decimal places): {d.total:formatN(2)}
+```
+
+**Rendering Result**:
+```
+Number Formatting: 1,000.456
+Number Formatting (2 decimal places): 1,000.46
+```
+
+**Note**:
+- `formatN()` localizes numbers based on `options.lang` (thousands separator, decimal point, etc.).
+- For ODS/XLSX files, number precision mainly depends on the cell format settings in the spreadsheet.
+
+---
+
+### 4. formatC( precisionOrFormat, targetCurrencyCode )
+
+**Syntax**:
+```
+{d.numberField:formatC(precisionOrFormat, targetCurrencyCode)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "amount": 1000.456
+}
+```
+
+> Assume the following settings in `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en-us",
+> "currency": {
+> "source": "EUR",
+> "target": "USD",
+> "rates": {
+> "EUR": 1,
+> "USD": 2
+> }
+> }
+> }
+> ```
+
+**Template Content**:
+```
+Default conversion with currency symbol: {d.amount:formatC()}
+Only output currency name (M): {d.amount:formatC('M')}
+Only output currency name, singular case: {1:formatC('M')}
+Number + symbol (L): {d.amount:formatC('L')}
+Number + currency name (LL): {d.amount:formatC('LL')}
+```
+
+**Rendering Result**:
+```
+Default conversion with currency symbol: $2,000.91
+Only output currency name (M): dollars
+Only output currency name, singular case: dollar
+Number + symbol (L): $2,000.00
+Number + currency name (LL): 2,000.00 dollars
+```
+
+**Note**:
+- `precisionOrFormat` can be a number (specifying decimal places) or a string ("M", "L", "LL").
+- To switch to another currency, pass `targetCurrencyCode`, e.g., `formatC('L', 'EUR')`.
+
+---
+
+### 5. add( )
+
+**Syntax**:
+```
+{d.numberField:add(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Add 2 to the value: {d.base:add(2)}
+```
+
+**Rendering Result**:
+```
+Add 2 to the value: 1002.4
+```
+
+**Note**: Adds the parameter to `d.base`, supports string numbers or pure numbers.
+
+---
+
+### 6. sub( )
+
+**Syntax**:
+```
+{d.numberField:sub(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Subtract 2 from the value: {d.base:sub(2)}
+```
+
+**Rendering Result**:
+```
+Subtract 2 from the value: 998.4
+```
+
+**Note**: Subtracts the parameter from `d.base`.
+
+---
+
+### 7. mul( )
+
+**Syntax**:
+```
+{d.numberField:mul(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Multiply the value by 2: {d.base:mul(2)}
+```
+
+**Rendering Result**:
+```
+Multiply the value by 2: 2000.8
+```
+
+**Note**: Multiplies `d.base` by the parameter.
+
+---
+
+### 8. div( )
+
+**Syntax**:
+```
+{d.numberField:div(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Divide the value by 2: {d.base:div(2)}
+```
+
+**Rendering Result**:
+```
+Divide the value by 2: 500.2
+```
+
+**Note**: Divides `d.base` by the parameter.
+
+---
+
+### 9. mod( value )
+
+**Syntax**:
+```
+{d.numberField:mod(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "num1": 4,
+ "num2": 3
+}
+```
+
+**Template Content**:
+```
+4 mod 2: {d.num1:mod(2)}
+3 mod 2: {d.num2:mod(2)}
+```
+
+**Rendering Result**:
+```
+4 mod 2: 0
+3 mod 2: 1
+```
+
+**Note**: Calculates `num1 % 2` and `num2 % 2`, used for modulo operations.
+
+---
+
+### 10. abs( )
+
+**Syntax**:
+```
+{d.numberField:abs()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "value1": -10,
+ "value2": -10.54
+}
+```
+
+**Template Content**:
+```
+Absolute Value 1: {d.value1:abs()}
+Absolute Value 2: {d.value2:abs()}
+```
+
+**Rendering Result**:
+```
+Absolute Value 1: 10
+Absolute Value 2: 10.54
+```
+
+**Note**: Returns the absolute value of the number, can also handle negative numbers in string format.
+
+---
+
+### 11. ceil( )
+
+**Syntax**:
+```
+{d.numberField:ceil()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "dataA": 10.05123,
+ "dataB": 1.05,
+ "dataC": -1.05
+}
+```
+
+**Template Content**:
+```
+ceil(10.05123): {d.dataA:ceil()}
+ceil(1.05): {d.dataB:ceil()}
+ceil(-1.05): {d.dataC:ceil()}
+```
+
+**Rendering Result**:
+```
+ceil(10.05123): 11
+ceil(1.05): 2
+ceil(-1.05): -1
+```
+
+**Note**: Rounds the number up to the nearest greater (or equal) integer.
+
+---
+
+### 12. floor( )
+
+**Syntax**:
+```
+{d.numberField:floor()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "dataA": 10.05123,
+ "dataB": 1.05,
+ "dataC": -1.05
+}
+```
+
+**Template Content**:
+```
+floor(10.05123): {d.dataA:floor()}
+floor(1.05): {d.dataB:floor()}
+floor(-1.05): {d.dataC:floor()}
+```
+
+**Rendering Result**:
+```
+floor(10.05123): 10
+floor(1.05): 1
+floor(-1.05): -2
+```
+
+**Note**: Rounds the number down to the nearest smaller (or equal) integer.
+
+---
+
+### 13. int( )
+
+> **Note**: **Not recommended**.
+> **Syntax**:
+```
+{d.numberField:int()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "price": 12.34
+}
+```
+
+**Template Content**:
+```
+Result: {d.price:int()}
+```
+
+**Rendering Result**:
+```
+Result: 12
+```
+
+**Note**: Converts the number to an integer by removing the decimal part; the official documentation recommends using more accurate `round()` or `floor()`/`ceil()` instead.
+
+---
+
+### 14. toEN( )
+
+> **Note**: **Not recommended**.
+> **Syntax**:
+```
+{d.numberField:toEN()}
+```
+
+**Note**: Converts numbers to English format with decimal point `.` separation, without localization. It is generally recommended to use `formatN()` for multi-language scenarios.
+
+---
+
+### 15. toFixed( )
+
+> **Note**: **Not recommended**.
+> **Syntax**:
+```
+{d.numberField:toFixed(decimalCount)}
+```
+
+**Description**: Converts a number to a string and retains the specified number of decimal places, but there may be inaccuracies in rounding. It is recommended to use `round()` or `formatN()` instead.
+
+---
+
+### 16. toFR( )
+
+> **Note**: **Not recommended for use**.
+> **Syntax**:
+```
+{d.numberField:toFR()}
+```
+
+**Description**: Converts a number to a format suitable for French locale with a comma `,` as the decimal separator, but does not perform further localization. It is recommended to use `formatN()` or `formatC()` for more flexibility in multilingual and currency scenarios.
+
+---
+
+## Array Manipulation
+
+### 1. aggStr( separator )
+> **Version**: ENTERPRISE FEATURE, NEWv4.17.0+
+> **Function**: Merges values in an array into a single string, concatenated with an optional `separator`. If no separator is provided, it defaults to `,`.
+
+**Syntax**:
+```
+{d.arrayField[].someAttr:aggStr(separator)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "cars": [
+ {"brand":"Tesla","qty":1,"sort":1},
+ {"brand":"Ford","qty":4,"sort":4},
+ {"brand":"Jeep","qty":3,"sort":3},
+ {"brand":"GMC","qty":2,"sort":2},
+ {"brand":"Rivian","qty":1,"sort":1},
+ {"brand":"Chevrolet","qty":10,"sort":5}
+ ]
+}
+```
+
+**Template Content**:
+```
+All brands (default comma separator):
+{d.cars[].brand:aggStr}
+
+All brands (specified hyphen separator):
+{d.cars[].brand:aggStr(' - ')}
+
+Filtered brands with qty greater than 3:
+{d.cars[.qty > 3].brand:aggStr()}
+```
+
+**Rendered Result**:
+```
+All brands (default comma separator):
+Tesla, Ford, Jeep, GMC, Rivian, Chevrolet
+
+All brands (specified hyphen separator):
+Tesla - Ford - Jeep - GMC - Rivian - Chevrolet
+
+Filtered brands with qty greater than 3:
+Ford, Chevrolet
+```
+
+**Description**:
+- Use `:aggStr` to extract and merge fields in an array, which can be combined with filtering conditions (e.g., `[.qty > 3]`) for more flexible output.
+- The `separator` parameter can be omitted, defaulting to a comma followed by a space (`, `).
+
+---
+
+### 2. arrayJoin( separator, index, count )
+> **Version**: NEWv4.12.0+
+> **Function**: Merges array elements (`String` or `Number`) into a single string; optionally specifies which segment of the array to start merging from.
+
+**Syntax**:
+```
+{d.arrayField:arrayJoin(separator, index, count)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "names": ["homer", "bart", "lisa"],
+ "emptyArray": [],
+ "notArray": 20
+}
+```
+
+**Template Content**:
+```
+Default comma separator: {d.names:arrayJoin()}
+Using " | " separator: {d.names:arrayJoin(' | ')}
+Using empty string separator: {d.names:arrayJoin('')}
+Merging all elements starting from the second item: {d.names:arrayJoin('', 1)}
+Merging 1 element starting from the second item: {d.names:arrayJoin('', 1, 1)}
+Merging from the first item to the second last item: {d.names:arrayJoin('', 0, -1)}
+
+Empty array: {d.emptyArray:arrayJoin()}
+Non-array data: {d.notArray:arrayJoin()}
+```
+
+**Rendered Result**:
+```
+Default comma separator: homer, bart, lisa
+Using " | " separator: homer | bart | lisa
+Using empty string separator: homerbartlisa
+Merging all elements starting from the second item: bartlisa
+Merging 1 element starting from the second item: bart
+Merging from the first item to the second last item: homerbart
+
+Empty array:
+Non-array data: 20
+```
+
+**Description**:
+- `separator` defaults to a comma followed by a space (`, `).
+- `index` and `count` are used to extract a portion of the array; `count` can be negative to indicate counting from the end.
+- If the data is not of array type (`null`, `undefined`, object, or number), it will be output as is.
+
+---
+
+### 3. arrayMap( objSeparator, attributeSeparator, attributes )
+> **Version**: v0.12.5+
+> **Function**: Maps an array of objects into a string. Allows specifying separators between objects and attributes, as well as which attributes to output.
+
+**Syntax**:
+```
+{d.arrayField:arrayMap(objSeparator, attributeSeparator, attributes)}
+```
+
+**Example**:
+
+```json
+{
+ "people": [
+ { "id": 2, "name": "homer" },
+ { "id": 3, "name": "bart" }
+ ],
+ "numbers": [10, 50],
+ "emptyArray": [],
+ "mixed": {"id":2,"name":"homer"}
+}
+```
+
+**Template Content**:
+```
+Default mapping (using comma+space as object separator, colon as attribute separator):
+{d.people:arrayMap()}
+
+Using " - " as object separator:
+{d.people:arrayMap(' - ')}
+
+Using " | " as attribute separator:
+{d.people:arrayMap(' ; ', '|')}
+
+Mapping only id:
+{d.people:arrayMap(' ; ', '|', 'id')}
+
+Numeric array:
+{d.numbers:arrayMap()}
+
+Empty array:
+{d.emptyArray:arrayMap()}
+
+Non-array data:
+{d.mixed:arrayMap()}
+```
+
+**Rendered Result**:
+```
+Default mapping:
+2:homer, 3:bart
+
+Using " - " as object separator:
+2:homer - 3:bart
+
+Using " | " as attribute separator:
+2|homer ; 3|bart
+
+Mapping only id:
+2 ; 3
+
+Numeric array:
+10, 50
+
+Empty array:
+
+Non-array data:
+{ "id": 2, "name": "homer" }
+```
+
+**Description**:
+- If it is an array of objects, all available first-level attributes are output by default, concatenated in the form `attributeName:attributeValue`.
+- `objSeparator` is used to separate different objects, defaulting to a comma followed by a space; `attributeSeparator` separates attributes, defaulting to a colon `:`; `attributes` can specify which attributes to output.
+- If the input data is not an array, it is output as is.
+
+---
+
+### 4. count( start )
+> **Version**: v1.1.0+
+> **Function**: Prints a **line number** or **sequence number** in a loop (e.g., `{d.array[i].xx}`), starting from 1 by default.
+> **Note**: Starting from v4.0.0, this function has been internally replaced by `:cumCount`.
+
+**Syntax**:
+```
+{d.array[i].someField:count(start)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "employees": [
+ { "name": "James" },
+ { "name": "Emily" },
+ { "name": "Michael" }
+ ]
+}
+```
+
+**Template Content**:
+```
+Employee List:
+No. | Name
+{d.employees[i].name:count()}. {d.employees[i].name}
+{d.employees[i+1]}
+```
+
+**Rendered Result**:
+```
+Employee List:
+No. | Name
+1. James
+2. Emily
+3. Michael
+```
+
+**Description**:
+- Only valid in loops (including scenarios like `{d.array[i].xx}`), used to print the current line index count.
+- `start` can specify a starting number, e.g., `:count(5)` will start counting from 5.
+- Carbone 4.0+ recommends using `:cumCount` for more flexibility.
+
+---
+
+# Conditioned Output
+
+Carbone provides a series of condition-based output formatters to **hide** or **display** specified content in templates based on specific conditions. Depending on business needs, you can choose **`drop`/`keep`** (concise usage) or **`showBegin`/`showEnd`**, **`hideBegin`/`hideEnd`** (suitable for large sections of content).
+
+### 1. drop(element)
+> **Version**: ENTERPRISE FEATURE, UPDATEDv4.22.10+
+> **Function**: If the condition is true, **deletes** an element or several elements in the document, such as paragraphs, table rows, images, charts, etc.
+
+**Syntax**:
+```
+{d.data:ifEM():drop(element, nbrToDrop)}
+```
+- `element`: Can be `p` (paragraph), `row` (table row), `img` (image), `table` (entire table), `chart` (chart), `shape` (shape), `slide` (slide, ODP only), or `item` (list item, ODP/ODT only).
+- `nbrToDrop`: Optional, an integer indicating how many elements to delete starting from the current one.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "imgUrl": null
+}
+```
+
+**Template Content** (DOCX scenario, simplified example):
+```
+Here is an image: {d.imgUrl:ifEM:drop(img)}
+```
+
+- In the Word template, place this placeholder in the image's title or description.
+
+**Rendered Result**:
+```
+Here is an image:
+```
+> The image is deleted because `imgUrl` is empty (`ifEM` is true).
+
+**Description**:
+- If the `ifEM` condition is met, `drop(img)` is executed, deleting the image and its associated paragraph content.
+- `drop` is only supported in DOCX/ODT/ODS/ODP/PPTX/PDF/HTML; once `drop` is executed, no other formatters are executed.
+
+---
+
+### 2. keep(element)
+> **Version**: ENTERPRISE FEATURE, NEWv4.17.0+
+> **Function**: If the condition is true, **retains/displays** an element or several elements in the document; otherwise, it does not display them.
+
+**Syntax**:
+```
+{d.data:ifNEM:keep(element, nbrToKeep)}
+```
+- `element`: Same as `drop`, can be `p`, `row`, `img`, `table`, `chart`, `shape`, `slide`, `item`, etc.
+- `nbrToKeep`: Optional, an integer indicating how many elements to retain starting from the current one.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "tableData": []
+}
+```
+
+**Template Content** (DOCX scenario, simplified example):
+```
+{d.tableData:ifNEM:keep(table)}
+```
+
+- In the Word template, place this placeholder in a cell within the table.
+
+**Rendered Result**:
+```
+(Blank)
+```
+> Since `tableData` is empty, `ifNEM` is false (not empty fails), so the table is not retained, and the entire table is deleted.
+
+**Description**:
+- If the condition is met, the corresponding element is retained; otherwise, the element and all its content are deleted.
+- Opposite to `drop`, `keep` deletes the element when the condition is not met.
+
+---
+
+### 3. showBegin()/showEnd()
+> **Version**: COMMUNITY FEATURE, v2.0.0+
+> **Function**: Displays the content between `showBegin` and `showEnd` (which can include multiple paragraphs, tables, images, etc.), retaining this section if the condition is true, otherwise deleting it.
+
+**Syntax**:
+```
+{d.someData:ifEQ(someValue):showBegin}
+...Content to display...
+{d.someData:showEnd}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "toBuy": true
+}
+```
+
+**Template Content**:
+```
+Banana{d.toBuy:ifEQ(true):showBegin}
+Apple
+Pineapple
+{d.toBuy:showEnd}grapes
+```
+
+**Rendered Result**:
+```
+Banana
+Apple
+Pineapple
+grapes
+```
+> When `toBuy` is `true`, all content between `showBegin` and `showEnd` is displayed.
+
+**Description**:
+- Suitable for **multi-line or multi-page** content hiding and displaying; if it's just a single line, consider using `keep`/`drop` for a more concise approach.
+- It is recommended to use only **line breaks (Shift+Enter)** between `showBegin` and `showEnd` to ensure proper rendering.
+
+---
+
+### 4. hideBegin()/hideEnd()
+> **Version**: COMMUNITY FEATURE, v2.0.0+
+> **Function**: Hides the content between `hideBegin` and `hideEnd`, deleting this section if the condition is true, otherwise retaining it.
+
+**Syntax**:
+```
+{d.someData:ifEQ(someValue):hideBegin}
+...Content to hide...
+{d.someData:hideEnd}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "toBuy": true
+}
+```
+
+**Template Content**:
+```
+Banana{d.toBuy:ifEQ(true):hideBegin}
+Apple
+Pineapple
+{d.toBuy:hideEnd}grapes
+```
+
+**Rendered Result**:
+```
+Banana
+grapes
+```
+> When `toBuy` is `true`, the content between `hideBegin` and `hideEnd` (Apple, Pineapple) is hidden.
+
+**Description**:
+- Opposite to `showBegin()/showEnd()`, used to hide multiple paragraphs, tables, images, etc.
+- Similarly, it is recommended to use only **line breaks (Shift+Enter)** between `hideBegin` and `hideEnd`.
+
+---
+
+## Date and Time Operation Formatter Examples
+
+> **Note**: Starting from v3.0.0, Carbone uses [Day.js](https://day.js.org/docs/en/display/format) for date processing. Most formats related to Moment.js are still available in Day.js, but the underlying library has been replaced with Day.js.
+
+### 1. Usage of {c.now}
+
+In templates, you can use `{c.now}` to get the current UTC time (`now`), provided that no custom data is passed through `options.complement` to override it during rendering. Example:
+
+**Dataset** (can be empty or without `c` field):
+```json
+{}
+```
+
+**Template Content**:
+```
+Current time: {c.now:formatD('YYYY-MM-DD HH:mm:ss')}
+```
+
+**Rendered Result** (example):
+```
+Current time: 2025-01-07 10:05:30
+```
+
+**Description**:
+- `{c.now}` is a reserved tag that automatically inserts the system's current UTC time.
+- Use with `:formatD()` and other formatters to output in the specified format.
+
+---
+
+### 2. formatD( patternOut, patternIn )
+
+**Syntax**:
+```
+{d.dateField:formatD(patternOut, patternIn)}
+```
+
+- `patternOut`: The output date format, conforming to Day.js format specifications or localized formats (e.g., `L`, `LL`, `LLLL`, etc.).
+- `patternIn`: The input date format, defaulting to ISO 8601, can specify formats like `YYYYMMDD`, `X` (Unix timestamp), etc.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "eventDate": "20160131"
+}
+```
+
+> Assume during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+Date (short format): {d.eventDate:formatD('L')}
+Date (full English): {d.eventDate:formatD('LLLL')}
+Day of the week: {d.eventDate:formatD('dddd')}
+```
+
+**Rendered Result**:
+```
+Date (short format): 01/31/2016
+Date (full English): Sunday, January 31, 2016 12:00 AM
+Day of the week: Sunday
+```
+
+**Description**:
+- If `patternIn` is not specified, it defaults to ISO 8601, but here `20160131` can also be automatically recognized. To explicitly specify, use `{d.eventDate:formatD('L', 'YYYYMMDD')}`.
+- `options.lang` and `options.timezone` affect the output language and timezone conversion.
+
+---
+
+### 3. formatI( patternOut, patternIn )
+
+**Syntax**:
+```
+{d.durationField:formatI(patternOut, patternIn)}
+```
+
+- `patternOut`: The output format, can be `human`, `human+`, `milliseconds/ms`, `seconds/s`, `minutes/m`, `hours/h`, `days/d`, `weeks/w`, `months/M`, `years/y`, etc.
+- `patternIn`: Optional, the input unit defaults to milliseconds, can also specify `seconds`, `minutes`, `hours`, `days`, etc.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "intervalMs": 2000,
+ "longIntervalMs": 3600000
+}
+```
+
+> Assume during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+2000 milliseconds to seconds: {d.intervalMs:formatI('second')}
+3600000 milliseconds to minutes: {d.longIntervalMs:formatI('minute')}
+3600000 milliseconds to hours: {d.longIntervalMs:formatI('hour')}
+```
+
+**Rendering Result**:
+```
+2000 milliseconds to seconds: 2
+3600000 milliseconds to minutes: 60
+3600000 milliseconds to hours: 1
+```
+
+**Explanation**:
+- Convert time intervals between units, or output human-readable time (e.g., `human`/`human+`) to display "a few seconds ago" or "in a few minutes."
+- For handling positive and negative values, `human+` will output "...ago" or "in a few ...", while `human` only outputs expressions like "a few seconds" without direction.
+
+---
+
+### 4. addD( amount, unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:addD(amount, unit, patternIn)}
+```
+
+- `amount`: A number or string indicating the quantity to add.
+- `unit`: Available units include `day`, `week`, `month`, `year`, `hour`, `minute`, `second`, `millisecond` (case-insensitive, and supports plural and abbreviations).
+- `patternIn`: Optional, specifies the input date format, defaults to ISO8601.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "startDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+> Assuming during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "fr",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+Add 3 days to startDate: {d.startDate:addD('3', 'day')}
+Add 3 months to startDate: {d.startDate:addD('3', 'month')}
+```
+
+**Rendering Result**:
+```
+Add 3 days to startDate: 2017-05-13T12:57:23.769Z
+Add 3 months to startDate: 2017-08-10T12:57:23.769Z
+```
+
+**Explanation**:
+- The result is displayed in UTC time. To localize the output, use formatters like `formatD('YYYY-MM-DD HH:mm')`.
+- If the input date is in a format like `20160131` and `patternIn` is not explicitly specified, Day.js may automatically recognize it. However, it is recommended to use `{d.field:addD('...', '...', 'YYYYMMDD')}` for accuracy.
+
+---
+
+### 5. subD( amount, unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:subD(amount, unit, patternIn)}
+```
+
+- Similar to `addD()`, but moves the date backward.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "myDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**Template Content**:
+```
+Subtract 3 days from myDate: {d.myDate:subD('3', 'day')}
+Subtract 3 months from myDate: {d.myDate:subD('3', 'month')}
+```
+
+**Rendering Result**:
+```
+Subtract 3 days from myDate: 2017-05-07T12:57:23.769Z
+Subtract 3 months from myDate: 2017-02-10T12:57:23.769Z
+```
+
+**Explanation**:
+- Opposite to `addD`, `subD` moves the date in the past direction.
+- Supports the same units and format configurations.
+
+---
+
+### 6. startOfD( unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:startOfD(unit, patternIn)}
+```
+
+- `unit`: `day`, `month`, `year`, `week`, etc., sets the date to the start of the unit (e.g., `day`=midnight, `month`=1st 00:00:00, etc.).
+- `patternIn`: Optional, specifies the input date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "someDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**Template Content**:
+```
+Set someDate to the start of the day: {d.someDate:startOfD('day')}
+Set someDate to the start of the month: {d.someDate:startOfD('month')}
+```
+
+**Rendering Result**:
+```
+Set someDate to the start of the day: 2017-05-10T00:00:00.000Z
+Set someDate to the start of the month: 2017-05-01T00:00:00.000Z
+```
+
+**Explanation**:
+- Commonly used in scenarios like report statistics or aligning to a specific time granularity.
+
+---
+
+### 7. endOfD( unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:endOfD(unit, patternIn)}
+```
+
+- `unit`: `day`, `month`, `year`, etc., sets the date to the end of the unit (e.g., `day`=23:59:59.999, `month`=last day 23:59:59.999, etc.).
+- `patternIn`: Optional, specifies the input date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "someDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**Template Content**:
+```
+Set someDate to the end of the day: {d.someDate:endOfD('day')}
+Set someDate to the end of the month: {d.someDate:endOfD('month')}
+```
+
+**Rendering Result**:
+```
+Set someDate to the end of the day: 2017-05-10T23:59:59.999Z
+Set someDate to the end of the month: 2017-05-31T23:59:59.999Z
+```
+
+**Explanation**:
+- Corresponds to `startOfD`, pushing the date to the last moment of the day, month, or year.
+
+---
+
+### 8. diffD( toDate, unit, patternFromDate, patternToDate )
+
+**Syntax**:
+```
+{d.fromDate:diffD(toDate, unit, patternFromDate, patternToDate)}
+```
+
+- `toDate`: The target date for comparison, which can be a string or number (Unix timestamp).
+- `unit`: Optional, supports `day/d`, `week/w`, `month/M`, `year/y`, `hour/h`, `minute/m`, `second/s`, `millisecond/ms`, defaults to milliseconds.
+- `patternFromDate` / `patternToDate`: Optional, specifies the input date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "start": "20101001"
+}
+```
+
+**Template Content**:
+```
+Default millisecond interval: {d.start:diffD('20101201')}
+In seconds: {d.start:diffD('20101201', 'second')}
+In days: {d.start:diffD('20101201', 'days')}
+```
+
+**Rendering Result**:
+```
+Default millisecond interval: 5270400000
+In seconds: 5270400
+In days: 61
+```
+
+**Explanation**:
+- If the original date format differs from the target date format, specify them using `patternFromDate` and `patternToDate`.
+- A positive difference indicates that `toDate` is later or larger than `fromDate`; a negative difference indicates the opposite.
+
+---
+
+### 9. convDate( patternIn, patternOut )
+
+> **Note**: **Not Recommended**
+> Starting from v3.0.0, it is officially recommended to use `formatD(patternOut, patternIn)`, which offers more flexibility and better compatibility with Day.js.
+
+**Syntax**:
+```
+{d.dateField:convDate(patternIn, patternOut)}
+```
+
+- `patternIn`: Input date format.
+- `patternOut`: Output date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "myDate": "20160131"
+}
+```
+
+> Assuming during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+Short date: {d.myDate:convDate('YYYYMMDD', 'L')}
+Full date: {d.myDate:convDate('YYYYMMDD', 'LLLL')}
+```
+
+**Rendering Result**:
+```
+Short date: 01/31/2016
+Full date: Sunday, January 31, 2016 12:00 AM
+```
+
+**Explanation**:
+- Similar to `formatD`, but marked as **Not Recommended** (UNRECOMMENDED).
+- It is recommended to use `formatD` in new projects.
+
+---
+
+### Day.js Date Format Cheatsheet
+
+The following common formats can be used in `patternOut` (partial examples):
+
+| Format | Example Output | Description |
+|:---- |:------------------------ |:------------------------------------------------ |
+| `X` | `1360013296` | Unix timestamp (in seconds) |
+| `x` | `1360013296123` | Unix timestamp in milliseconds |
+| `YYYY` | `2025` | Four-digit year |
+| `MM` | `01-12` | Two-digit month |
+| `DD` | `01-31` | Two-digit day |
+| `HH` | `00-23` | Two-digit hour in 24-hour format |
+| `mm` | `00-59` | Two-digit minutes |
+| `ss` | `00-59` | Two-digit seconds |
+| `dddd` | `Sunday-Saturday` | Full name of the day of the week |
+| `ddd` | `Sun-Sat` | Abbreviated name of the day of the week |
+| `A` | `AM` / `PM` | Uppercase AM/PM |
+| `a` | `am` / `pm` | Lowercase am/pm |
+| `L` | `MM/DD/YYYY` | Localized short date format |
+| `LL` | `MMMM D, YYYY` | Localized date with full month name |
+| `LLL` | `MMMM D, YYYY h:mm A` | Localized date with time and full month name |
+| `LLLL` | `dddd, MMMM D, YYYY h:mm A` | Full localized date with day of the week |
+
+For more formats, refer to the [Day.js official documentation](https://day.js.org/docs/en/display/format) or the list above.
+
+---
+
+## Other Condition Controllers
+
+Carbone provides various **conditionals** (`ifEQ`, `ifNE`, `ifGT`, `ifGTE`, `ifLT`, `ifLTE`, `ifIN`, `ifNIN`, `ifEM`, `ifNEM`, `ifTE`, etc.), as well as **logical combinations** (`and()`, `or()`) and **branch outputs** (`show(message)`, `elseShow(message)`). These can be combined to implement flexible conditional logic in templates. Below are some common examples; for more details, refer to the official documentation:
+
+- **ifEM()**: Checks if the value is empty (`null`, `undefined`, `[]`, `{}`, `""`, etc.).
+- **ifNEM()**: Checks if the value is not empty.
+- **ifEQ(value)** / **ifNE(value)** / **ifGT(value)** / **ifGTE(value)** / **ifLT(value)** / **ifLTE(value)**: Standard comparison operations.
+- **ifIN(value)** / **ifNIN(value)**: Checks if a string or array contains the specified content.
+- **ifTE(type)**: Checks the data type (string, number, array, object, boolean, binary, etc.).
+- **and(value)** / **or(value)**: Changes the default logical connection method.
+- **show(message)** / **elseShow(message)**: Outputs the corresponding message string when the condition is true or false.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "status1": 1,
+ "status2": 2,
+ "status3": 3
+}
+```
+
+**Template Content**:
+```
+one = { d.status1:ifEQ(2):show(two):or(.status1):ifEQ(1):show(one):elseShow(unknown) }
+
+two = { d.status2:ifEQ(2):show(two):or(.status2):ifEQ(1):show(one):elseShow(unknown) }
+
+three = { d.status3:ifEQ(2):show(two):or(.status3):ifEQ(1):show(one):elseShow(unknown) }
+```
+
+**Rendering Result**:
+```
+one = "one"
+two = "two"
+three = "unknown"
+```
+
+**Explanation**:
+- `:ifEQ(2):show(two)` means if the value equals 2, output "two"; otherwise, proceed to the next condition (`or(.status1):ifEQ(1):show(one)`).
+- `or()` and `and()` are used to configure logical operators.
+- `elseShow('unknown')` outputs "unknown" when all preceding conditions are false.
+
+---
+
+Through **array operations** and **conditional output** examples, you can:
+1. **Flexibly handle arrays**: Use `:aggStr`, `:arrayJoin`, `:arrayMap`, `:count`, etc., to achieve **merging, concatenation, mapping**, and **counting**.
+2. **Precisely control content display**: Use `drop` / `keep` or `showBegin` / `showEnd` / `hideBegin` / `hideEnd` to decide whether to retain **specific elements** or **large sections of content** in the document based on conditions (`ifEQ`, `ifGT`, etc.).
+3. **Combine multiple conditions**: Work with number and string-related formatters (e.g., `ifNEM`, `ifIN`, etc.) to implement more complex business logic control.
+---
+
+The following examples continue the previous documentation style, demonstrating the usage of **date and time operation** related formatters. To better understand the purpose of each formatter, the examples include **syntax**, **examples** (with "dataset," "template content," and "rendering result"), and necessary **explanations**. Some formatters can be used in conjunction with rendering configuration (`options`) such as timezone (`timezone`) and language (`lang`) for more flexible date and time handling.
+
+---
+
+## Common Issues and Solutions
+
+### 1. Empty Columns and Cells in Excel Templates Disappear in Rendering Results
+
+**Issue Description**: In Excel templates, if a cell has no content or style, it may be removed during rendering, causing the cell to be missing in the final document.
+
+**Solution**:
+
+- **Fill Background Color**: Fill the background color of the target empty cells to ensure they remain visible during rendering.
+- **Insert Space**: Insert a space character in empty cells to maintain the cell structure even if there is no actual content.
+- **Set Borders**: Add border styles to the table to enhance the cell boundaries and prevent cells from disappearing during rendering.
+
+**Example**:
+
+In the Excel template, set a light gray background for all target cells and insert a space in empty cells.
+
+### 2. Merged Cells Are Invalid in Output
+
+**Issue Description**: When using loop functions to output tables, if the template contains merged cells, it may cause rendering anomalies, such as loss of merging effects or data misalignment.
+
+**Solution**:
+
+- **Avoid Merged Cells**: Avoid using merged cells in loop-output tables to ensure correct data rendering.
+- **Use Center Across Selection**: If you need text to be centered across multiple cells horizontally, use the "Center Across Selection" feature instead of merging cells.
+- **Limit Merged Cell Locations**: If merged cells are necessary, only merge cells at the top or right side of the table to prevent loss of merging effects during rendering.
+
+**Example**:
+
+**Incorrect Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Merging cells in the "Department" column may cause rendering anomalies.*
+
+**Correct Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Keep each cell independent and avoid merging cells.*
+
+### 3. Error Messages During Template Rendering
+
+**Issue Description**: During the template rendering process, the system displays an error message, causing the rendering to fail.
+
+**Possible Causes**:
+
+- **Placeholder Error**: The placeholder name does not match the dataset field or there is a syntax error.
+- **Missing Data**: The dataset lacks fields referenced in the template.
+- **Improper Use of Formatters**: Incorrect formatter parameters or unsupported formatting types.
+
+**Solutions**:
+
+- **Check Placeholders**: Ensure that the placeholder names in the template match the field names in the dataset and that the syntax is correct.
+- **Validate Dataset**: Confirm that the dataset includes all fields referenced in the template and that the data format meets the requirements.
+- **Adjust Formatters**: Check the usage of formatters, ensure the parameters are correct, and use supported formatting types.
+
+**Example**:
+
+**Faulty Template**:
+```
+Order ID: {d.orderId}
+Order Date: {d.orderDate:format('YYYY/MM/DD')}
+Total Amount: {d.totalAmount:format('0.00')}
+```
+
+**Dataset**:
+```json
+{
+ "orderId": "A123456789",
+ "orderDate": "2025-01-01T10:00:00Z"
+ // Missing totalAmount field
+}
+```
+
+**Solution**: Add the `totalAmount` field to the dataset or remove the reference to `totalAmount` from the template.
+
+### 4. Template File Upload Failure
+
+**Issue Description**: When uploading a template file on the template configuration page, the upload fails.
+
+**Possible Causes**:
+
+- **Unsupported File Format**: The uploaded file format is not supported (only `.docx`, `.xlsx`, and `.pptx` are supported).
+- **File Size Too Large**: The template file is too large, exceeding the system's upload size limit.
+- **Network Issues**: Unstable network connection causing the upload to be interrupted or fail.
+
+**Solutions**:
+
+- **Check File Format**: Ensure the uploaded template file is in `.docx`, `.xlsx`, or `.pptx` format.
+- **Compress File Size**: If the file is too large, try compressing the template file or optimizing the template content to reduce the file size.
+- **Stabilize Network Connection**: Ensure a stable network connection and try the upload operation again.
+
+## Summary
+
+The template printing plugin offers powerful features, supporting template editing and dynamic data filling for various file formats. By configuring and using rich template syntax effectively, customized documents can be generated efficiently to meet different business needs, enhancing work efficiency and document quality.
+
+**Key Advantages**:
+
+- **Efficiency**: Automated data filling reduces manual operations and improves work efficiency.
+- **Flexibility**: Supports multiple template formats and complex data structures, adapting to diverse document needs.
+- **Professionalism**: Formatters and conditional output functions enhance the professionalism and readability of documents.
+
+## Frequently Asked Questions
+
+### 1. Empty Columns and Cells Disappear in Excel Template Rendering
+
+**Issue Description**: In an Excel template, if a cell has no content or style, it might be removed during rendering, causing the cell to be missing in the final document.
+
+**Solutions**:
+
+- **Fill Background Color**: Fill the background color for empty cells in the target area to ensure the cells remain visible during rendering.
+- **Insert Space**: Insert a space character in empty cells to maintain the cell structure even if there is no actual content.
+- **Set Borders**: Add border styles to the table to enhance the boundary of cells and prevent them from disappearing during rendering.
+
+**Example**:
+
+In the Excel template, set a light gray background for all target cells and insert a space in empty cells.
+
+### 2. Merged Cells Are Ineffective in Output
+
+**Issue Description**: When using loop functions to output tables, if merged cells exist in the template, it may cause rendering anomalies such as loss of merging effects or data misalignment.
+
+**Solutions**:
+
+- **Avoid Using Merged Cells**: Try to avoid using merged cells in tables output by loops to ensure correct data rendering.
+- **Use Center Across Columns**: If text needs to be centered across multiple cells, use the "Center Across Columns" function instead of merging cells.
+- **Limit Merged Cell Locations**: If merged cells must be used, merge cells only at the top or right side of the table to prevent loss of merging effects during rendering.
+
+**Example**:
+
+**Incorrect Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Merging cells in the "Department" column may cause rendering anomalies.*
+
+**Correct Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Keep each cell independent and avoid merging cells.*
diff --git a/docs/en-US/handbook/backups/install.md b/docs/en-US/handbook/backups/install.md
index 8f8100a2e..beb0496fe 100644
--- a/docs/en-US/handbook/backups/install.md
+++ b/docs/en-US/handbook/backups/install.md
@@ -1,18 +1,18 @@
-### 安装数据库客户端
+### Install Database Client
-前往官网下载与所使用的数据库版本匹配的客户端:
+Visit the official website to download the client that matches the version of the database you are using:
-- MySQL:https://dev.mysql.com/downloads/
-- PostgreSQL:https://www.postgresql.org/download/
+- MySQL: https://dev.mysql.com/downloads/
+- PostgreSQL: https://www.postgresql.org/download/
-Docker 版本,可以直接在 `./storage/scripts` 目录下,编写一段脚本
+For Docker versions, you can directly write a script in the `./storage/scripts` directory
```bash
mkdir ./storage/scripts
vim install-database-client.sh
```
-`install-database-client.sh` 的内容如下:
+The content of `install-database-client.sh` is as follows:
@@ -94,15 +94,15 @@ fi
-然后重启 app 容器
+Then restart the app container
```bash
docker compose restart app
-# 查看日志
+# View logs
docker compose logs app
```
-查看数据库客户端版本号,必须与数据库服务端的版本号一致
+Check the database client version number, which must match the database server version number
@@ -120,6 +120,6 @@ docker compose exec app bash -c "mysql -V"
-### 安装插件
+### Install Plugins
-参考 [商业插件的安装与升级](/welcome/getting-started/plugin)
+Refer to [Installation and Upgrade of Commercial Plugins](/welcome/getting-started/plugin)
\ No newline at end of file
diff --git a/docs/en-US/handbook/environment-variables/index.md b/docs/en-US/handbook/environment-variables/index.md
index 4059f4661..3c89eb248 100644
--- a/docs/en-US/handbook/environment-variables/index.md
+++ b/docs/en-US/handbook/environment-variables/index.md
@@ -1,97 +1,97 @@
-# 环境变量
+# Environment Variables
-## 介绍
+## Introduction
-集中配置和管理环境变量和密钥,用于敏感数据存储、配置数据重用、环境配置隔离等。
+Centralized configuration and management of environment variables and secrets for sensitive data storage, configuration data reuse, and environment configuration isolation.
-## 与 `.env` 的区别
+## Differences from `.env`
-| **特性** | **`.env` 文件** | **动态配置的环境变量** |
+| **Feature** | **`.env` File** | **Dynamic Configuration Environment Variables** |
|-----------------------|--------------------------------|-------------------------------------|
-| **存储位置** | 存储在项目根目录的 `.env` 文件中 | 存储在数据库 `environmentVariables` 表里 |
-| **加载方式** | 通过 `dotenv` 等工具在应用启动时加载到 `process.env` 中 | 动态读取,在应用启动时加载到 `app.environment` 中 |
-| **修改方式** | 需要直接编辑文件,修改后需要重启应用才能生效 | 支持在运行时修改,修改后直接重载应用配置即可 |
-| **环境隔离** | 每个环境(开发、测试、生产)需要单独维护 `.env` 文件 | 每个环境(开发、测试、生产)需要单独维护 `environmentVariables` 表的数据 |
-| **适用场景** | 适合固定的静态配置,如应用主数据库信息 | 适合需要频繁调整或与业务逻辑绑定的动态配置,如外部数据库、文件存储等信息 |
+| **Storage Location** | Stored in the `.env` file in the project root directory | Stored in the `environmentVariables` table in the database |
+| **Loading Method** | Loaded into `process.env` using tools like `dotenv` during application startup | Dynamically read and loaded into `app.environment` during application startup |
+| **Modification Method** | Requires direct file editing, and the application needs to be restarted for changes to take effect | Supports runtime modification, changes take effect immediately after reloading the application configuration |
+| **Environment Isolation** | Each environment (development, testing, production) requires separate maintenance of `.env` files | Each environment (development, testing, production) requires separate maintenance of data in the `environmentVariables` table |
+| **Applicable Scenarios** | Suitable for fixed static configurations, such as main database information for the application | Suitable for dynamic configurations that require frequent adjustments or are tied to business logic, such as external databases, file storage information, etc. |
-## 安装
+## Installation
-内置插件,无需单独安装。
+Built-in plugin, no separate installation required.
-## 用途
+## Usage
-### 配置数据重用
+### Configuration Data Reuse
-例如工作流多个地方需要邮件节点,都需要配置 SMTP,就可以将通用的 SMTP 配置存到环境变量里。
+For example, if multiple places in the workflow require email nodes and SMTP configuration, the common SMTP configuration can be stored in environment variables.
-### 敏感数据存储
+### Sensitive Data Storage
-各种外部数据库的数据库配置信息、云文件存储密钥等数据的存储等。
+Storage of various external database configuration information, cloud file storage keys, etc.
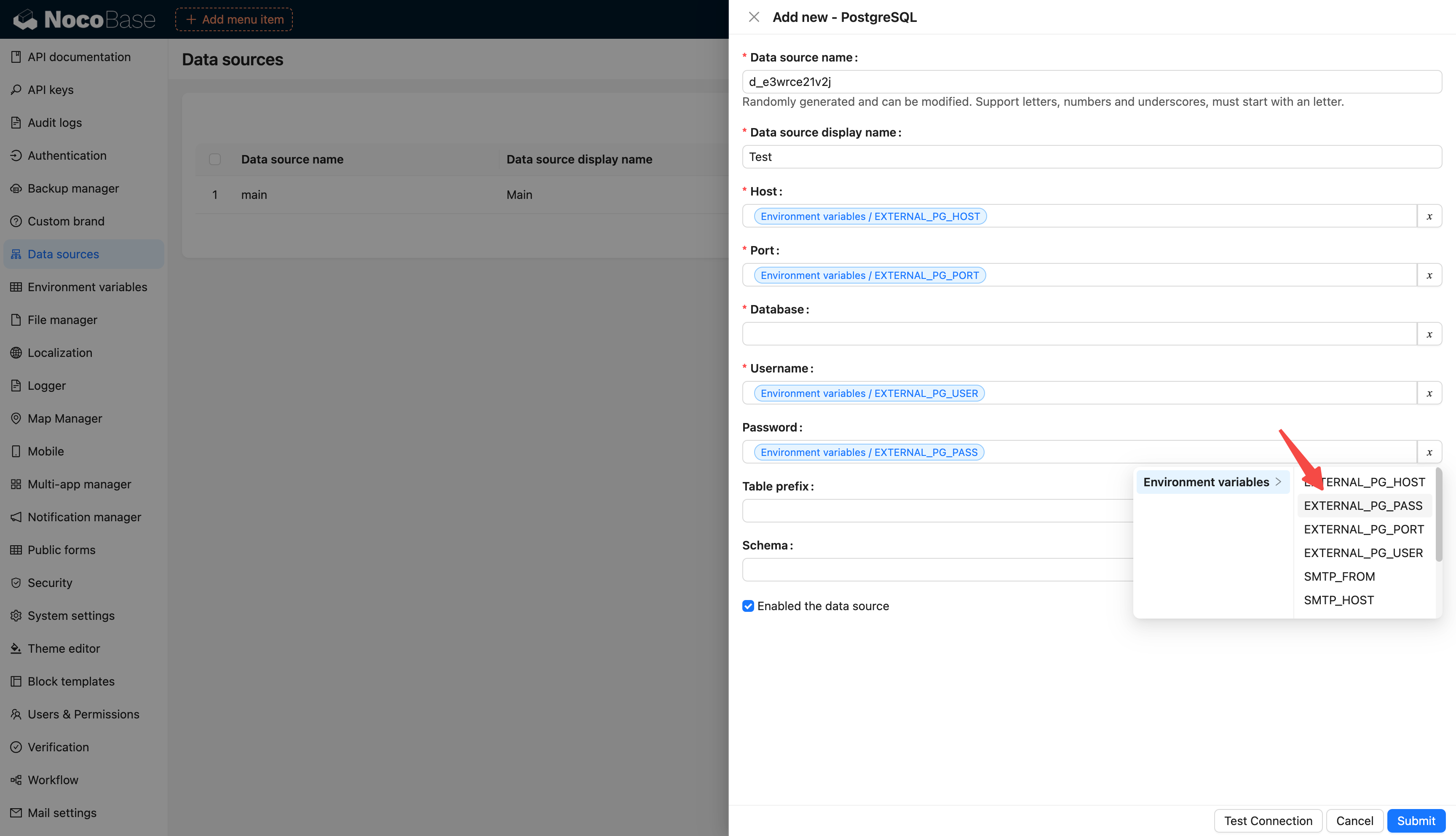
-### 环境配置隔离
+### Environment Configuration Isolation
-在软件开发、测试和生产等不同环境中,使用独立的配置管理策略来确保每个环境的配置和数据互不干扰。每个环境有各自独立的设置、变量和资源,这样可以避免开发、测试和生产环境之间的冲突,同时确保系统在每个环境中都能按预期运行。
+In different environments such as development, testing, and production, independent configuration management strategies are used to ensure that the configurations and data of each environment do not interfere with each other. Each environment has its own independent settings, variables, and resources, which avoids conflicts between development, testing, and production environments and ensures that the system runs as expected in each environment.
-例如,文件存储服务,开发环境和生产环境的配置可能不同,如下:
+For example, the configuration for file storage services may differ between development and production environments, as shown below:
-开发环境
+Development Environment
```bash
FILE_STORAGE_OSS_BASE_URL=dev-storage.nocobase.com
FILE_STORAGE_OSS_BUCKET=dev-storage
```
-生产环境
+Production Environment
```bash
FILE_STORAGE_OSS_BASE_URL=prod-storage.nocobase.com
FILE_STORAGE_OSS_BUCKET=prod-storage
```
-## 环境变量管理
+## Environment Variable Management
-### 添加环境变量
+### Adding Environment Variables
-- 支持单个和批量添加
-- 支持明文和加密
+- Supports single and batch addition
+- Supports plaintext and encrypted storage
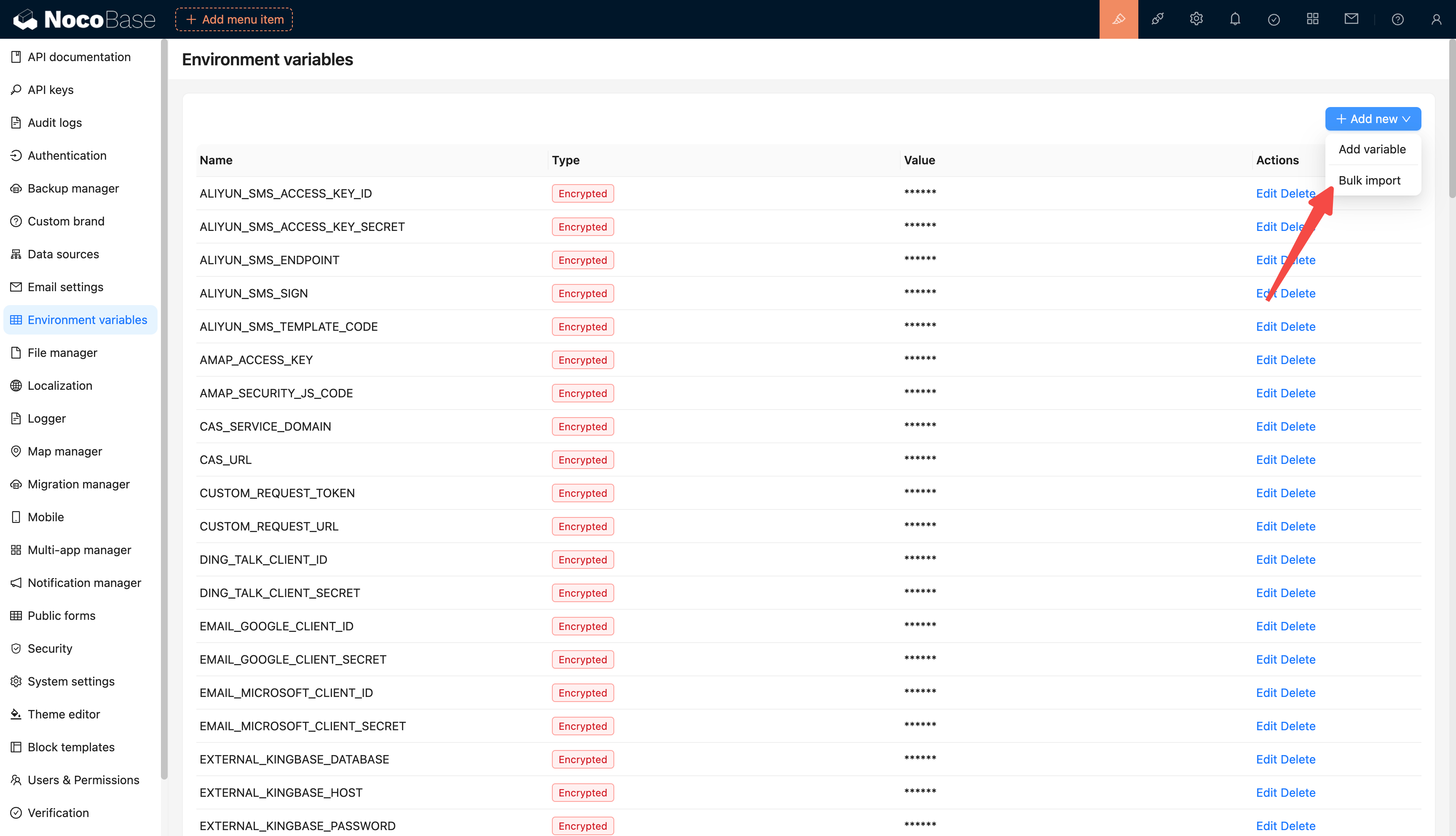
-单个添加
+Single Addition
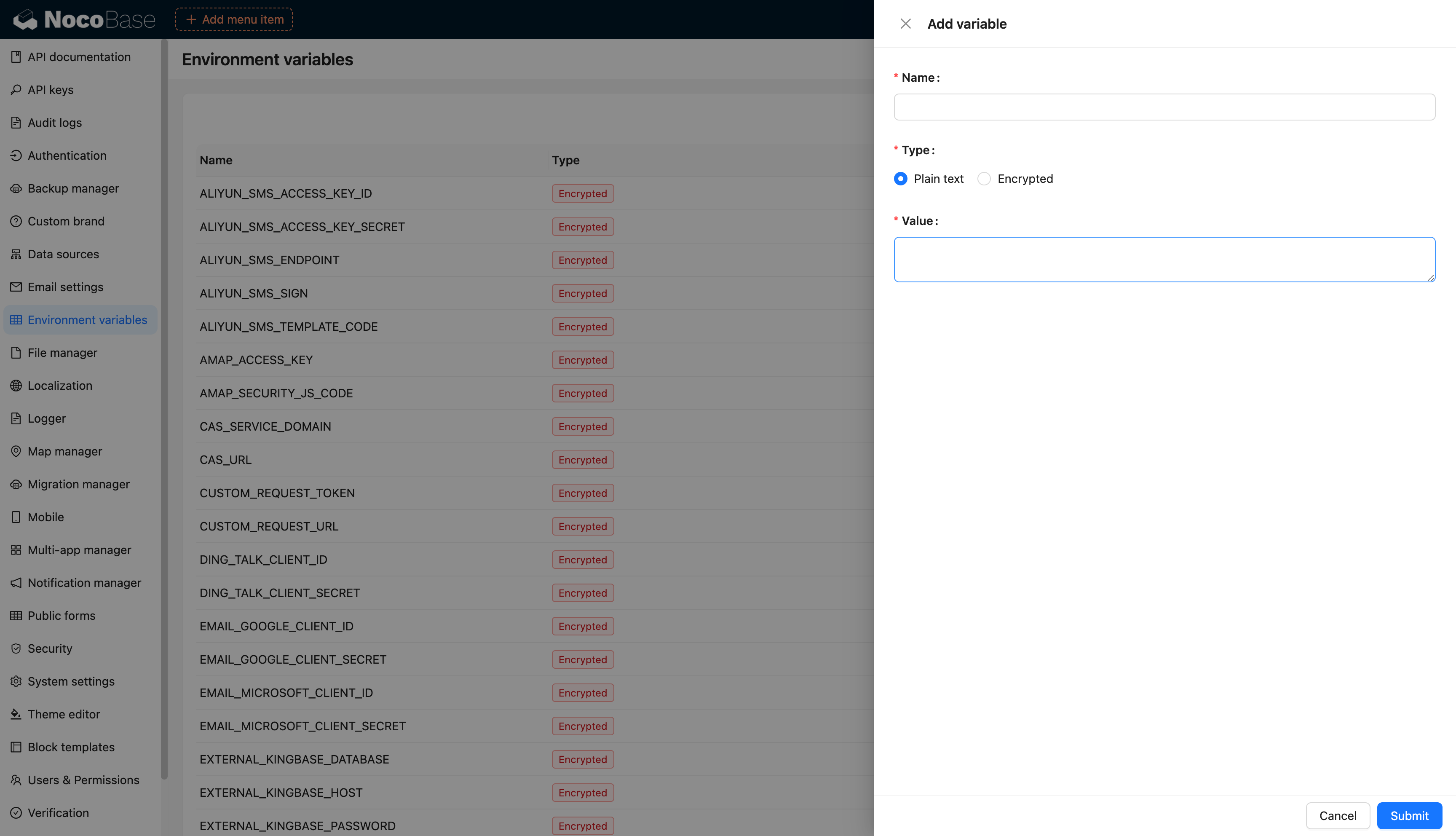
-批量添加
+Batch Addition
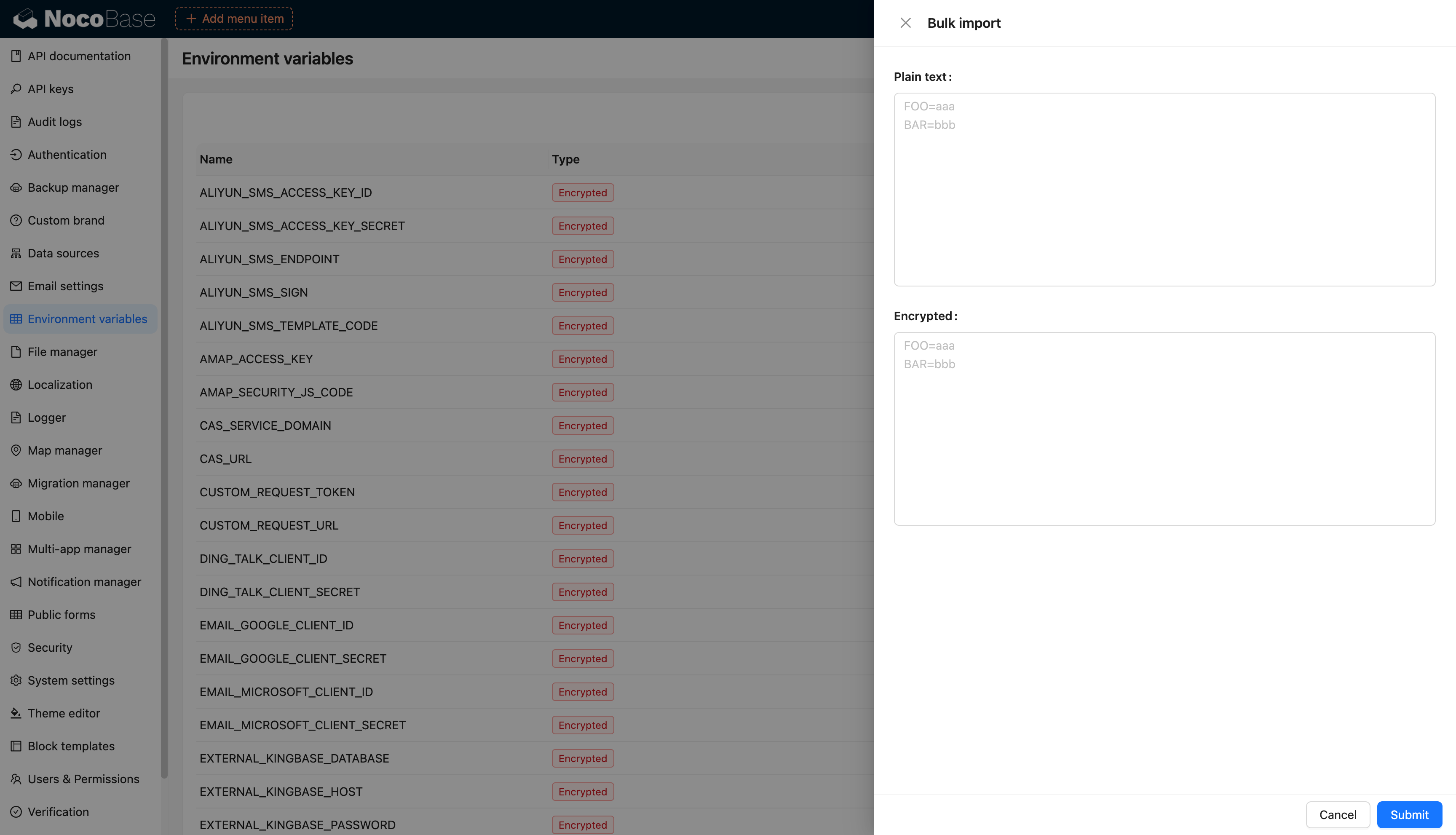
-## 注意事项
+## Notes
-### 重启应用
+### Restarting the Application
-修改或删除环境变量之后,顶部会出现重启应用的提示,重启之后变更的环境变量才会生效。
+After modifying or deleting environment variables, a prompt to restart the application will appear at the top. Changes to environment variables will only take effect after the application is restarted.
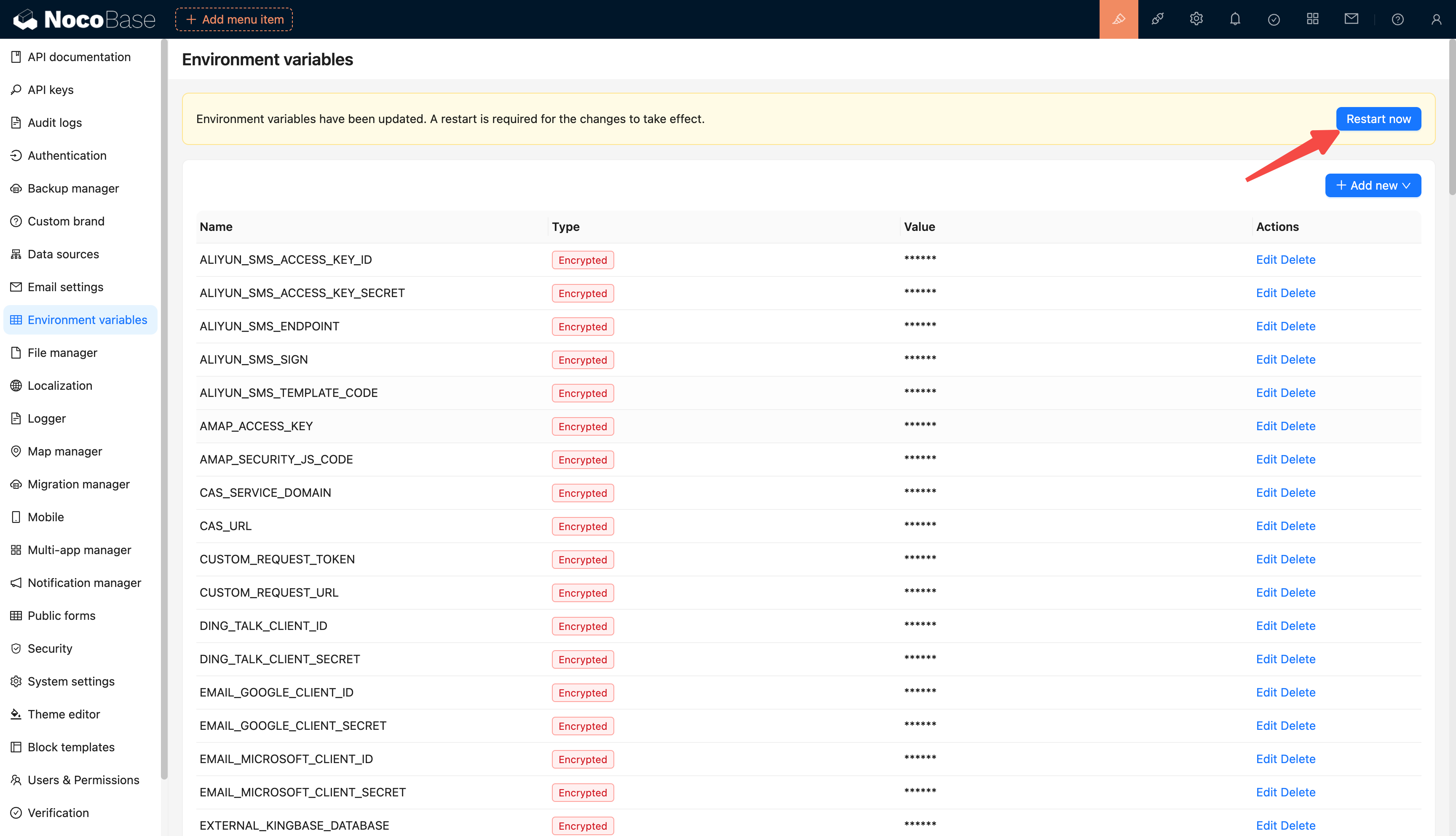
-### 加密存储
+### Encrypted Storage
-环境变量的加密数据使用 AES 对称加密,加解密的 PRIVATE KEY 存储在 storage 里,请妥善保管,丢失或重写,加密的数据将无法解密。
+Encrypted data for environment variables uses AES symmetric encryption. The PRIVATE KEY for encryption and decryption is stored in the storage directory. Please keep it safe; if lost or overwritten, the encrypted data cannot be decrypted.
```bash
./storage/environment-variables//aes_key.dat
```
-## 目前支持环境变量的插件
+## Currently Supported Plugins for Environment Variables
-### Action: Custom request
+### Action: Custom Request
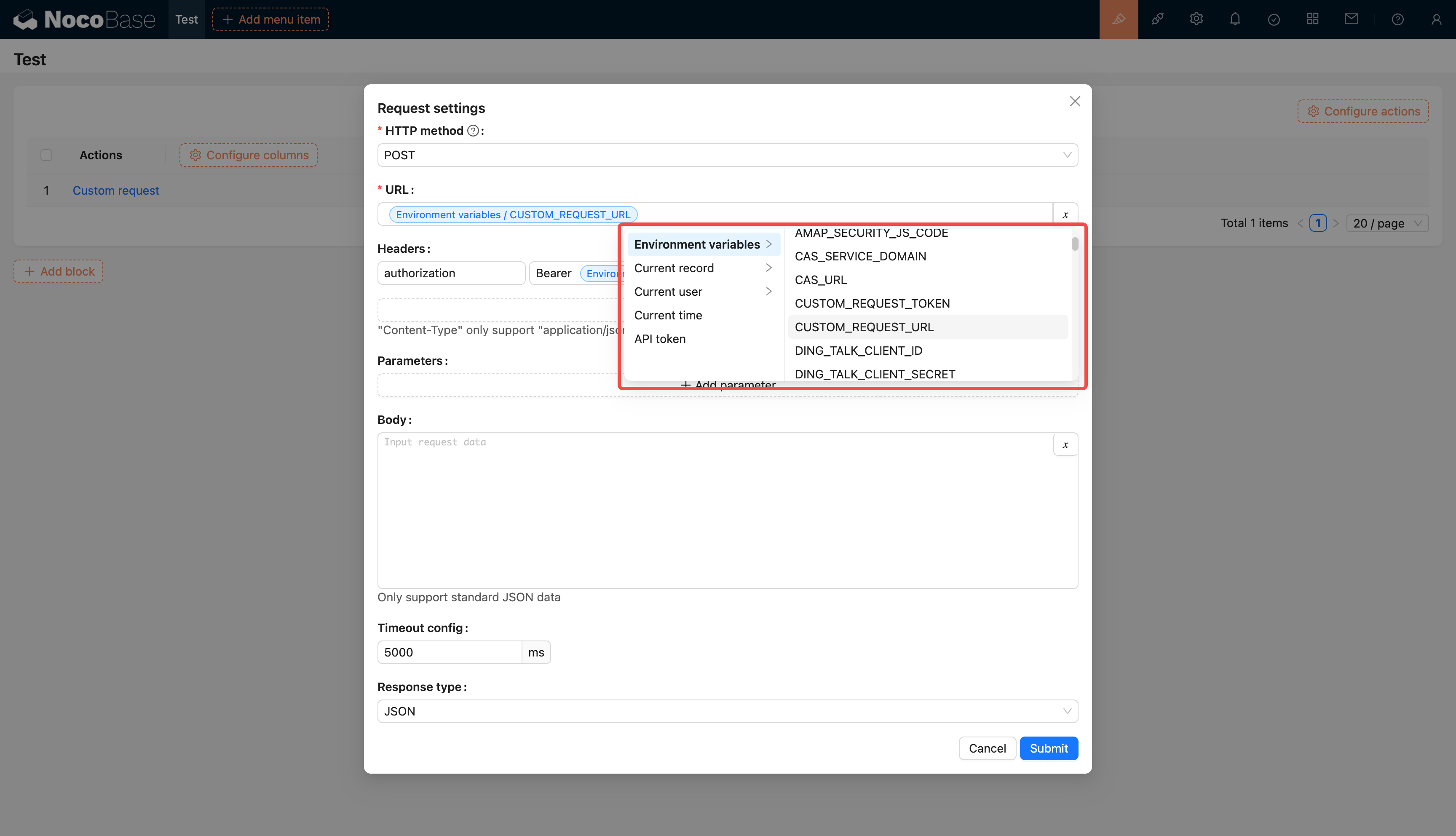
@@ -119,53 +119,53 @@ FILE_STORAGE_OSS_BUCKET=prod-storage
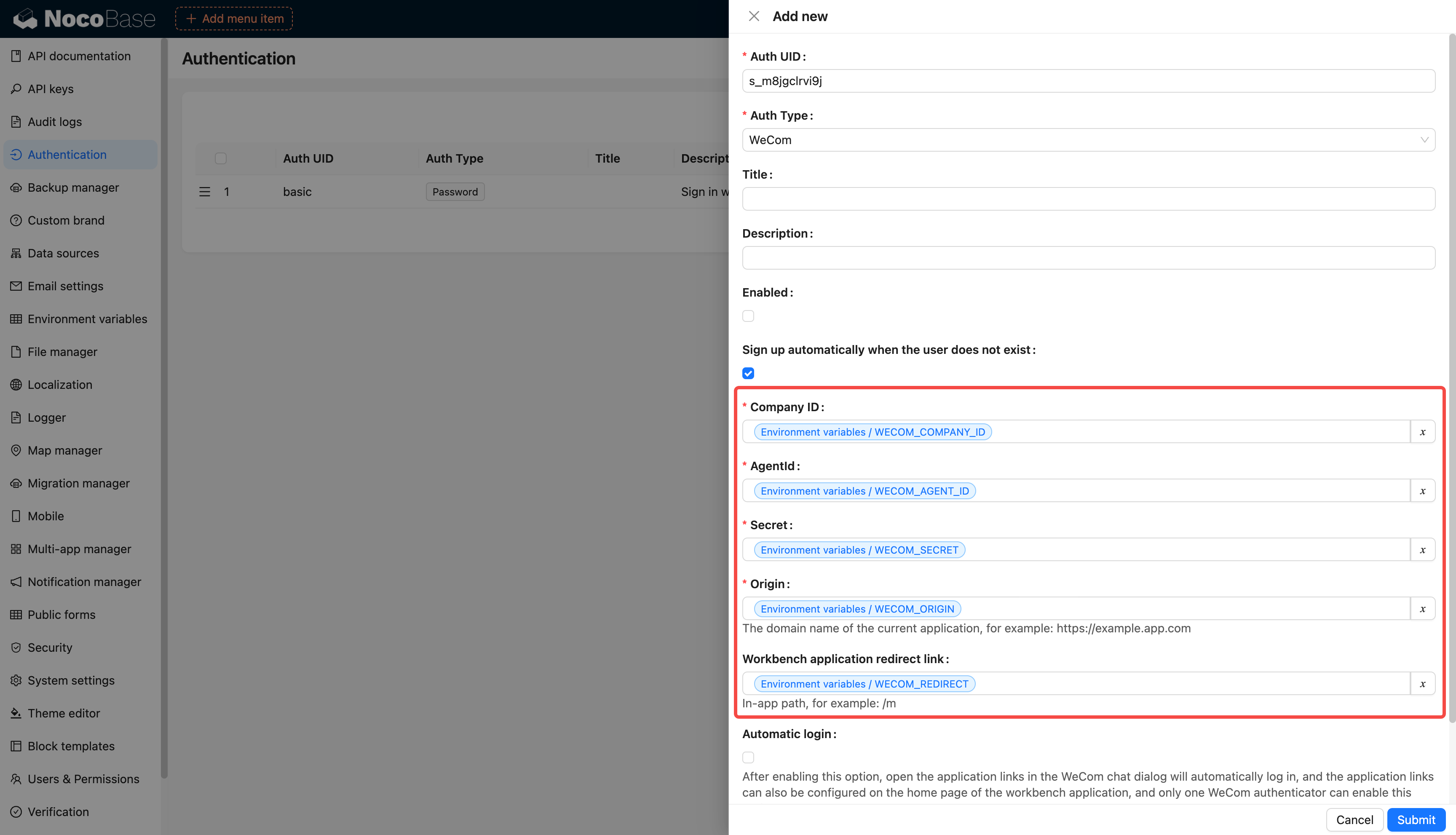
-### Data source: External MariaDB
+### Data Source: External MariaDB

-### Data source: External MySQL
+### Data Source: External MySQL

-### Data source: External Oracle
+### Data Source: External Oracle
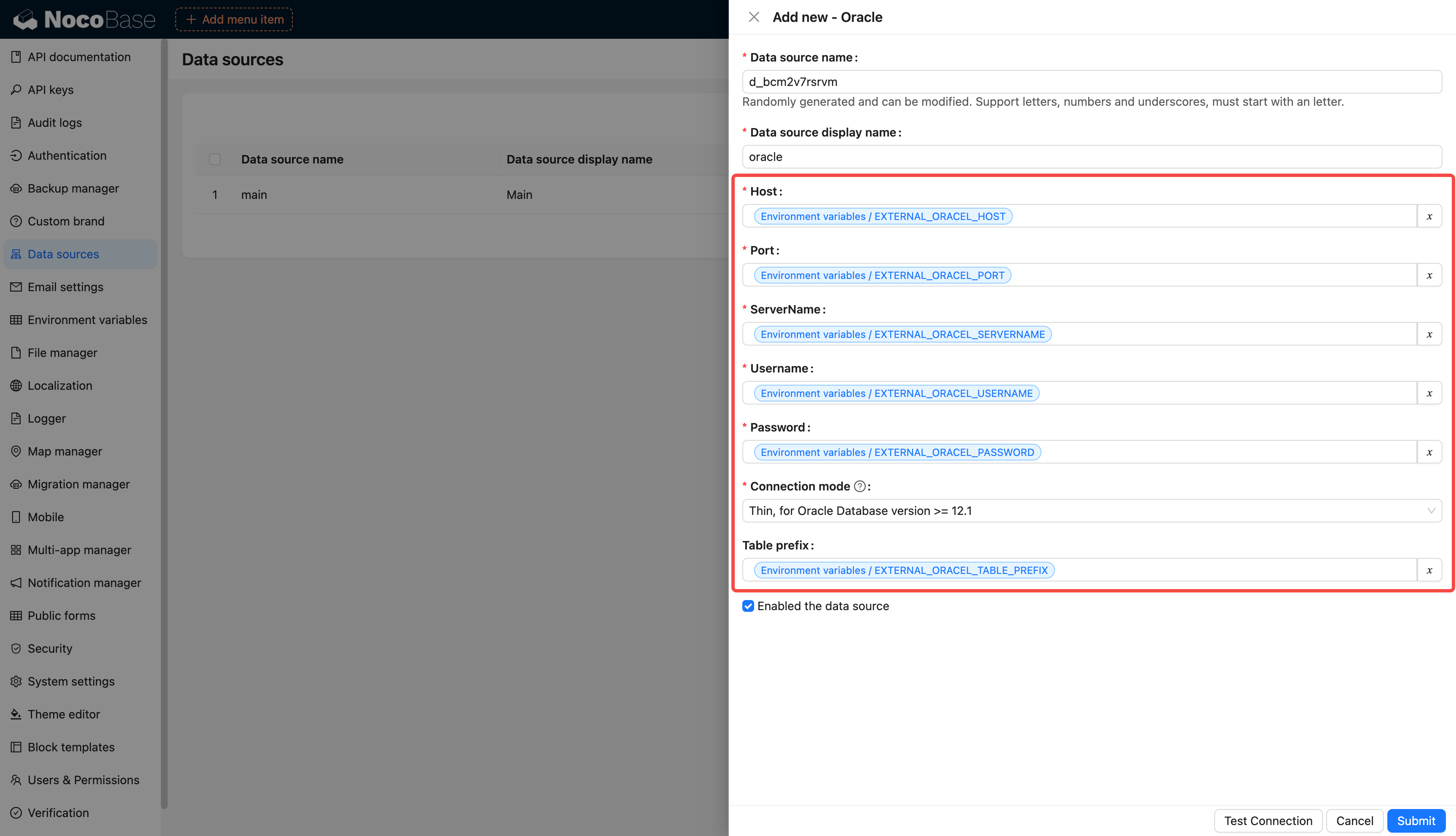
-### Data source: External PostgreSQL
+### Data Source: External PostgreSQL
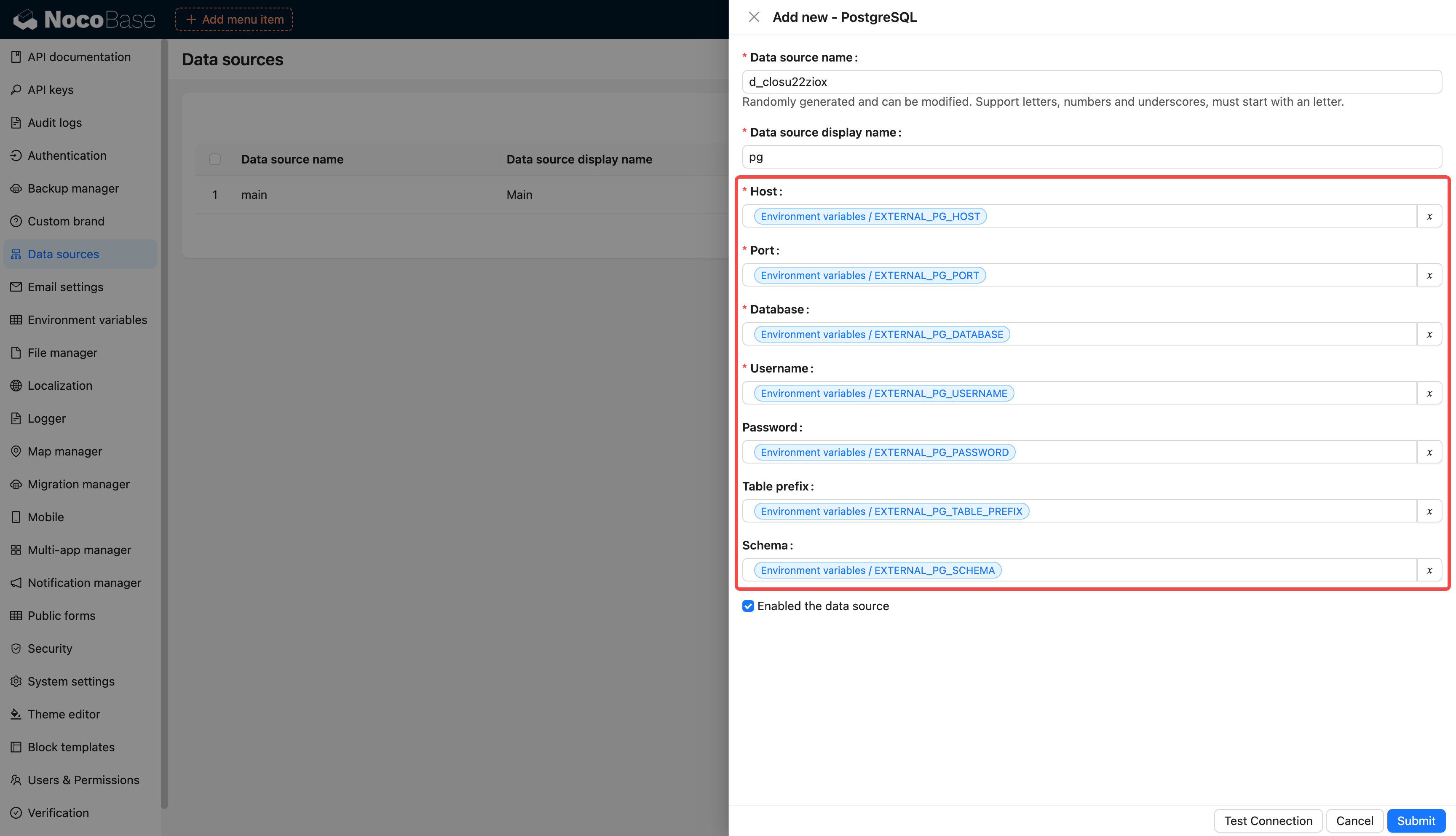
-### Data source: External SQL Server
+### Data Source: External SQL Server
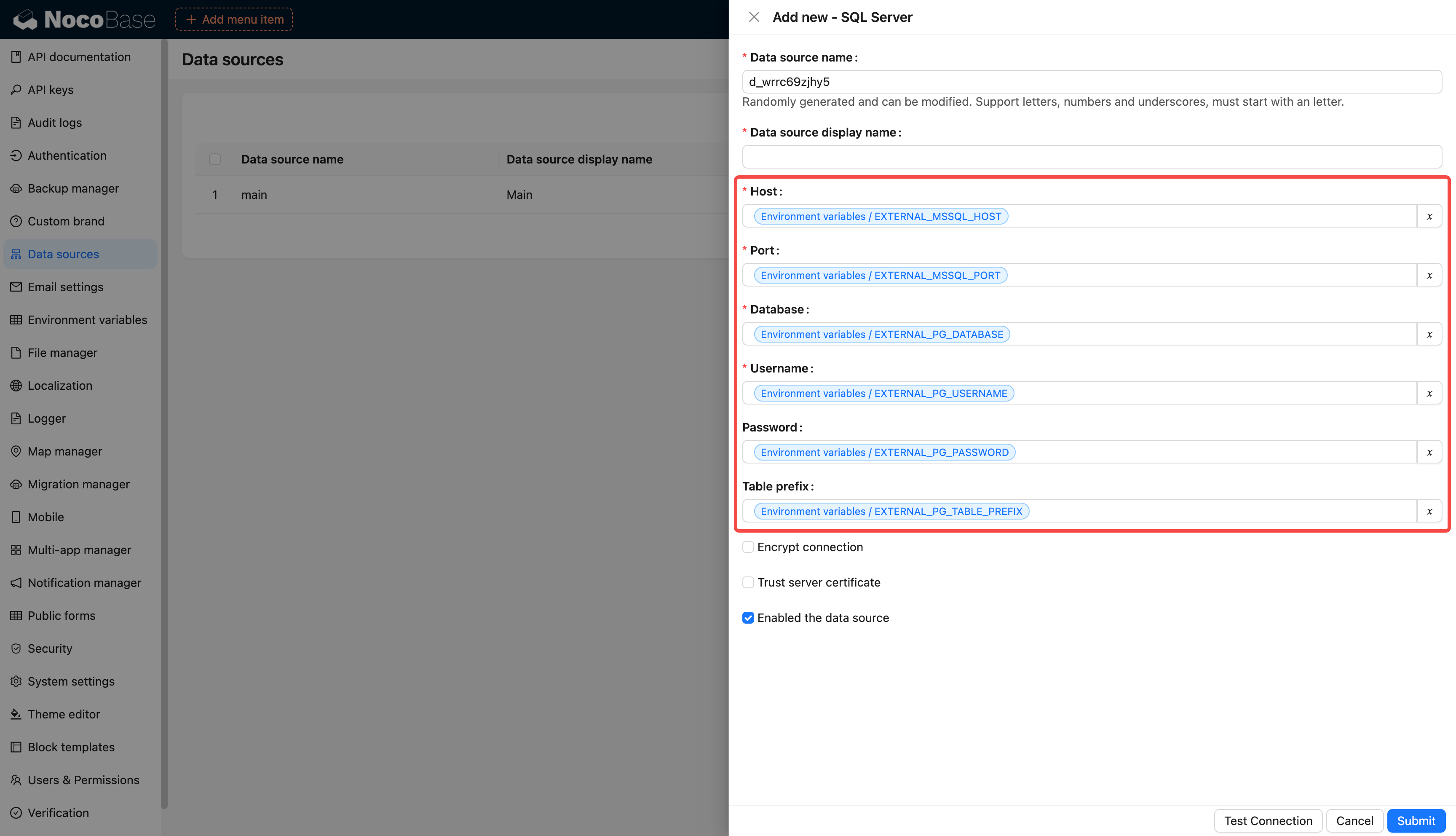
-### Data source: KingbaseES
+### Data Source: KingbaseES
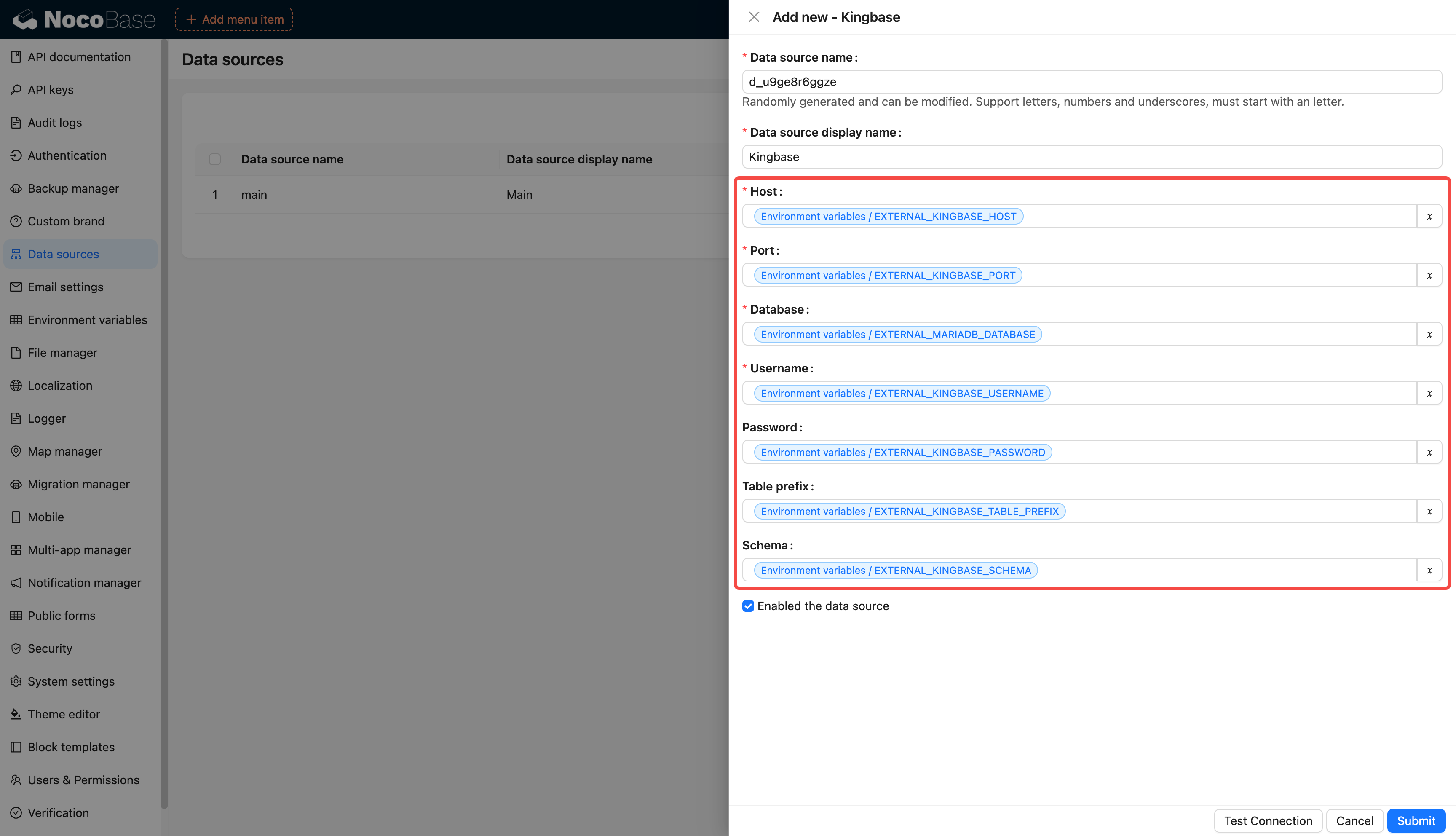
-### Data source: REST API
+### Data Source: REST API

-### File storage: Local
+### File Storage: Local

-### File storage: Aliyun OSS
+### File Storage: Aliyun OSS

-### File storage: Amazon S3
+### File Storage: Amazon S3

-### File storage: Tencent COS
+### File Storage: Tencent COS
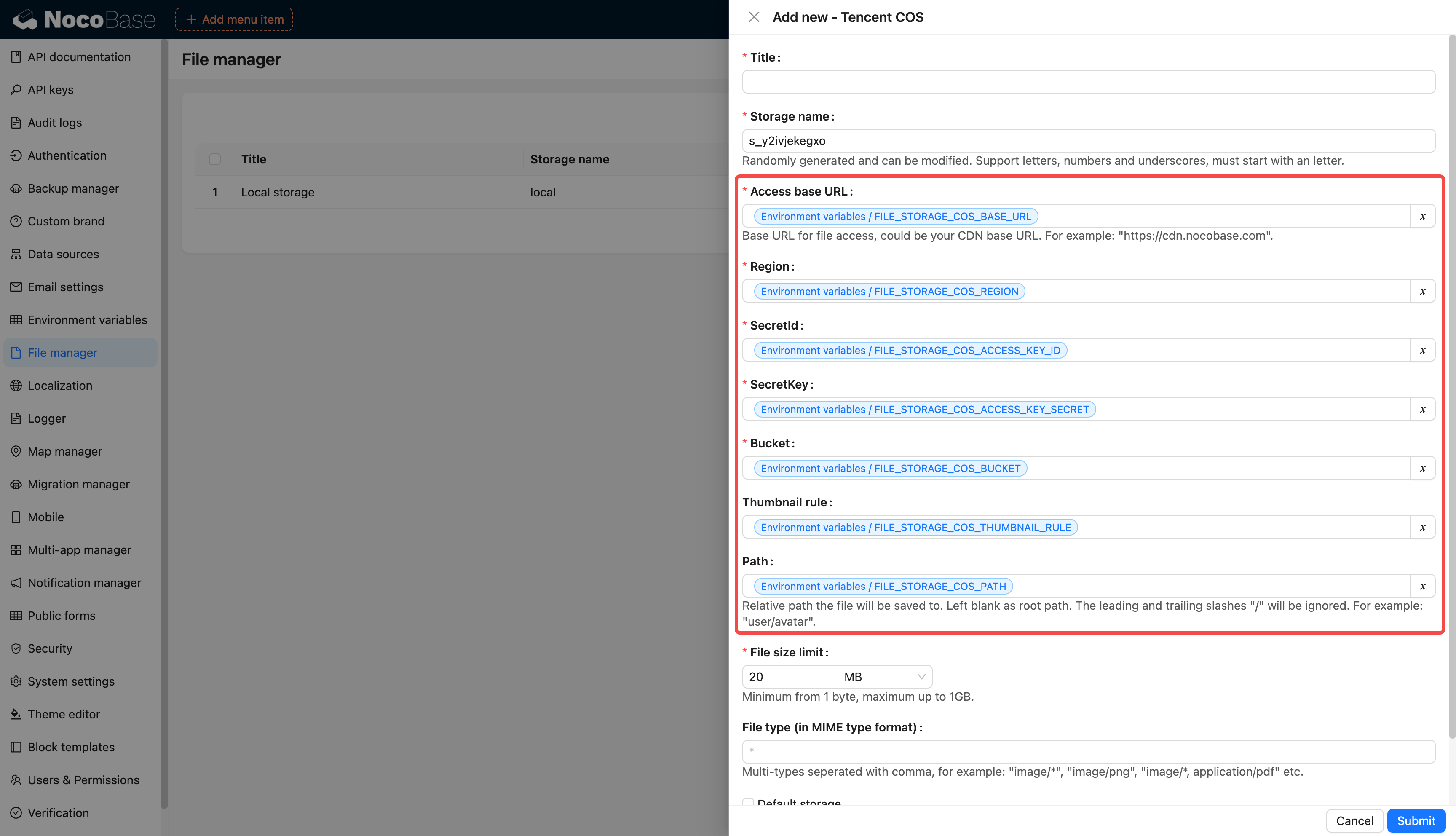
-### File storage: S3 Pro
+### File Storage: S3 Pro
-未适配
+Not adapted
### Map: AMap
@@ -175,19 +175,19 @@ FILE_STORAGE_OSS_BUCKET=prod-storage
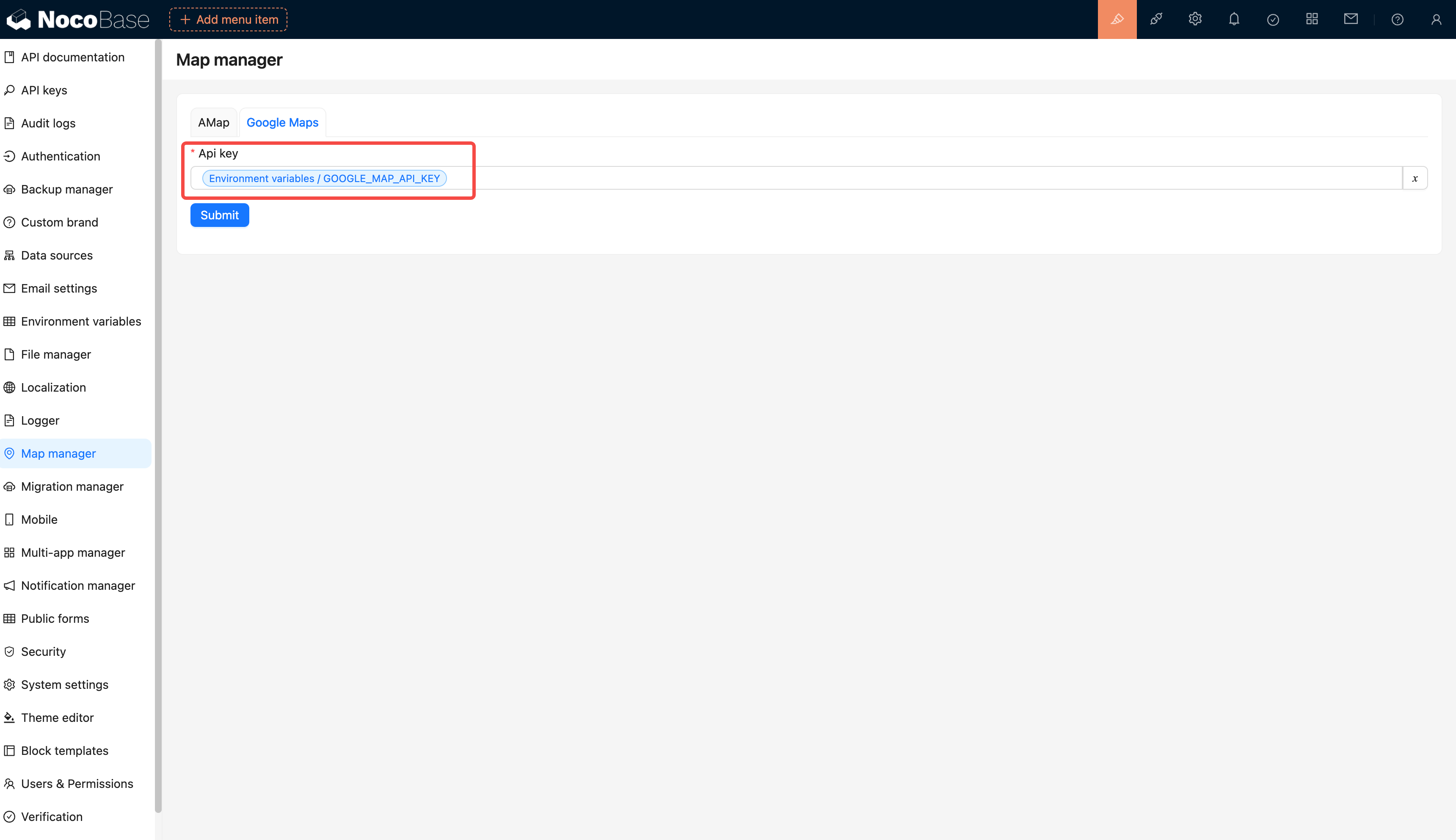
-### Email settings
+### Email Settings
-未适配
+Not adapted
### Notification: Email
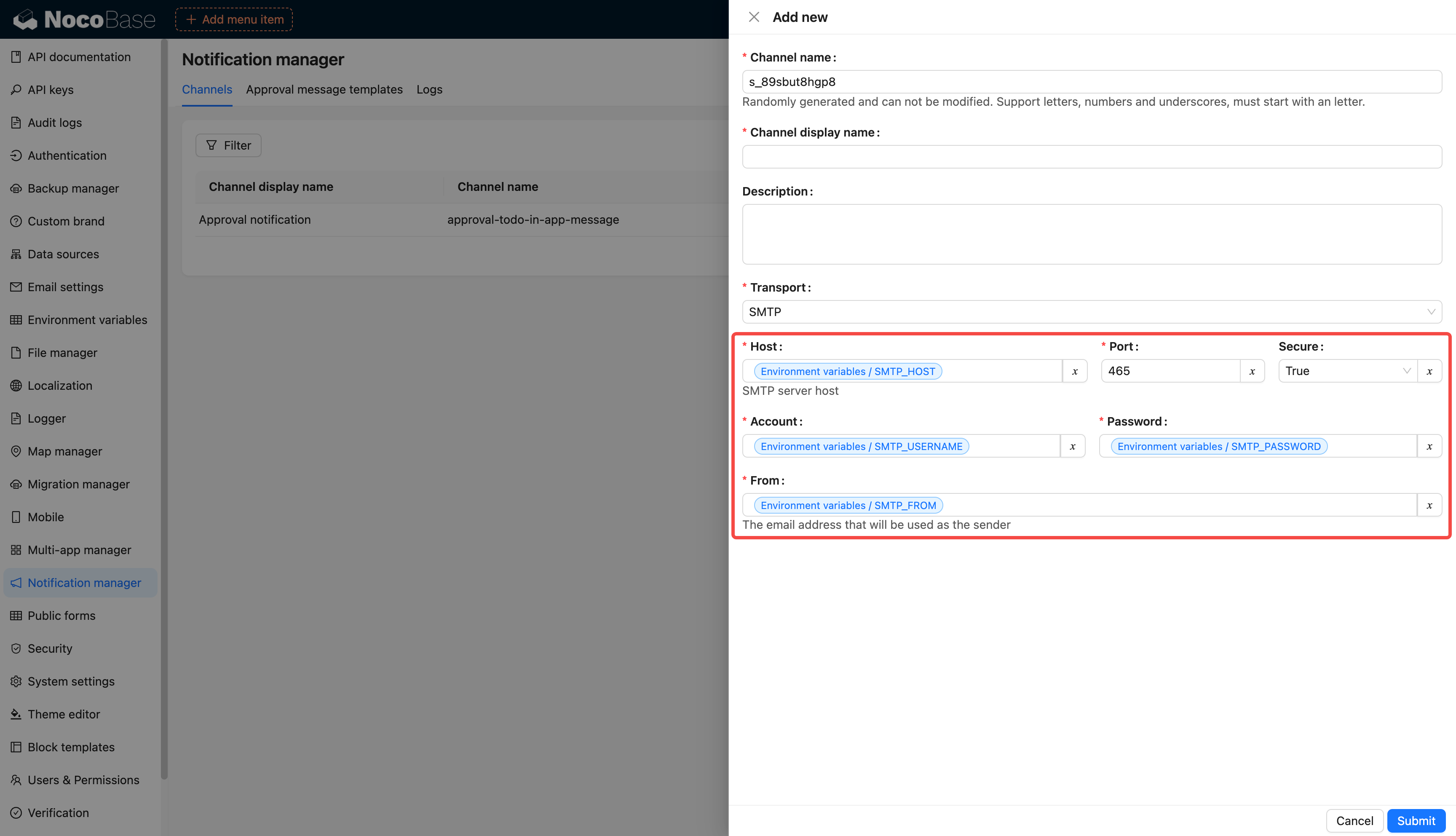
-### Public forms
+### Public Forms
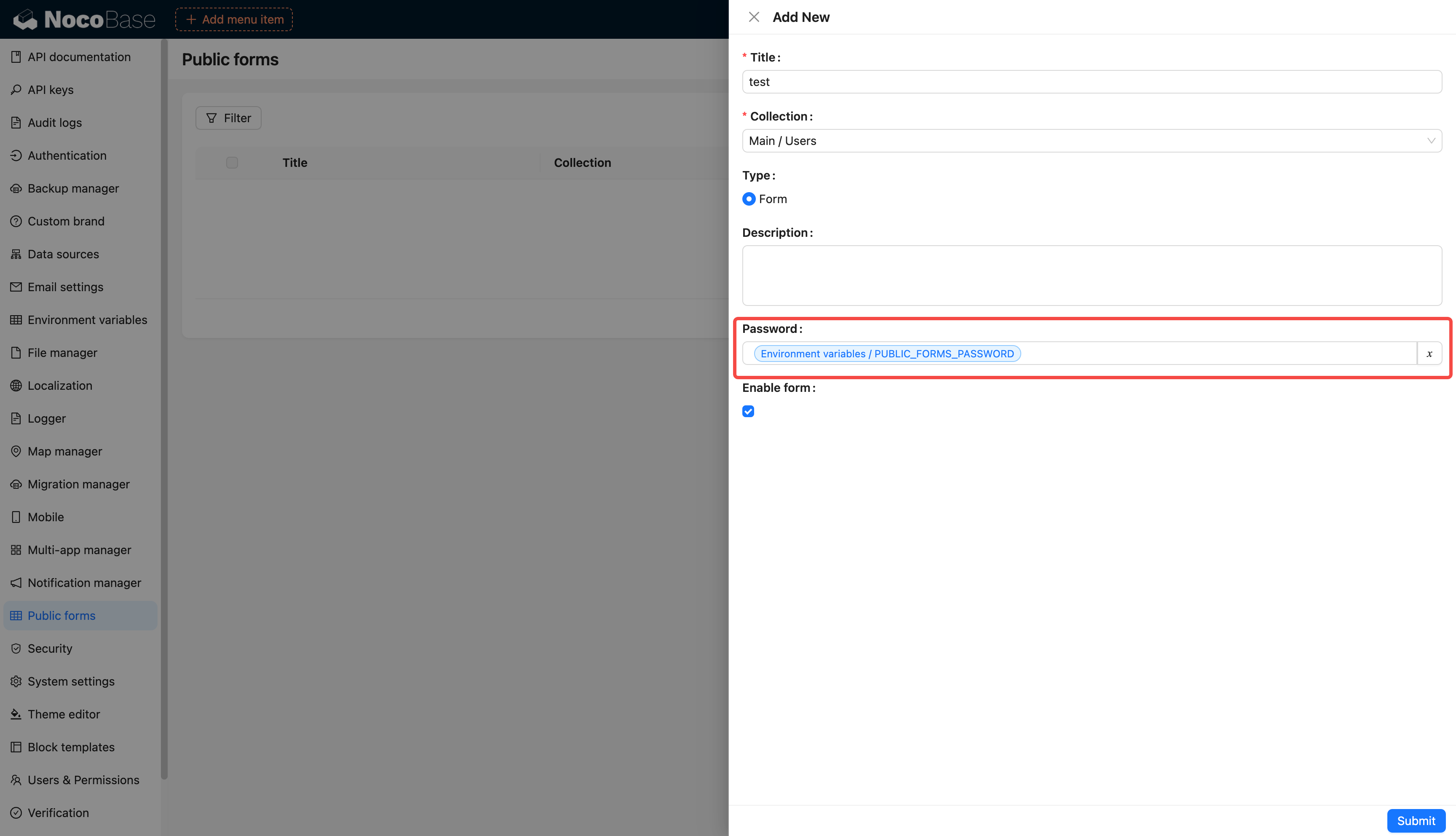
-### System settings
+### System Settings

diff --git a/docs/ja-JP/handbook/action-template-print/index.md b/docs/ja-JP/handbook/action-template-print/index.md
new file mode 100644
index 000000000..aa3eacd09
--- /dev/null
+++ b/docs/ja-JP/handbook/action-template-print/index.md
@@ -0,0 +1,2546 @@
+# Template Printing
+
+
+
+## Introduction
+
+The Template Printing plugin is a powerful tool that allows you to edit template files in Word, Excel, and PowerPoint (supporting `.docx`, `.xlsx`, `.pptx` formats), set placeholders and logical structures within the templates, and dynamically generate pre-formatted files such as `.docx`, `.xlsx`, `.pptx`, and PDF files. This plugin is widely used for generating various business documents, such as quotations, invoices, contracts, etc., significantly improving the efficiency and accuracy of document generation.
+
+### Key Features
+
+- **Multi-format Support**: Compatible with Word, Excel, and PowerPoint templates to meet different document generation needs.
+- **Dynamic Data Filling**: Automatically fills and generates document content through placeholders and logical structures.
+- **Flexible Template Management**: Supports adding, editing, deleting, and categorizing templates for easy maintenance and use.
+- **Rich Template Syntax**: Supports basic replacement, array access, loops, conditional output, and other template syntax to meet complex document generation needs.
+- **Formatter Support**: Provides conditional output, date formatting, number formatting, and other functions to enhance the readability and professionalism of documents.
+- **Efficient Output Formats**: Supports direct generation of PDF files for easy sharing and printing.
+
+## Configuration Instructions
+
+### Activating Template Printing
+
+1. **Open the Detail Block**:
+ - Navigate to the detail block in the application where you need to use the template printing feature.
+
+2. **Access the Configuration Operation Menu**:
+ - Click the "Configuration Operation" menu at the top of the interface.
+
+3. **Select "Template Printing"**:
+ - Click the "Template Printing" option in the dropdown menu to activate the plugin.
+
+ 
+
+### Configuring Templates
+
+1. **Access the Template Configuration Page**:
+ - In the configuration menu of the "Template Printing" button, select the "Template Configuration" option.
+
+ 
+
+2. **Add a New Template**:
+ - Click the "Add Template" button to enter the template addition page.
+
+ 
+
+3. **Fill in Template Information**:
+ - In the template form, fill in the template name and select the template type (Word, Excel, PowerPoint).
+ - Upload the corresponding template file (supports `.docx`, `.xlsx`, `.pptx` formats).
+
+ 
+
+4. **Edit and Save the Template**:
+ - Go to the "Field List" page, copy fields, and fill them into the template.
+ 
+ 
+ - After filling in the details, click the "Save" button to complete the template addition.
+
+5. **Template Management**:
+ - Click the "Use" button on the right side of the template list to activate the template.
+ - Click the "Edit" button to modify the template name or replace the template file.
+ - Click the "Download" button to download the configured template file.
+ - Click the "Delete" button to remove unnecessary templates. The system will prompt for confirmation to avoid accidental deletion.
+ 
+
+## Template Syntax
+
+The Template Printing plugin provides various syntaxes to flexibly insert dynamic data and logical structures into templates. Below are detailed syntax explanations and usage examples.
+
+### Basic Replacement
+
+Use placeholders in the format `{d.xxx}` for data replacement. For example:
+
+- `{d.title}`: Reads the `title` field from the dataset.
+- `{d.date}`: Reads the `date` field from the dataset.
+
+**Example**:
+
+Template Content:
+```
+Dear Customer,
+
+Thank you for purchasing our product: {d.productName}.
+Order ID: {d.orderId}
+Order Date: {d.orderDate}
+
+Wish you a pleasant experience!
+```
+
+Dataset:
+```json
+{
+ "productName": "Smart Watch",
+ "orderId": "A123456789",
+ "orderDate": "2025-01-01"
+}
+```
+
+Rendered Result:
+```
+Dear Customer,
+
+Thank you for purchasing our product: Smart Watch.
+Order ID: A123456789
+Order Date: 2025-01-01
+
+Wish you a pleasant experience!
+```
+
+### Accessing Sub-objects
+
+If the dataset contains sub-objects, you can access the properties of the sub-objects using dot notation.
+
+**Syntax**: `{d.parent.child}`
+
+**Example**:
+
+Dataset:
+```json
+{
+ "customer": {
+ "name": "Li Lei",
+ "contact": {
+ "email": "lilei@example.com",
+ "phone": "13800138000"
+ }
+ }
+}
+```
+
+Template Content:
+```
+Customer Name: {d.customer.name}
+Email Address: {d.customer.contact.email}
+Phone Number: {d.customer.contact.phone}
+```
+
+Rendered Result:
+```
+Customer Name: Li Lei
+Email Address: lilei@example.com
+Phone Number: 13800138000
+```
+
+### Accessing Arrays
+
+If the dataset contains arrays, you can use the reserved keyword `i` to access elements in the array.
+
+**Syntax**: `{d.arrayName[i].field}`
+
+**Example**:
+
+Dataset:
+```json
+{
+ "staffs": [
+ { "firstname": "James", "lastname": "Anderson" },
+ { "firstname": "Emily", "lastname": "Roberts" },
+ { "firstname": "Michael", "lastname": "Johnson" }
+ ]
+}
+```
+
+Template Content:
+```
+The first employee's last name is {d.staffs[i=0].lastname}, and the first name is {d.staffs[i=0].firstname}
+```
+
+Rendered Result:
+```
+The first employee's last name is Anderson, and the first name is James
+```
+
+### Loop Output
+
+The Template Printing plugin supports looping through arrays to output data. There is no need to explicitly mark the start and end of the loop; simply use the reserved keywords `i` and `i+1` in the template. The plugin will automatically recognize and process the loop section.
+
+#### Simple Array Loop
+
+**Example**: Generating a table of company employee data
+
+**Dataset**:
+```json
+{
+ "staffs": [
+ { "firstname": "James", "lastname": "Anderson" },
+ { "firstname": "Emily", "lastname": "Roberts" },
+ { "firstname": "Michael", "lastname": "Johnson" }
+ ]
+}
+```
+
+**Template**:
+
+| First Name | Last Name |
+|---|---|
+| {d.staffs[i].firstname} | {d.staffs[i].lastname} |
+| {d.staffs[i+1]} | |
+
+**Rendered Result**:
+
+| First Name | Last Name |
+|---|---|
+| James | Anderson |
+| Emily | Roberts |
+| Michael | Johnson |
+
+**Explanation**: The template uses `{d.staffs[i].firstname}` and `{d.staffs[i].lastname}` to loop through and fill in the first and last names of each employee. `{d.staffs[i+1]}` marks the start of the next row in the loop.
+
+#### Nested Array Loop
+
+The Template Printing plugin supports processing nested arrays, allowing for infinite levels of nested loops, suitable for displaying complex data structures.
+
+**Example**: Displaying car brands and their models
+
+**Dataset**:
+```json
+{
+ "cars": [
+ {
+ "brand": "Toyota",
+ "models": [{ "size": "Prius 2" }, { "size": "Prius 3" }]
+ },
+ {
+ "brand": "Tesla",
+ "models": [{ "size": "S" }, { "size": "X" }]
+ }
+ ]
+}
+```
+
+**Template**:
+
+```
+Brand: {d.cars[i].brand}
+Models:
+{d.cars[i].models[j].size}
+{d.cars[i].models[j+1].size}
+
+---
+```
+
+
+**Rendered Result**:
+```
+Brand: Toyota
+Models:
+Prius 2
+Prius 3
+
+---
+Brand: Tesla
+Models:
+S
+X
+
+---
+```
+
+**Explanation**: The outer loop uses `i` to iterate through each brand, while the inner loop uses `j` to iterate through each model under the brand. `{d.cars[i].models[j].size}` and `{d.cars[i].models[j+1].size}` are used to fill in the current and next models, respectively. This allows for infinite levels of nested loops to accommodate complex data structures.
+
+### Sorting Function
+
+The Template Printing plugin allows sorting arrays based on object properties, not limited to using the iterator `i`. Currently, it supports ascending order by a specified property but does not support descending order.
+
+**Example**: Sorting cars by "power" in ascending order
+
+**Dataset**:
+```json
+{
+ "cars" : [
+ { "brand" : "Lumeneo" , "power" : 3 },
+ { "brand" : "Tesla" , "power" : 1 },
+ { "brand" : "Toyota" , "power" : 2 }
+ ]
+}
+```
+
+**Template**:
+```
+{d.cars:sort(power)}
+Brand: {d.cars[i].brand}
+Power: {d.cars[i].power} kW
+
+---
+```
+
+**Rendered Result**:
+```
+Brand: Tesla
+Power: 1 kW
+
+---
+Brand: Toyota
+Power: 2 kW
+
+---
+Brand: Lumeneo
+Power: 3 kW
+
+---
+```
+
+**Explanation**: The `:sort(power)` function sorts the `cars` array by the `power` property in ascending order, and then renders each car's brand and power.
+
+## Formatters
+
+Formatters are used to convert data into specific formats or perform conditional checks, enhancing the flexibility and expressiveness of templates.
+
+### Conditional Output
+
+Control the display and hiding of specific content using `showBegin` and `showEnd`.
+
+**Syntax**:
+```
+{d.field:condition:showBegin}
+Content
+{d.field:showEnd}
+```
+
+**Example**: Displaying special terms in a contract template based on customer type
+
+**Dataset**:
+```json
+{
+ "customerType": "VIP"
+}
+```
+
+**Template Content**:
+```
+{d.customerType:ifEQ('VIP'):showBegin}
+Special Terms:
+As our VIP customer, you will enjoy additional benefits and exclusive services, including free upgrades, priority support, etc.
+{d.customerType:showEnd}
+```
+
+**Rendered Result** (when `customerType` is "VIP"):
+```
+Special Terms:
+As our VIP customer, you will enjoy additional benefits and exclusive services, including free upgrades, priority support, etc.
+```
+
+**Explanation**: When the value of the `customerType` field is "VIP", the content between `showBegin` and `showEnd` will be rendered; otherwise, it will be hidden.
+
+### Date Formatting
+
+Use formatters to convert date fields into more readable formats.
+
+**Syntax**:
+```
+{d.dateField:format(YYYY年MM月DD日)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "orderDate": "2025-01-03T10:30:00Z"
+}
+```
+
+**Template Content**:
+```
+Order Date: {d.orderDate:format(YYYY年MM月DD日)}
+```
+
+**Rendered Result**:
+```
+Order Date: 2025年01月03日
+```
+
+**Explanation**: The `format` formatter converts the ISO-formatted date into a more readable format.
+
+### Number Formatting
+
+Use formatters to format numbers, such as adding thousand separators or controlling decimal places.
+
+**Syntax**:
+```
+{d.numberField:format(0,0.00)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "totalAmount": 1234567.89
+}
+```
+
+**Template Content**:
+```
+Total Amount: {d.totalAmount:format('0,0.00')} yuan
+```
+
+**Rendered Result**:
+```
+Total Amount: 1,234,567.89 yuan
+```
+
+**Explanation**: The `format` formatter adds thousand separators and retains two decimal places for the number.
+
+## String Formatter Examples
+
+### 1. lowerCase( )
+
+**Syntax**:
+```
+{d.someField:lowerCase()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "title": "My Car"
+}
+```
+
+**Template Content**:
+```
+Vehicle Name: {d.title:lowerCase()}
+```
+
+**Rendered Result**:
+```
+Vehicle Name: my car
+```
+
+**Explanation**: Converts all English letters to lowercase. If the value is not a string (e.g., a number, null, etc.), it is output as is.
+
+---
+
+### 2. upperCase( )
+
+**Syntax**:
+```
+{d.someField:upperCase()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "title": "my car"
+}
+```
+
+**Template Content**:
+```
+Vehicle Name: {d.title:upperCase()}
+```
+
+**Rendered Result**:
+```
+Vehicle Name: MY CAR
+```
+
+**Explanation**: Converts all English letters to uppercase. If the value is not a string, it is output as is.
+
+---
+
+### 3. ucFirst( )
+
+**Syntax**:
+```
+{d.someField:ucFirst()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "note": "hello world"
+}
+```
+
+**Template Content**:
+```
+Note: {d.note:ucFirst()}
+```
+
+**Rendered Result**:
+```
+Note: Hello world
+```
+
+**Explanation**: Converts only the first letter to uppercase, leaving the rest of the letters unchanged. If the value is null or undefined, it returns null or undefined.
+
+---
+
+### 4. ucWords( )
+
+**Syntax**:
+```
+{d.someField:ucWords()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "description": "my cAR"
+}
+```
+
+**Template Content**:
+```
+Description: {d.description:ucWords()}
+```
+
+**Rendered Result**:
+```
+Description: My CAR
+```
+
+**Explanation**: Converts the first letter of each word in the string to uppercase. The rest of the letters remain unchanged.
+
+---
+
+### 5. print( message )
+
+**Syntax**:
+```
+{d.someField:print('Fixed Output')}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "unusedField": "whatever"
+}
+```
+
+**Template Content**:
+```
+Prompt: {d.unusedField:print('This will always display a fixed prompt')}
+```
+
+**Rendered Result**:
+```
+Prompt: This will always display a fixed prompt
+```
+
+**Explanation**: Regardless of the original data, the specified `message` string will be output, effectively "forcing" the output.
+
+---
+
+### 6. printJSON( )
+
+**Syntax**:
+```
+{d.someField:printJSON()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "items": [
+ { "id": 2, "name": "homer" },
+ { "id": 3, "name": "bart" }
+ ]
+}
+```
+
+**Template Content**:
+```
+Raw Data: {d.items:printJSON()}
+```
+
+**Rendered Result**:
+```
+Raw Data: [{"id":2,"name":"homer"},{"id":3,"name":"bart"}]
+```
+
+**Explanation**: Serializes an object or array into a JSON-formatted string for direct output in the template.
+
+---
+
+### 7. convEnum( type )
+
+**Syntax**:
+```
+{d.someField:convEnum('ENUM_NAME')}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "orderStatus": 1
+}
+```
+Assume the following configuration in `carbone.render(data, options)`'s `options.enum`:
+```json
+{
+ "enum": {
+ "ORDER_STATUS": [
+ "pending", // 0
+ "sent", // 1
+ "delivered" // 2
+ ]
+ }
+}
+```
+
+**Template Content**:
+```
+Order Status: {d.orderStatus:convEnum('ORDER_STATUS')}
+```
+
+**Rendered Result**:
+```
+Order Status: sent
+```
+
+**Explanation**: Converts a number or defined enum value into readable text; if the value is not defined in the enum, it is output as is.
+
+---
+
+### 8. unaccent( )
+
+**Syntax**:
+```
+{d.someField:unaccent()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "food": "crème brûlée"
+}
+```
+
+**Template Content**:
+```
+Food Name: {d.food:unaccent()}
+```
+
+**Rendered Result**:
+```
+Food Name: creme brulee
+```
+
+**Explanation**: Removes accent marks, commonly used for processing text with special characters in French, Spanish, etc.
+
+---
+
+### 9. convCRLF( )
+
+**Syntax**:
+```
+{d.someField:convCRLF()}
+```
+> **Note**: Applicable to DOCX, PDF, ODT, ODS (ODS functionality is experimental).
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "content": "Multi-line text:\nFirst line\nSecond line\r\nThird line"
+}
+```
+
+**Template Content**:
+```
+Converted Content:
+{d.content:convCRLF()}
+```
+**Rendering Result** (DOCX Scenario):
+```
+Converted Content:
+Multi-line Text:
+First Line
+Second Line
+Third Line
+```
+> The actual XML will insert line break tags such as ``.
+
+**Note**: Convert `\n` or `\r\n` to the correct line break tags in the document to accurately display multi-line text in the final file.
+
+---
+
+### 10. substr( begin, end, wordMode )
+
+**Syntax**:
+```
+{d.someField:substr(begin, end, wordMode)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "text": "abcdefg hijklmnop"
+}
+```
+
+**Template Content**:
+```
+Substring (from index 0 to 5): {d.text:substr(0, 5)}
+Substring (from index 6 to end): {d.text:substr(6)}
+```
+
+**Rendering Result**:
+```
+Substring (from index 0 to 5): abcde
+Substring (from index 6 to end): fg hijklmnop
+```
+
+**Note**:
+- `begin` is the starting index, `end` is the ending index (exclusive).
+- If `wordMode=true`, it tries not to split words; if `wordMode='last'`, it extracts from `begin` to the end of the string.
+
+---
+
+### 11. split( delimiter )
+
+**Syntax**:
+```
+{d.someField:split(delimiter)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "path": "ab/cd/ef"
+}
+```
+
+**Template Content**:
+```
+Split Array: {d.path:split('/')}
+```
+
+**Rendering Result**:
+```
+Split Array: ["ab","cd","ef"]
+```
+
+**Note**: Use the specified `delimiter` to split the string into an array. Can be used with other array operations such as `arrayJoin`, index access, etc.
+
+---
+
+### 12. padl( targetLength, padString )
+
+**Syntax**:
+```
+{d.someField:padl(targetLength, padString)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "code": "abc"
+}
+```
+
+**Template Content**:
+```
+Left Padding (length 8, character '0'): {d.code:padl(8, '0')}
+```
+
+**Rendering Result**:
+```
+Left Padding (length 8, character '0'): 00000abc
+```
+
+**Note**: If `targetLength` is less than the original string length, the original string is returned; the default padding character is a space.
+
+---
+
+### 13. padr( targetLength, padString )
+
+**Syntax**:
+```
+{d.someField:padr(targetLength, padString)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "code": "abc"
+}
+```
+
+**Template Content**:
+```
+Right Padding (length 10, character '#'): {d.code:padr(10, '#')}
+```
+
+**Rendering Result**:
+```
+Right Padding (length 10, character '#'): abc#######
+```
+
+**Note**: Opposite of `padl`, padding is done at the end of the string. The default padding character is a space.
+
+---
+
+### 14. ellipsis( maximum )
+
+**Syntax**:
+```
+{d.someField:ellipsis(maximum)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "articleTitle": "Carbone Report Extended Version"
+}
+```
+
+**Template Content**:
+```
+Article Title (max 5 characters): {d.articleTitle:ellipsis(5)}
+```
+
+**Rendering Result**:
+```
+Article Title (max 5 characters): Carbo...
+```
+
+**Note**: When the string length exceeds `maximum`, it truncates and adds `...`.
+
+---
+
+### 15. prepend( textToPrepend )
+
+**Syntax**:
+```
+{d.someField:prepend(textToPrepend)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "username": "john"
+}
+```
+
+**Template Content**:
+```
+Username: {d.username:prepend('Mr. ')}
+```
+
+**Rendering Result**:
+```
+Username: Mr. john
+```
+
+**Note**: Appends specified text before the original string, commonly used for prefixes.
+
+---
+
+### 16. append( textToAppend )
+
+**Syntax**:
+```
+{d.someField:append(textToAppend)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "filename": "document"
+}
+```
+
+**Template Content**:
+```
+Filename: {d.filename:append('.pdf')}
+```
+
+**Rendering Result**:
+```
+Filename: document.pdf
+```
+
+**Note**: Appends specified text after the original string, commonly used for suffixes.
+
+---
+
+### 17. replace( oldText, newText )
+
+**Syntax**:
+```
+{d.someField:replace(oldText, newText)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "sentence": "abcdef abcde"
+}
+```
+
+**Template Content**:
+```
+Replacement Result: {d.sentence:replace('cd', 'OK')}
+```
+
+**Rendering Result**:
+```
+Replacement Result: abOKef abOKe
+```
+
+**Note**: Replaces all occurrences of `oldText` with `newText`; if `newText` is not specified or is `null`, the matched parts are deleted.
+
+---
+
+### 18. len( )
+
+**Syntax**:
+```
+{d.someField:len()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "greeting": "Hello World",
+ "numbers": [1, 2, 3, 4, 5]
+}
+```
+
+**Template Content**:
+```
+Text Length: {d.greeting:len()}
+Array Length: {d.numbers:len()}
+```
+
+**Rendering Result**:
+```
+Text Length: 11
+Array Length: 5
+```
+
+**Note**: Can be used for both strings and arrays, returning their length or number of elements.
+
+---
+
+### 19. t( )
+
+**Syntax**:
+```
+{d.someField:t()}
+```
+
+**Example**:
+
+Assume you have defined a translation dictionary in Carbone configuration, translating the text `"Submit"` to `"提交"`.
+
+**Dataset**:
+```json
+{
+ "buttonLabel": "Submit"
+}
+```
+
+**Template Content**:
+```
+Button: {d.buttonLabel:t()}
+```
+
+**Rendering Result**:
+```
+Button: 提交
+```
+
+**Note**: Translates the string based on the translation dictionary. Requires providing the corresponding translation mapping during rendering.
+
+---
+
+### 20. preserveCharRef( )
+
+**Syntax**:
+```
+{d.someField:preserveCharRef()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "legalSymbol": "§"
+}
+```
+
+**Template Content**:
+```
+Symbol: {d.legalSymbol:preserveCharRef()}
+```
+
+**Rendering Result**:
+```
+Symbol: §
+```
+
+**Note**: Preserves character references in the form of `&#xxx;` or `&#xXXXX;`, preventing them from being escaped or replaced in XML. This is useful for generating specific character sets or special symbols.
+
+---
+The following examples follow the document style described above to help you better understand and apply **number operation** formatters. Examples will include **syntax**, **examples** (including "dataset", "template content", "rendering result"), and brief **notes**. Some examples will also mention optional rendering configurations (`options`) to demonstrate how they affect the output.
+
+---
+
+
+## Number Operation Formatter Examples
+
+### 1. convCurr( target, source )
+
+**Syntax**:
+```
+{d.numberField:convCurr(target, source)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "amount": 1000
+}
+```
+
+> Assume the following settings in `Carbone.render(data, options)`:
+> ```json
+> {
+> "currency": {
+> "source": "EUR",
+> "target": "USD",
+> "rates": {
+> "EUR": 1,
+> "USD": 2
+> }
+> }
+> }
+> ```
+
+**Template Content**:
+```
+Default conversion from EUR to USD: {d.amount:convCurr()}
+Directly specify target as USD: {d.amount:convCurr('USD')}
+Directly specify target as EUR: {d.amount:convCurr('EUR')}
+EUR->USD, then force USD->USD: {d.amount:convCurr('USD','USD')}
+```
+
+**Rendering Result**:
+```
+Default conversion from EUR to USD: 2000
+Directly specify target as USD: 2000
+Directly specify target as EUR: 1000
+EUR->USD, then force USD->USD: 1000
+```
+
+**Note**:
+- If `target` is not specified, it defaults to `options.currencyTarget` ("USD" in the example).
+- If `source` is not specified, it defaults to `options.currencySource` ("EUR" in the example).
+- If `options.currencySource` is not defined, no conversion is performed, and the original value is output.
+
+---
+
+### 2. round( precision )
+
+**Syntax**:
+```
+{d.numberField:round(precision)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "price": 10.05123,
+ "discount": 1.05
+}
+```
+
+**Template Content**:
+```
+Price rounded to 2 decimal places: {d.price:round(2)}
+Discount rounded to 1 decimal place: {d.discount:round(1)}
+```
+
+**Rendering Result**:
+```
+Price rounded to 2 decimal places: 10.05
+Discount rounded to 1 decimal place: 1.1
+```
+
+**Note**:
+Unlike `toFixed()`, `round()` uses correct rounding for decimals, e.g., `1.05` rounded to one decimal place becomes `1.1`.
+
+---
+
+### 3. formatN( precision )
+
+**Syntax**:
+```
+{d.numberField:formatN(precision)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "total": 1000.456
+}
+```
+
+> Assume in `Carbone.render(data, options)`, `options.lang` is `en-us`, and the document type is not ODS/XLSX (e.g., DOCX, PDF, etc.).
+
+**Template Content**:
+```
+Number Formatting: {d.total:formatN()}
+Number Formatting (2 decimal places): {d.total:formatN(2)}
+```
+
+**Rendering Result**:
+```
+Number Formatting: 1,000.456
+Number Formatting (2 decimal places): 1,000.46
+```
+
+**Note**:
+- `formatN()` localizes numbers based on `options.lang` (thousands separator, decimal point, etc.).
+- For ODS/XLSX files, number precision mainly depends on the cell format settings in the spreadsheet.
+
+---
+
+### 4. formatC( precisionOrFormat, targetCurrencyCode )
+
+**Syntax**:
+```
+{d.numberField:formatC(precisionOrFormat, targetCurrencyCode)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "amount": 1000.456
+}
+```
+
+> Assume the following settings in `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en-us",
+> "currency": {
+> "source": "EUR",
+> "target": "USD",
+> "rates": {
+> "EUR": 1,
+> "USD": 2
+> }
+> }
+> }
+> ```
+
+**Template Content**:
+```
+Default conversion with currency symbol: {d.amount:formatC()}
+Only output currency name (M): {d.amount:formatC('M')}
+Only output currency name, singular case: {1:formatC('M')}
+Number + symbol (L): {d.amount:formatC('L')}
+Number + currency name (LL): {d.amount:formatC('LL')}
+```
+
+**Rendering Result**:
+```
+Default conversion with currency symbol: $2,000.91
+Only output currency name (M): dollars
+Only output currency name, singular case: dollar
+Number + symbol (L): $2,000.00
+Number + currency name (LL): 2,000.00 dollars
+```
+
+**Note**:
+- `precisionOrFormat` can be a number (specifying decimal places) or a string ("M", "L", "LL").
+- To switch to another currency, pass `targetCurrencyCode`, e.g., `formatC('L', 'EUR')`.
+
+---
+
+### 5. add( )
+
+**Syntax**:
+```
+{d.numberField:add(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Add 2 to the value: {d.base:add(2)}
+```
+
+**Rendering Result**:
+```
+Add 2 to the value: 1002.4
+```
+
+**Note**: Adds the parameter to `d.base`, supports string numbers or pure numbers.
+
+---
+
+### 6. sub( )
+
+**Syntax**:
+```
+{d.numberField:sub(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Subtract 2 from the value: {d.base:sub(2)}
+```
+
+**Rendering Result**:
+```
+Subtract 2 from the value: 998.4
+```
+
+**Note**: Subtracts the parameter from `d.base`.
+
+---
+
+### 7. mul( )
+
+**Syntax**:
+```
+{d.numberField:mul(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Multiply the value by 2: {d.base:mul(2)}
+```
+
+**Rendering Result**:
+```
+Multiply the value by 2: 2000.8
+```
+
+**Note**: Multiplies `d.base` by the parameter.
+
+---
+
+### 8. div( )
+
+**Syntax**:
+```
+{d.numberField:div(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**Template Content**:
+```
+Divide the value by 2: {d.base:div(2)}
+```
+
+**Rendering Result**:
+```
+Divide the value by 2: 500.2
+```
+
+**Note**: Divides `d.base` by the parameter.
+
+---
+
+### 9. mod( value )
+
+**Syntax**:
+```
+{d.numberField:mod(value)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "num1": 4,
+ "num2": 3
+}
+```
+
+**Template Content**:
+```
+4 mod 2: {d.num1:mod(2)}
+3 mod 2: {d.num2:mod(2)}
+```
+
+**Rendering Result**:
+```
+4 mod 2: 0
+3 mod 2: 1
+```
+
+**Note**: Calculates `num1 % 2` and `num2 % 2`, used for modulo operations.
+
+---
+
+### 10. abs( )
+
+**Syntax**:
+```
+{d.numberField:abs()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "value1": -10,
+ "value2": -10.54
+}
+```
+
+**Template Content**:
+```
+Absolute Value 1: {d.value1:abs()}
+Absolute Value 2: {d.value2:abs()}
+```
+
+**Rendering Result**:
+```
+Absolute Value 1: 10
+Absolute Value 2: 10.54
+```
+
+**Note**: Returns the absolute value of the number, can also handle negative numbers in string format.
+
+---
+
+### 11. ceil( )
+
+**Syntax**:
+```
+{d.numberField:ceil()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "dataA": 10.05123,
+ "dataB": 1.05,
+ "dataC": -1.05
+}
+```
+
+**Template Content**:
+```
+ceil(10.05123): {d.dataA:ceil()}
+ceil(1.05): {d.dataB:ceil()}
+ceil(-1.05): {d.dataC:ceil()}
+```
+
+**Rendering Result**:
+```
+ceil(10.05123): 11
+ceil(1.05): 2
+ceil(-1.05): -1
+```
+
+**Note**: Rounds the number up to the nearest greater (or equal) integer.
+
+---
+
+### 12. floor( )
+
+**Syntax**:
+```
+{d.numberField:floor()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "dataA": 10.05123,
+ "dataB": 1.05,
+ "dataC": -1.05
+}
+```
+
+**Template Content**:
+```
+floor(10.05123): {d.dataA:floor()}
+floor(1.05): {d.dataB:floor()}
+floor(-1.05): {d.dataC:floor()}
+```
+
+**Rendering Result**:
+```
+floor(10.05123): 10
+floor(1.05): 1
+floor(-1.05): -2
+```
+
+**Note**: Rounds the number down to the nearest smaller (or equal) integer.
+
+---
+
+### 13. int( )
+
+> **Note**: **Not recommended**.
+> **Syntax**:
+```
+{d.numberField:int()}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "price": 12.34
+}
+```
+
+**Template Content**:
+```
+Result: {d.price:int()}
+```
+
+**Rendering Result**:
+```
+Result: 12
+```
+
+**Note**: Converts the number to an integer by removing the decimal part; the official documentation recommends using more accurate `round()` or `floor()`/`ceil()` instead.
+
+---
+
+### 14. toEN( )
+
+> **Note**: **Not recommended**.
+> **Syntax**:
+```
+{d.numberField:toEN()}
+```
+
+**Note**: Converts numbers to English format with decimal point `.` separation, without localization. It is generally recommended to use `formatN()` for multi-language scenarios.
+
+---
+
+### 15. toFixed( )
+
+> **Note**: **Not recommended**.
+> **Syntax**:
+```
+{d.numberField:toFixed(decimalCount)}
+```
+
+**Description**: Converts a number to a string and retains the specified number of decimal places, but there may be inaccuracies in rounding. It is recommended to use `round()` or `formatN()` instead.
+
+---
+
+### 16. toFR( )
+
+> **Note**: **Not recommended for use**.
+> **Syntax**:
+```
+{d.numberField:toFR()}
+```
+
+**Description**: Converts a number to a format suitable for French locale with a comma `,` as the decimal separator, but does not perform further localization. It is recommended to use `formatN()` or `formatC()` for more flexibility in multilingual and currency scenarios.
+
+---
+
+## Array Manipulation
+
+### 1. aggStr( separator )
+> **Version**: ENTERPRISE FEATURE, NEWv4.17.0+
+> **Function**: Merges values in an array into a single string, concatenated with an optional `separator`. If no separator is provided, it defaults to `,`.
+
+**Syntax**:
+```
+{d.arrayField[].someAttr:aggStr(separator)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "cars": [
+ {"brand":"Tesla","qty":1,"sort":1},
+ {"brand":"Ford","qty":4,"sort":4},
+ {"brand":"Jeep","qty":3,"sort":3},
+ {"brand":"GMC","qty":2,"sort":2},
+ {"brand":"Rivian","qty":1,"sort":1},
+ {"brand":"Chevrolet","qty":10,"sort":5}
+ ]
+}
+```
+
+**Template Content**:
+```
+All brands (default comma separator):
+{d.cars[].brand:aggStr}
+
+All brands (specified hyphen separator):
+{d.cars[].brand:aggStr(' - ')}
+
+Filtered brands with qty greater than 3:
+{d.cars[.qty > 3].brand:aggStr()}
+```
+
+**Rendered Result**:
+```
+All brands (default comma separator):
+Tesla, Ford, Jeep, GMC, Rivian, Chevrolet
+
+All brands (specified hyphen separator):
+Tesla - Ford - Jeep - GMC - Rivian - Chevrolet
+
+Filtered brands with qty greater than 3:
+Ford, Chevrolet
+```
+
+**Description**:
+- Use `:aggStr` to extract and merge fields in an array, which can be combined with filtering conditions (e.g., `[.qty > 3]`) for more flexible output.
+- The `separator` parameter can be omitted, defaulting to a comma followed by a space (`, `).
+
+---
+
+### 2. arrayJoin( separator, index, count )
+> **Version**: NEWv4.12.0+
+> **Function**: Merges array elements (`String` or `Number`) into a single string; optionally specifies which segment of the array to start merging from.
+
+**Syntax**:
+```
+{d.arrayField:arrayJoin(separator, index, count)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "names": ["homer", "bart", "lisa"],
+ "emptyArray": [],
+ "notArray": 20
+}
+```
+
+**Template Content**:
+```
+Default comma separator: {d.names:arrayJoin()}
+Using " | " separator: {d.names:arrayJoin(' | ')}
+Using empty string separator: {d.names:arrayJoin('')}
+Merging all elements starting from the second item: {d.names:arrayJoin('', 1)}
+Merging 1 element starting from the second item: {d.names:arrayJoin('', 1, 1)}
+Merging from the first item to the second last item: {d.names:arrayJoin('', 0, -1)}
+
+Empty array: {d.emptyArray:arrayJoin()}
+Non-array data: {d.notArray:arrayJoin()}
+```
+
+**Rendered Result**:
+```
+Default comma separator: homer, bart, lisa
+Using " | " separator: homer | bart | lisa
+Using empty string separator: homerbartlisa
+Merging all elements starting from the second item: bartlisa
+Merging 1 element starting from the second item: bart
+Merging from the first item to the second last item: homerbart
+
+Empty array:
+Non-array data: 20
+```
+
+**Description**:
+- `separator` defaults to a comma followed by a space (`, `).
+- `index` and `count` are used to extract a portion of the array; `count` can be negative to indicate counting from the end.
+- If the data is not of array type (`null`, `undefined`, object, or number), it will be output as is.
+
+---
+
+### 3. arrayMap( objSeparator, attributeSeparator, attributes )
+> **Version**: v0.12.5+
+> **Function**: Maps an array of objects into a string. Allows specifying separators between objects and attributes, as well as which attributes to output.
+
+**Syntax**:
+```
+{d.arrayField:arrayMap(objSeparator, attributeSeparator, attributes)}
+```
+
+**Example**:
+
+```json
+{
+ "people": [
+ { "id": 2, "name": "homer" },
+ { "id": 3, "name": "bart" }
+ ],
+ "numbers": [10, 50],
+ "emptyArray": [],
+ "mixed": {"id":2,"name":"homer"}
+}
+```
+
+**Template Content**:
+```
+Default mapping (using comma+space as object separator, colon as attribute separator):
+{d.people:arrayMap()}
+
+Using " - " as object separator:
+{d.people:arrayMap(' - ')}
+
+Using " | " as attribute separator:
+{d.people:arrayMap(' ; ', '|')}
+
+Mapping only id:
+{d.people:arrayMap(' ; ', '|', 'id')}
+
+Numeric array:
+{d.numbers:arrayMap()}
+
+Empty array:
+{d.emptyArray:arrayMap()}
+
+Non-array data:
+{d.mixed:arrayMap()}
+```
+
+**Rendered Result**:
+```
+Default mapping:
+2:homer, 3:bart
+
+Using " - " as object separator:
+2:homer - 3:bart
+
+Using " | " as attribute separator:
+2|homer ; 3|bart
+
+Mapping only id:
+2 ; 3
+
+Numeric array:
+10, 50
+
+Empty array:
+
+Non-array data:
+{ "id": 2, "name": "homer" }
+```
+
+**Description**:
+- If it is an array of objects, all available first-level attributes are output by default, concatenated in the form `attributeName:attributeValue`.
+- `objSeparator` is used to separate different objects, defaulting to a comma followed by a space; `attributeSeparator` separates attributes, defaulting to a colon `:`; `attributes` can specify which attributes to output.
+- If the input data is not an array, it is output as is.
+
+---
+
+### 4. count( start )
+> **Version**: v1.1.0+
+> **Function**: Prints a **line number** or **sequence number** in a loop (e.g., `{d.array[i].xx}`), starting from 1 by default.
+> **Note**: Starting from v4.0.0, this function has been internally replaced by `:cumCount`.
+
+**Syntax**:
+```
+{d.array[i].someField:count(start)}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "employees": [
+ { "name": "James" },
+ { "name": "Emily" },
+ { "name": "Michael" }
+ ]
+}
+```
+
+**Template Content**:
+```
+Employee List:
+No. | Name
+{d.employees[i].name:count()}. {d.employees[i].name}
+{d.employees[i+1]}
+```
+
+**Rendered Result**:
+```
+Employee List:
+No. | Name
+1. James
+2. Emily
+3. Michael
+```
+
+**Description**:
+- Only valid in loops (including scenarios like `{d.array[i].xx}`), used to print the current line index count.
+- `start` can specify a starting number, e.g., `:count(5)` will start counting from 5.
+- Carbone 4.0+ recommends using `:cumCount` for more flexibility.
+
+---
+
+# Conditioned Output
+
+Carbone provides a series of condition-based output formatters to **hide** or **display** specified content in templates based on specific conditions. Depending on business needs, you can choose **`drop`/`keep`** (concise usage) or **`showBegin`/`showEnd`**, **`hideBegin`/`hideEnd`** (suitable for large sections of content).
+
+### 1. drop(element)
+> **Version**: ENTERPRISE FEATURE, UPDATEDv4.22.10+
+> **Function**: If the condition is true, **deletes** an element or several elements in the document, such as paragraphs, table rows, images, charts, etc.
+
+**Syntax**:
+```
+{d.data:ifEM():drop(element, nbrToDrop)}
+```
+- `element`: Can be `p` (paragraph), `row` (table row), `img` (image), `table` (entire table), `chart` (chart), `shape` (shape), `slide` (slide, ODP only), or `item` (list item, ODP/ODT only).
+- `nbrToDrop`: Optional, an integer indicating how many elements to delete starting from the current one.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "imgUrl": null
+}
+```
+
+**Template Content** (DOCX scenario, simplified example):
+```
+Here is an image: {d.imgUrl:ifEM:drop(img)}
+```
+
+- In the Word template, place this placeholder in the image's title or description.
+
+**Rendered Result**:
+```
+Here is an image:
+```
+> The image is deleted because `imgUrl` is empty (`ifEM` is true).
+
+**Description**:
+- If the `ifEM` condition is met, `drop(img)` is executed, deleting the image and its associated paragraph content.
+- `drop` is only supported in DOCX/ODT/ODS/ODP/PPTX/PDF/HTML; once `drop` is executed, no other formatters are executed.
+
+---
+
+### 2. keep(element)
+> **Version**: ENTERPRISE FEATURE, NEWv4.17.0+
+> **Function**: If the condition is true, **retains/displays** an element or several elements in the document; otherwise, it does not display them.
+
+**Syntax**:
+```
+{d.data:ifNEM:keep(element, nbrToKeep)}
+```
+- `element`: Same as `drop`, can be `p`, `row`, `img`, `table`, `chart`, `shape`, `slide`, `item`, etc.
+- `nbrToKeep`: Optional, an integer indicating how many elements to retain starting from the current one.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "tableData": []
+}
+```
+
+**Template Content** (DOCX scenario, simplified example):
+```
+{d.tableData:ifNEM:keep(table)}
+```
+
+- In the Word template, place this placeholder in a cell within the table.
+
+**Rendered Result**:
+```
+(Blank)
+```
+> Since `tableData` is empty, `ifNEM` is false (not empty fails), so the table is not retained, and the entire table is deleted.
+
+**Description**:
+- If the condition is met, the corresponding element is retained; otherwise, the element and all its content are deleted.
+- Opposite to `drop`, `keep` deletes the element when the condition is not met.
+
+---
+
+### 3. showBegin()/showEnd()
+> **Version**: COMMUNITY FEATURE, v2.0.0+
+> **Function**: Displays the content between `showBegin` and `showEnd` (which can include multiple paragraphs, tables, images, etc.), retaining this section if the condition is true, otherwise deleting it.
+
+**Syntax**:
+```
+{d.someData:ifEQ(someValue):showBegin}
+...Content to display...
+{d.someData:showEnd}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "toBuy": true
+}
+```
+
+**Template Content**:
+```
+Banana{d.toBuy:ifEQ(true):showBegin}
+Apple
+Pineapple
+{d.toBuy:showEnd}grapes
+```
+
+**Rendered Result**:
+```
+Banana
+Apple
+Pineapple
+grapes
+```
+> When `toBuy` is `true`, all content between `showBegin` and `showEnd` is displayed.
+
+**Description**:
+- Suitable for **multi-line or multi-page** content hiding and displaying; if it's just a single line, consider using `keep`/`drop` for a more concise approach.
+- It is recommended to use only **line breaks (Shift+Enter)** between `showBegin` and `showEnd` to ensure proper rendering.
+
+---
+
+### 4. hideBegin()/hideEnd()
+> **Version**: COMMUNITY FEATURE, v2.0.0+
+> **Function**: Hides the content between `hideBegin` and `hideEnd`, deleting this section if the condition is true, otherwise retaining it.
+
+**Syntax**:
+```
+{d.someData:ifEQ(someValue):hideBegin}
+...Content to hide...
+{d.someData:hideEnd}
+```
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "toBuy": true
+}
+```
+
+**Template Content**:
+```
+Banana{d.toBuy:ifEQ(true):hideBegin}
+Apple
+Pineapple
+{d.toBuy:hideEnd}grapes
+```
+
+**Rendered Result**:
+```
+Banana
+grapes
+```
+> When `toBuy` is `true`, the content between `hideBegin` and `hideEnd` (Apple, Pineapple) is hidden.
+
+**Description**:
+- Opposite to `showBegin()/showEnd()`, used to hide multiple paragraphs, tables, images, etc.
+- Similarly, it is recommended to use only **line breaks (Shift+Enter)** between `hideBegin` and `hideEnd`.
+
+---
+
+## Date and Time Operation Formatter Examples
+
+> **Note**: Starting from v3.0.0, Carbone uses [Day.js](https://day.js.org/docs/en/display/format) for date processing. Most formats related to Moment.js are still available in Day.js, but the underlying library has been replaced with Day.js.
+
+### 1. Usage of {c.now}
+
+In templates, you can use `{c.now}` to get the current UTC time (`now`), provided that no custom data is passed through `options.complement` to override it during rendering. Example:
+
+**Dataset** (can be empty or without `c` field):
+```json
+{}
+```
+
+**Template Content**:
+```
+Current time: {c.now:formatD('YYYY-MM-DD HH:mm:ss')}
+```
+
+**Rendered Result** (example):
+```
+Current time: 2025-01-07 10:05:30
+```
+
+**Description**:
+- `{c.now}` is a reserved tag that automatically inserts the system's current UTC time.
+- Use with `:formatD()` and other formatters to output in the specified format.
+
+---
+
+### 2. formatD( patternOut, patternIn )
+
+**Syntax**:
+```
+{d.dateField:formatD(patternOut, patternIn)}
+```
+
+- `patternOut`: The output date format, conforming to Day.js format specifications or localized formats (e.g., `L`, `LL`, `LLLL`, etc.).
+- `patternIn`: The input date format, defaulting to ISO 8601, can specify formats like `YYYYMMDD`, `X` (Unix timestamp), etc.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "eventDate": "20160131"
+}
+```
+
+> Assume during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+Date (short format): {d.eventDate:formatD('L')}
+Date (full English): {d.eventDate:formatD('LLLL')}
+Day of the week: {d.eventDate:formatD('dddd')}
+```
+
+**Rendered Result**:
+```
+Date (short format): 01/31/2016
+Date (full English): Sunday, January 31, 2016 12:00 AM
+Day of the week: Sunday
+```
+
+**Description**:
+- If `patternIn` is not specified, it defaults to ISO 8601, but here `20160131` can also be automatically recognized. To explicitly specify, use `{d.eventDate:formatD('L', 'YYYYMMDD')}`.
+- `options.lang` and `options.timezone` affect the output language and timezone conversion.
+
+---
+
+### 3. formatI( patternOut, patternIn )
+
+**Syntax**:
+```
+{d.durationField:formatI(patternOut, patternIn)}
+```
+
+- `patternOut`: The output format, can be `human`, `human+`, `milliseconds/ms`, `seconds/s`, `minutes/m`, `hours/h`, `days/d`, `weeks/w`, `months/M`, `years/y`, etc.
+- `patternIn`: Optional, the input unit defaults to milliseconds, can also specify `seconds`, `minutes`, `hours`, `days`, etc.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "intervalMs": 2000,
+ "longIntervalMs": 3600000
+}
+```
+
+> Assume during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+2000 milliseconds to seconds: {d.intervalMs:formatI('second')}
+3600000 milliseconds to minutes: {d.longIntervalMs:formatI('minute')}
+3600000 milliseconds to hours: {d.longIntervalMs:formatI('hour')}
+```
+
+**Rendering Result**:
+```
+2000 milliseconds to seconds: 2
+3600000 milliseconds to minutes: 60
+3600000 milliseconds to hours: 1
+```
+
+**Explanation**:
+- Convert time intervals between units, or output human-readable time (e.g., `human`/`human+`) to display "a few seconds ago" or "in a few minutes."
+- For handling positive and negative values, `human+` will output "...ago" or "in a few ...", while `human` only outputs expressions like "a few seconds" without direction.
+
+---
+
+### 4. addD( amount, unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:addD(amount, unit, patternIn)}
+```
+
+- `amount`: A number or string indicating the quantity to add.
+- `unit`: Available units include `day`, `week`, `month`, `year`, `hour`, `minute`, `second`, `millisecond` (case-insensitive, and supports plural and abbreviations).
+- `patternIn`: Optional, specifies the input date format, defaults to ISO8601.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "startDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+> Assuming during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "fr",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+Add 3 days to startDate: {d.startDate:addD('3', 'day')}
+Add 3 months to startDate: {d.startDate:addD('3', 'month')}
+```
+
+**Rendering Result**:
+```
+Add 3 days to startDate: 2017-05-13T12:57:23.769Z
+Add 3 months to startDate: 2017-08-10T12:57:23.769Z
+```
+
+**Explanation**:
+- The result is displayed in UTC time. To localize the output, use formatters like `formatD('YYYY-MM-DD HH:mm')`.
+- If the input date is in a format like `20160131` and `patternIn` is not explicitly specified, Day.js may automatically recognize it. However, it is recommended to use `{d.field:addD('...', '...', 'YYYYMMDD')}` for accuracy.
+
+---
+
+### 5. subD( amount, unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:subD(amount, unit, patternIn)}
+```
+
+- Similar to `addD()`, but moves the date backward.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "myDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**Template Content**:
+```
+Subtract 3 days from myDate: {d.myDate:subD('3', 'day')}
+Subtract 3 months from myDate: {d.myDate:subD('3', 'month')}
+```
+
+**Rendering Result**:
+```
+Subtract 3 days from myDate: 2017-05-07T12:57:23.769Z
+Subtract 3 months from myDate: 2017-02-10T12:57:23.769Z
+```
+
+**Explanation**:
+- Opposite to `addD`, `subD` moves the date in the past direction.
+- Supports the same units and format configurations.
+
+---
+
+### 6. startOfD( unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:startOfD(unit, patternIn)}
+```
+
+- `unit`: `day`, `month`, `year`, `week`, etc., sets the date to the start of the unit (e.g., `day`=midnight, `month`=1st 00:00:00, etc.).
+- `patternIn`: Optional, specifies the input date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "someDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**Template Content**:
+```
+Set someDate to the start of the day: {d.someDate:startOfD('day')}
+Set someDate to the start of the month: {d.someDate:startOfD('month')}
+```
+
+**Rendering Result**:
+```
+Set someDate to the start of the day: 2017-05-10T00:00:00.000Z
+Set someDate to the start of the month: 2017-05-01T00:00:00.000Z
+```
+
+**Explanation**:
+- Commonly used in scenarios like report statistics or aligning to a specific time granularity.
+
+---
+
+### 7. endOfD( unit, patternIn )
+
+**Syntax**:
+```
+{d.dateField:endOfD(unit, patternIn)}
+```
+
+- `unit`: `day`, `month`, `year`, etc., sets the date to the end of the unit (e.g., `day`=23:59:59.999, `month`=last day 23:59:59.999, etc.).
+- `patternIn`: Optional, specifies the input date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "someDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**Template Content**:
+```
+Set someDate to the end of the day: {d.someDate:endOfD('day')}
+Set someDate to the end of the month: {d.someDate:endOfD('month')}
+```
+
+**Rendering Result**:
+```
+Set someDate to the end of the day: 2017-05-10T23:59:59.999Z
+Set someDate to the end of the month: 2017-05-31T23:59:59.999Z
+```
+
+**Explanation**:
+- Corresponds to `startOfD`, pushing the date to the last moment of the day, month, or year.
+
+---
+
+### 8. diffD( toDate, unit, patternFromDate, patternToDate )
+
+**Syntax**:
+```
+{d.fromDate:diffD(toDate, unit, patternFromDate, patternToDate)}
+```
+
+- `toDate`: The target date for comparison, which can be a string or number (Unix timestamp).
+- `unit`: Optional, supports `day/d`, `week/w`, `month/M`, `year/y`, `hour/h`, `minute/m`, `second/s`, `millisecond/ms`, defaults to milliseconds.
+- `patternFromDate` / `patternToDate`: Optional, specifies the input date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "start": "20101001"
+}
+```
+
+**Template Content**:
+```
+Default millisecond interval: {d.start:diffD('20101201')}
+In seconds: {d.start:diffD('20101201', 'second')}
+In days: {d.start:diffD('20101201', 'days')}
+```
+
+**Rendering Result**:
+```
+Default millisecond interval: 5270400000
+In seconds: 5270400
+In days: 61
+```
+
+**Explanation**:
+- If the original date format differs from the target date format, specify them using `patternFromDate` and `patternToDate`.
+- A positive difference indicates that `toDate` is later or larger than `fromDate`; a negative difference indicates the opposite.
+
+---
+
+### 9. convDate( patternIn, patternOut )
+
+> **Note**: **Not Recommended**
+> Starting from v3.0.0, it is officially recommended to use `formatD(patternOut, patternIn)`, which offers more flexibility and better compatibility with Day.js.
+
+**Syntax**:
+```
+{d.dateField:convDate(patternIn, patternOut)}
+```
+
+- `patternIn`: Input date format.
+- `patternOut`: Output date format.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "myDate": "20160131"
+}
+```
+
+> Assuming during `Carbone.render(data, options)`:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**Template Content**:
+```
+Short date: {d.myDate:convDate('YYYYMMDD', 'L')}
+Full date: {d.myDate:convDate('YYYYMMDD', 'LLLL')}
+```
+
+**Rendering Result**:
+```
+Short date: 01/31/2016
+Full date: Sunday, January 31, 2016 12:00 AM
+```
+
+**Explanation**:
+- Similar to `formatD`, but marked as **Not Recommended** (UNRECOMMENDED).
+- It is recommended to use `formatD` in new projects.
+
+---
+
+### Day.js Date Format Cheatsheet
+
+The following common formats can be used in `patternOut` (partial examples):
+
+| Format | Example Output | Description |
+|:---- |:------------------------ |:------------------------------------------------ |
+| `X` | `1360013296` | Unix timestamp (in seconds) |
+| `x` | `1360013296123` | Unix timestamp in milliseconds |
+| `YYYY` | `2025` | Four-digit year |
+| `MM` | `01-12` | Two-digit month |
+| `DD` | `01-31` | Two-digit day |
+| `HH` | `00-23` | Two-digit hour in 24-hour format |
+| `mm` | `00-59` | Two-digit minutes |
+| `ss` | `00-59` | Two-digit seconds |
+| `dddd` | `Sunday-Saturday` | Full name of the day of the week |
+| `ddd` | `Sun-Sat` | Abbreviated name of the day of the week |
+| `A` | `AM` / `PM` | Uppercase AM/PM |
+| `a` | `am` / `pm` | Lowercase am/pm |
+| `L` | `MM/DD/YYYY` | Localized short date format |
+| `LL` | `MMMM D, YYYY` | Localized date with full month name |
+| `LLL` | `MMMM D, YYYY h:mm A` | Localized date with time and full month name |
+| `LLLL` | `dddd, MMMM D, YYYY h:mm A` | Full localized date with day of the week |
+
+For more formats, refer to the [Day.js official documentation](https://day.js.org/docs/en/display/format) or the list above.
+
+---
+
+## Other Condition Controllers
+
+Carbone provides various **conditionals** (`ifEQ`, `ifNE`, `ifGT`, `ifGTE`, `ifLT`, `ifLTE`, `ifIN`, `ifNIN`, `ifEM`, `ifNEM`, `ifTE`, etc.), as well as **logical combinations** (`and()`, `or()`) and **branch outputs** (`show(message)`, `elseShow(message)`). These can be combined to implement flexible conditional logic in templates. Below are some common examples; for more details, refer to the official documentation:
+
+- **ifEM()**: Checks if the value is empty (`null`, `undefined`, `[]`, `{}`, `""`, etc.).
+- **ifNEM()**: Checks if the value is not empty.
+- **ifEQ(value)** / **ifNE(value)** / **ifGT(value)** / **ifGTE(value)** / **ifLT(value)** / **ifLTE(value)**: Standard comparison operations.
+- **ifIN(value)** / **ifNIN(value)**: Checks if a string or array contains the specified content.
+- **ifTE(type)**: Checks the data type (string, number, array, object, boolean, binary, etc.).
+- **and(value)** / **or(value)**: Changes the default logical connection method.
+- **show(message)** / **elseShow(message)**: Outputs the corresponding message string when the condition is true or false.
+
+**Example**:
+
+**Dataset**:
+```json
+{
+ "status1": 1,
+ "status2": 2,
+ "status3": 3
+}
+```
+
+**Template Content**:
+```
+one = { d.status1:ifEQ(2):show(two):or(.status1):ifEQ(1):show(one):elseShow(unknown) }
+
+two = { d.status2:ifEQ(2):show(two):or(.status2):ifEQ(1):show(one):elseShow(unknown) }
+
+three = { d.status3:ifEQ(2):show(two):or(.status3):ifEQ(1):show(one):elseShow(unknown) }
+```
+
+**Rendering Result**:
+```
+one = "one"
+two = "two"
+three = "unknown"
+```
+
+**Explanation**:
+- `:ifEQ(2):show(two)` means if the value equals 2, output "two"; otherwise, proceed to the next condition (`or(.status1):ifEQ(1):show(one)`).
+- `or()` and `and()` are used to configure logical operators.
+- `elseShow('unknown')` outputs "unknown" when all preceding conditions are false.
+
+---
+
+Through **array operations** and **conditional output** examples, you can:
+1. **Flexibly handle arrays**: Use `:aggStr`, `:arrayJoin`, `:arrayMap`, `:count`, etc., to achieve **merging, concatenation, mapping**, and **counting**.
+2. **Precisely control content display**: Use `drop` / `keep` or `showBegin` / `showEnd` / `hideBegin` / `hideEnd` to decide whether to retain **specific elements** or **large sections of content** in the document based on conditions (`ifEQ`, `ifGT`, etc.).
+3. **Combine multiple conditions**: Work with number and string-related formatters (e.g., `ifNEM`, `ifIN`, etc.) to implement more complex business logic control.
+---
+
+The following examples continue the previous documentation style, demonstrating the usage of **date and time operation** related formatters. To better understand the purpose of each formatter, the examples include **syntax**, **examples** (with "dataset," "template content," and "rendering result"), and necessary **explanations**. Some formatters can be used in conjunction with rendering configuration (`options`) such as timezone (`timezone`) and language (`lang`) for more flexible date and time handling.
+
+---
+
+## Common Issues and Solutions
+
+### 1. Empty Columns and Cells in Excel Templates Disappear in Rendering Results
+
+**Issue Description**: In Excel templates, if a cell has no content or style, it may be removed during rendering, causing the cell to be missing in the final document.
+
+**Solution**:
+
+- **Fill Background Color**: Fill the background color of the target empty cells to ensure they remain visible during rendering.
+- **Insert Space**: Insert a space character in empty cells to maintain the cell structure even if there is no actual content.
+- **Set Borders**: Add border styles to the table to enhance the cell boundaries and prevent cells from disappearing during rendering.
+
+**Example**:
+
+In the Excel template, set a light gray background for all target cells and insert a space in empty cells.
+
+### 2. Merged Cells Are Invalid in Output
+
+**Issue Description**: When using loop functions to output tables, if the template contains merged cells, it may cause rendering anomalies, such as loss of merging effects or data misalignment.
+
+**Solution**:
+
+- **Avoid Merged Cells**: Avoid using merged cells in loop-output tables to ensure correct data rendering.
+- **Use Center Across Selection**: If you need text to be centered across multiple cells horizontally, use the "Center Across Selection" feature instead of merging cells.
+- **Limit Merged Cell Locations**: If merged cells are necessary, only merge cells at the top or right side of the table to prevent loss of merging effects during rendering.
+
+**Example**:
+
+**Incorrect Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Merging cells in the "Department" column may cause rendering anomalies.*
+
+**Correct Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Keep each cell independent and avoid merging cells.*
+
+### 3. Error Messages During Template Rendering
+
+**Issue Description**: During the template rendering process, the system displays an error message, causing the rendering to fail.
+
+**Possible Causes**:
+
+- **Placeholder Error**: The placeholder name does not match the dataset field or there is a syntax error.
+- **Missing Data**: The dataset lacks fields referenced in the template.
+- **Improper Use of Formatters**: Incorrect formatter parameters or unsupported formatting types.
+
+**Solutions**:
+
+- **Check Placeholders**: Ensure that the placeholder names in the template match the field names in the dataset and that the syntax is correct.
+- **Validate Dataset**: Confirm that the dataset includes all fields referenced in the template and that the data format meets the requirements.
+- **Adjust Formatters**: Check the usage of formatters, ensure the parameters are correct, and use supported formatting types.
+
+**Example**:
+
+**Faulty Template**:
+```
+Order ID: {d.orderId}
+Order Date: {d.orderDate:format('YYYY/MM/DD')}
+Total Amount: {d.totalAmount:format('0.00')}
+```
+
+**Dataset**:
+```json
+{
+ "orderId": "A123456789",
+ "orderDate": "2025-01-01T10:00:00Z"
+ // Missing totalAmount field
+}
+```
+
+**Solution**: Add the `totalAmount` field to the dataset or remove the reference to `totalAmount` from the template.
+
+### 4. Template File Upload Failure
+
+**Issue Description**: When uploading a template file on the template configuration page, the upload fails.
+
+**Possible Causes**:
+
+- **Unsupported File Format**: The uploaded file format is not supported (only `.docx`, `.xlsx`, and `.pptx` are supported).
+- **File Size Too Large**: The template file is too large, exceeding the system's upload size limit.
+- **Network Issues**: Unstable network connection causing the upload to be interrupted or fail.
+
+**Solutions**:
+
+- **Check File Format**: Ensure the uploaded template file is in `.docx`, `.xlsx`, or `.pptx` format.
+- **Compress File Size**: If the file is too large, try compressing the template file or optimizing the template content to reduce the file size.
+- **Stabilize Network Connection**: Ensure a stable network connection and try the upload operation again.
+
+## Summary
+
+The template printing plugin offers powerful features, supporting template editing and dynamic data filling for various file formats. By configuring and using rich template syntax effectively, customized documents can be generated efficiently to meet different business needs, enhancing work efficiency and document quality.
+
+**Key Advantages**:
+
+- **Efficiency**: Automated data filling reduces manual operations and improves work efficiency.
+- **Flexibility**: Supports multiple template formats and complex data structures, adapting to diverse document needs.
+- **Professionalism**: Formatters and conditional output functions enhance the professionalism and readability of documents.
+
+## Frequently Asked Questions
+
+### 1. Empty Columns and Cells Disappear in Excel Template Rendering
+
+**Issue Description**: In an Excel template, if a cell has no content or style, it might be removed during rendering, causing the cell to be missing in the final document.
+
+**Solutions**:
+
+- **Fill Background Color**: Fill the background color for empty cells in the target area to ensure the cells remain visible during rendering.
+- **Insert Space**: Insert a space character in empty cells to maintain the cell structure even if there is no actual content.
+- **Set Borders**: Add border styles to the table to enhance the boundary of cells and prevent them from disappearing during rendering.
+
+**Example**:
+
+In the Excel template, set a light gray background for all target cells and insert a space in empty cells.
+
+### 2. Merged Cells Are Ineffective in Output
+
+**Issue Description**: When using loop functions to output tables, if merged cells exist in the template, it may cause rendering anomalies such as loss of merging effects or data misalignment.
+
+**Solutions**:
+
+- **Avoid Using Merged Cells**: Try to avoid using merged cells in tables output by loops to ensure correct data rendering.
+- **Use Center Across Columns**: If text needs to be centered across multiple cells, use the "Center Across Columns" function instead of merging cells.
+- **Limit Merged Cell Locations**: If merged cells must be used, merge cells only at the top or right side of the table to prevent loss of merging effects during rendering.
+
+**Example**:
+
+**Incorrect Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Merging cells in the "Department" column may cause rendering anomalies.*
+
+**Correct Example**:
+
+| Name | Department | Position |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*Keep each cell independent and avoid merging cells.*
diff --git a/docs/ja-JP/handbook/backups/install.md b/docs/ja-JP/handbook/backups/install.md
index 8f8100a2e..7fc8171cb 100644
--- a/docs/ja-JP/handbook/backups/install.md
+++ b/docs/ja-JP/handbook/backups/install.md
@@ -1,18 +1,18 @@
-### 安装数据库客户端
+### データベースクライアントのインストール
-前往官网下载与所使用的数据库版本匹配的客户端:
+使用しているデータベースのバージョンに一致するクライアントを公式サイトからダウンロードします:
- MySQL:https://dev.mysql.com/downloads/
- PostgreSQL:https://www.postgresql.org/download/
-Docker 版本,可以直接在 `./storage/scripts` 目录下,编写一段脚本
+Docker バージョンでは、`./storage/scripts` ディレクトリにスクリプトを直接記述できます。
```bash
mkdir ./storage/scripts
vim install-database-client.sh
```
-`install-database-client.sh` 的内容如下:
+`install-database-client.sh` の内容は以下の通りです:
@@ -21,11 +21,11 @@ vim install-database-client.sh
```bash
#!/bin/bash
-# Check if pg_dump is installed
+# pg_dumpがインストールされているか確認
if [ ! -f /usr/bin/pg_dump ]; then
- echo "pg_dump is not installed, starting PostgreSQL client installation..."
+ echo "pg_dumpがインストールされていません。PostgreSQLクライアントのインストールを開始します..."
- # Configure Aliyun mirrors
+ # Aliyunミラーを設定
tee /etc/apt/sources.list > /dev/null < /etc/apt/sources.list.d/pgdg.list
wget --quiet -O /usr/share/keyrings/pgdg.asc http://mirrors.aliyun.com/postgresql/repos/apt/ACCC4CF8.asc
- # Install PostgreSQL client
+ # PostgreSQLクライアントをインストール
apt-get update && apt-get install -y --no-install-recommends postgresql-client-16 \
&& rm -rf /var/lib/apt/lists/*
- echo "PostgreSQL client installation completed."
+ echo "PostgreSQLクライアントのインストールが完了しました。"
else
- echo "pg_dump is already installed, skipping PostgreSQL client installation."
+ echo "pg_dumpは既にインストールされています。PostgreSQLクライアントのインストールをスキップします。"
fi
```
@@ -62,7 +62,7 @@ fi
#!/bin/bash
if [ ! -f /usr/bin/mysql ]; then
- echo "MySQL client is not installed, starting MySQL client installation..."
+ echo "MySQLクライアントがインストールされていません。MySQLクライアントのインストールを開始します..."
tee /etc/apt/sources.list > /dev/null <
-然后重启 app 容器
+その後、appコンテナを再起動します。
```bash
docker compose restart app
-# 查看日志
+# ログを確認
docker compose logs app
```
-查看数据库客户端版本号,必须与数据库服务端的版本号一致
+データベースクライアントのバージョン番号を確認し、データベースサーバーのバージョン番号と一致することを確認します。
@@ -120,6 +120,7 @@ docker compose exec app bash -c "mysql -V"
-### 安装插件
+### プラグインのインストール
+
+[商用プラグインのインストールとアップグレード](/welcome/getting-started/plugin)を参照してください。
-参考 [商业插件的安装与升级](/welcome/getting-started/plugin)
diff --git a/docs/ja-JP/handbook/environment-variables/index.md b/docs/ja-JP/handbook/environment-variables/index.md
index 4059f4661..c1d42adcf 100644
--- a/docs/ja-JP/handbook/environment-variables/index.md
+++ b/docs/ja-JP/handbook/environment-variables/index.md
@@ -1,95 +1,95 @@
-# 环境变量
+# 環境変数
-## 介绍
+## 紹介
-集中配置和管理环境变量和密钥,用于敏感数据存储、配置数据重用、环境配置隔离等。
+環境変数とシークレットを集中管理し、機密データの保存、設定データの再利用、環境設定の分離などに使用します。
-## 与 `.env` 的区别
+## `.env` との違い
-| **特性** | **`.env` 文件** | **动态配置的环境变量** |
+| **特性** | **`.env` ファイル** | **動的設定の環境変数** |
|-----------------------|--------------------------------|-------------------------------------|
-| **存储位置** | 存储在项目根目录的 `.env` 文件中 | 存储在数据库 `environmentVariables` 表里 |
-| **加载方式** | 通过 `dotenv` 等工具在应用启动时加载到 `process.env` 中 | 动态读取,在应用启动时加载到 `app.environment` 中 |
-| **修改方式** | 需要直接编辑文件,修改后需要重启应用才能生效 | 支持在运行时修改,修改后直接重载应用配置即可 |
-| **环境隔离** | 每个环境(开发、测试、生产)需要单独维护 `.env` 文件 | 每个环境(开发、测试、生产)需要单独维护 `environmentVariables` 表的数据 |
-| **适用场景** | 适合固定的静态配置,如应用主数据库信息 | 适合需要频繁调整或与业务逻辑绑定的动态配置,如外部数据库、文件存储等信息 |
+| **保存場所** | プロジェクトルートの `.env` ファイル | データベースの `environmentVariables` テーブルに保存 |
+| **読み込み方式** | `dotenv` などのツールを使用してアプリ起動時に `process.env` に読み込む | 動的に読み取り、アプリ起動時に `app.environment` に読み込む |
+| **変更方式** | ファイルを直接編集し、変更後はアプリを再起動する必要がある | 実行中に変更可能、変更後はアプリ設定をリロードする |
+| **環境分離** | 各環境(開発、テスト、本番)ごとに `.env` ファイルを個別に管理 | 各環境(開発、テスト、本番)ごとに `environmentVariables` テーブルのデータを個別に管理 |
+| **適用シナリオ** | 固定の静的設定に適しており、アプリのメインデータベース情報など | 頻繁に調整が必要な動的設定やビジネスロジックに紐づく設定に適しており、外部データベースやファイルストレージ情報など |
-## 安装
+## インストール
-内置插件,无需单独安装。
+組み込みプラグインのため、個別のインストールは不要です。
## 用途
-### 配置数据重用
+### 設定データの再利用
-例如工作流多个地方需要邮件节点,都需要配置 SMTP,就可以将通用的 SMTP 配置存到环境变量里。
+例えば、ワークフローの複数の場所でメールノードが必要な場合、共通の SMTP 設定を環境変数に保存できます。

-### 敏感数据存储
+### 機密データの保存
-各种外部数据库的数据库配置信息、云文件存储密钥等数据的存储等。
+外部データベースの設定情報やクラウドファイルストレージのシークレットなどのデータを保存します。

-### 环境配置隔离
+### 環境設定の分離
-在软件开发、测试和生产等不同环境中,使用独立的配置管理策略来确保每个环境的配置和数据互不干扰。每个环境有各自独立的设置、变量和资源,这样可以避免开发、测试和生产环境之间的冲突,同时确保系统在每个环境中都能按预期运行。
+ソフトウェア開発、テスト、本番などの異なる環境で、独立した設定管理戦略を使用して、各環境の設定とデータが干渉しないようにします。各環境には独自の設定、変数、リソースがあり、開発、テスト、本番環境間の衝突を防ぎ、システムが各環境で期待通りに動作することを保証します。
-例如,文件存储服务,开发环境和生产环境的配置可能不同,如下:
+例えば、ファイルストレージサービスでは、開発環境と本番環境の設定が異なる場合があります。以下はその例です。
-开发环境
+開発環境
```bash
FILE_STORAGE_OSS_BASE_URL=dev-storage.nocobase.com
FILE_STORAGE_OSS_BUCKET=dev-storage
```
-生产环境
+本番環境
```bash
FILE_STORAGE_OSS_BASE_URL=prod-storage.nocobase.com
FILE_STORAGE_OSS_BUCKET=prod-storage
```
-## 环境变量管理
+## 環境変数の管理

-### 添加环境变量
+### 環境変数の追加
-- 支持单个和批量添加
-- 支持明文和加密
+- 単一および一括追加をサポート
+- 平文と暗号化をサポート

-单个添加
+単一追加

-批量添加
+一括追加

-## 注意事项
+## 注意事項
-### 重启应用
+### アプリの再起動
-修改或删除环境变量之后,顶部会出现重启应用的提示,重启之后变更的环境变量才会生效。
+環境変数を変更または削除した後、アプリの再起動を促すメッセージが上部に表示されます。再起動後、変更された環境変数が有効になります。

-### 加密存储
+### 暗号化保存
-环境变量的加密数据使用 AES 对称加密,加解密的 PRIVATE KEY 存储在 storage 里,请妥善保管,丢失或重写,加密的数据将无法解密。
+環境変数の暗号化データは AES 対称暗号化を使用し、暗号化と復号のための PRIVATE KEY は storage に保存されます。これを適切に保管してください。紛失または上書きされた場合、暗号化されたデータは復号できなくなります。
```bash
./storage/environment-variables//aes_key.dat
```
-## 目前支持环境变量的插件
+## 現在環境変数をサポートしているプラグイン
### Action: Custom request
@@ -165,7 +165,7 @@ FILE_STORAGE_OSS_BUCKET=prod-storage
### File storage: S3 Pro
-未适配
+未対応
### Map: AMap
@@ -177,7 +177,7 @@ FILE_STORAGE_OSS_BUCKET=prod-storage
### Email settings
-未适配
+未対応
### Notification: Email
diff --git a/docs/zh-CN/handbook/action-template-print/index.md b/docs/zh-CN/handbook/action-template-print/index.md
index b2331f775..bf389daec 100644
--- a/docs/zh-CN/handbook/action-template-print/index.md
+++ b/docs/zh-CN/handbook/action-template-print/index.md
@@ -4,58 +4,151 @@
## 介绍
-模板打印插件支持通过 Word、Excel 和 PowerPoint 编辑模板(支持 .docx、.xlsx、.pptx 格式),并在模板中设置占位符(placeholders)与逻辑结构。用户可以基于这些模板动态生成预定格式的文件,包括 .docx、.xlsx、.pptx 和 PDF 文件。
+模板打印插件是一款功能强大的工具,通过 Word、Excel 和 PowerPoint 编辑模板文件(支持 `.docx`、`.xlsx`、`.pptx` 格式),在模板中设置占位符和逻辑结构,从而动态生成预定格式的文件,如 `.docx`、`.xlsx`、`.pptx` 以及 PDF 文件。该插件广泛应用于生成各类业务文档,例如报价单、发票、合同等,显著提升了文档生成的效率和准确性。
-用户可以通过该功能:
+### 主要功能
-- 生成定制化报价单:通过 Excel 模板自动填充数据,生成格式化的报价单。
-- 生成并转换发票:根据 Excel 模板生成发票,并将其转换为 PDF 格式供下载。
-- 生成合同文档:通过 Word 模板生成自动填充客户信息和条款的合同文件。
+- **多格式支持**:兼容 Word、Excel 和 PowerPoint 模板,满足不同文档生成需求。
+- **动态数据填充**:通过占位符和逻辑结构,自动填充和生成文档内容。
+- **灵活的模板管理**:支持添加、编辑、删除和分类管理模板,便于维护和使用。
+- **丰富的模板语法**:支持基本替换、数组访问、循环、条件输出等多种模板语法,满足复杂文档生成需求。
+- **格式化器支持**:提供条件输出、日期格式化、数字格式化等功能,提升文档的可读性和专业性。
+- **高效的输出格式**:支持直接生成 PDF 文件,方便分享和打印。
## 配置说明
-打开任意详情区块,激活“配置操作”菜单,点击“模板打印”选项:
+### 激活模板打印功能
-
+1. **打开详情区块**:
+ - 在应用中,进入需要使用模板打印功能的详情区块。
-激活“模板打印”按钮的配置菜单,选择“模板配置”选项:
+2. **进入配置操作菜单**:
+ - 在界面上方,点击“配置操作”菜单。
-
+3. **选择“模板打印”**:
+ - 在下拉菜单中,点击“模板打印”选项以激活插件功能。
-点击“添加模板”按钮:
+ 
-
+### 配置模板
-此时在模板表单选项可以配置模板的名称,并上传模板文件:
+1. **进入模板配置页面**:
+ - 在“模板打印”按钮的配置菜单中,选择“模板配置”选项。
-
+ 
-在字段列表中可以查看当前区块可引用的所有字段,点击“复制”按钮会复制字段引用代码到剪贴板,如果该字段为关联字段,点击字段前的“加号”可展开关联字段列表:
+2. **添加新模板**:
+ - 点击“添加模板”按钮,进入模板添加页面。
-
+ 
-将所需要的字段代码逐个复制到模板文档的对应位置后,一份模板文件就制作完成了:
+3. **填写模板信息**:
+ - 在模板表单中,填写模板名称,选择模板类型(Word、Excel、PowerPoint)。
+ - 上传相应的模板文件(支持 `.docx`、`.xlsx`、`.pptx` 格式)。
-
+ 
+
+4. **编辑和保存模板**:
+ - 来到“字段列表”页面,复制字段,并填充到模板中
+ 
+ 
+ - 填写完毕后,点击“保存”按钮完成模板的添加。
+
+5. **模板管理**:
+ - 点击模板列表右侧的“使用”按钮,可以激活模板。
+ - 点击“编辑”按钮,可以修改模板名称或替换模板文件。
+ - 点击“下载”按钮,可以下载已经配置好的模板文件。
+ - 点击“删除”按钮,可以移除不再需要的模板。系统会提示确认操作以避免误删。
+ 
## 模板语法
+模板打印插件提供了多种语法,可以在模板中灵活地插入动态数据和逻辑结构。以下是详细的语法说明和使用示例。
+
### 基本替换
-模板中的占位符的格式为 {d.xxx},如 {d.title} 表示读取数据集中的title字段。
+使用 `{d.xxx}` 格式的占位符进行数据替换。例如:
+
+- `{d.title}`:读取数据集中的 `title` 字段。
+- `{d.date}`:读取数据集中的 `date` 字段。
+
+**示例**:
+
+模板内容:
+```
+尊敬的客户,您好!
+
+感谢您购买我们的产品:{d.productName}。
+订单编号:{d.orderId}
+订单日期:{d.orderDate}
+
+祝您使用愉快!
+```
+
+数据集:
+```json
+{
+ "productName": "智能手表",
+ "orderId": "A123456789",
+ "orderDate": "2025-01-01"
+}
+```
+
+渲染结果:
+```
+尊敬的客户,您好!
+
+感谢您购买我们的产品:智能手表。
+订单编号:A123456789
+订单日期:2025-01-01
+
+祝您使用愉快!
+```
### 访问子对象
-如果数据集中包含子对象,可以使用“点标记”来访问子对象,如{d.org.orgname}
+若数据集中包含子对象,可以通过点符号访问子对象的属性。
+
+**语法**:`{d.parent.child}`
+
+**示例**:
+
+数据集:
+```json
+{
+ "customer": {
+ "name": "李雷",
+ "contact": {
+ "email": "lilei@example.com",
+ "phone": "13800138000"
+ }
+ }
+}
+```
+
+模板内容:
+```
+客户姓名:{d.customer.name}
+邮箱地址:{d.customer.contact.email}
+联系电话:{d.customer.contact.phone}
+```
+
+渲染结果:
+```
+客户姓名:李雷
+邮箱地址:lilei@example.com
+联系电话:13800138000
+```
### 访问数组
-如果数据集中包含数组,可以使用保留关键字 “i” 来读取,表示数组中的第 i 项。
+若数据集中包含数组,可使用保留关键字 `i` 来访问数组中的元素。
-以打印公司所有员工中的第一位员工来举例
+**语法**:`{d.arrayName[i].field}`
-数据集:
+**示例**:
+数据集:
```json
{
"staffs": [
@@ -66,10 +159,9 @@
}
```
-模板:
-
+模板内容:
```
-第一个员工姓是 {d.employees[i=0].lastname},名是 {d.employees[0].lastname}
+第一个员工姓是 {d.staffs[i=0].lastname},名是 {d.staffs[i=0].firstname}
```
渲染结果:
@@ -77,24 +169,15 @@
第一个员工姓是 Anderson,名是 James
```
-### 循环
-
-模板打印可以循环输出数据中的数组。无需明确标注循环的起始和结束位置,只需在模板中使用保留关键字 i 和 i+1 。
-以下是一个循环示例, 模板打印会自动识别使用第一行(i)作为示例的循环模式,并在渲染结果之前移除第二行(i+1)。
-
-#### 简单数组
-
-例如,我们希望输出一个公司员工数据表格:
+### 循环输出
-**模板**
+模板打印插件支持循环输出数组中的数据,无需明确标注循环的起始和结束位置,只需在模板中使用保留关键字 `i` 和 `i+1`。插件会自动识别并处理循环部分。
-|staff firstname|staff lastname|
-|---|---|
-|d.staffs[i].firstname|d.staffs[i].firstname|
-|d.staffs[i+1]||
+#### 简单数组循环
-**数据**
+**示例**:生成公司员工数据表格
+**数据集**:
```json
{
"staffs": [
@@ -105,46 +188,82 @@
}
```
-**结果**
+**模板**:
+
+| 员工名 | 员工姓 |
+|---|---|
+| {d.staffs[i].firstname} | {d.staffs[i].lastname} |
+| {d.staffs[i+1]} | |
+
+**渲染结果**:
-|staff firstname|staff lastname|
+| 员工名 | 员工姓 |
|---|---|
-|James|Anderson|
-|Emily|Roberts|
-|Michael|Johnson|
+| James | Anderson |
+| Emily | Roberts |
+| Michael | Johnson |
+**说明**:模板中的 `{d.staffs[i].firstname}` 和 `{d.staffs[i].lastname}` 用于循环填充每位员工的姓名和姓氏。`{d.staffs[i+1]}`标记下一行的循环起始。
-#### 嵌套数组
+#### 嵌套数组循环
-模板打印可以处理嵌套数组(支持无限深度)。下面是一个示例,展示了文档中的一部分内容被循环的情况。
+模板打印插件支持处理嵌套数组,支持无限层级的循环嵌套,适用于展示复杂的数据结构。
-数据
+**示例**:展示汽车品牌及其型号
+**数据集**:
```json
-[
- {
- brand: "Toyota",
- models: [{ size: "Prius 2" }, { size: "Prius 3" }]
- },
- {
- brand: "Tesla",
- models: [{ size: "S" }, { size: "X" }]
- }
-]
+{
+ "cars": [
+ {
+ "brand": "Toyota",
+ "models": [{ "size": "Prius 2" }, { "size": "Prius 3" }]
+ },
+ {
+ "brand": "Tesla",
+ "models": [{ "size": "S" }, { "size": "X" }]
+ }
+ ]
+}
```
+**模板**:
-
+```
+品牌:{d.cars[i].brand}
+型号:
+{d.cars[i].models[j].size}
+{d.cars[i].models[j+1].size}
-#### 排序
+---
+```
+
+**渲染结果**:
+```
+品牌:Toyota
+型号:
+Prius 2
+Prius 3
+
+---
+品牌:Tesla
+型号:
+S
+X
+
+---
+```
+
+**说明**:在外层循环中使用 `i` 遍历每个品牌,内层循环使用 `j` 遍历每个品牌下的型号。`{d.cars[i].models[j].size}` 和 `{d.cars[i].models[j+1].size}` 分别用于填充当前和下一个型号。通过这种方式,可以无限层级地嵌套循环,适应复杂的数据结构。
-模板打印允许使用对象的属性,而不是保留字迭代器 i 来遍历数组。这可以用来直接在模板中对数据进行排序。
+### 排序功能
-在这个示例中,所有汽车按“power”属性进行升序排序(目前不支持降序排序)。
+模板打印插件允许根据对象的属性对数组进行排序,而不仅限于使用迭代器 `i`。目前支持按指定属性进行升序排序,暂不支持降序排序。
-数据
+**示例**:按“power”属性对汽车进行升序排序
+**数据集**:
```json
{
"cars" : [
@@ -155,33 +274,2280 @@
}
```
-
+**模板**:
+```
+{d.cars:sort(power)}
+品牌:{d.cars[i].brand}
+功率:{d.cars[i].power} kW
+
+---
+```
+
+**渲染结果**:
+```
+品牌:Tesla
+功率:1 kW
+
+---
+品牌:Toyota
+功率:2 kW
-### 格式化器
+---
+品牌:Lumeneo
+功率:3 kW
-##### 条件输出
+---
+```
+
+**说明**:使用 `:sort(power)` 对 `cars` 数组按 `power` 属性进行升序排序,然后依次渲染每辆汽车的品牌和功率。
+
+## 格式化器
+
+格式化器用于对数据进行特定格式的转换或条件判断,增强模板的灵活性和表现力。
+
+### 条件输出
+
+通过 `showBegin` 和 `showEnd` 控制特定内容的显示与隐藏。
+
+**语法**:
+```
+{d.field:condition:showBegin}
+内容
+{d.field:showEnd}
+```
+
+**示例**:在合同模板中,根据客户类型显示特殊条款
-showBegin / showEnd:根据条件显示文档中从 "showBegin" 到 "showEnd" 之间的指定部分。例如我们有一份合同模板,如果客户类型是 "VIP",则需要显示一段特殊条款。
+**数据集**:
+```json
+{
+ "customerType": "VIP"
+}
+```
-示例模板:
+**模板内容**:
+```
+{d.customerType:ifEQ('VIP'):showBegin}
+特别条款:
+作为我们的 VIP 客户,您将享受额外的优惠和专属服务,包括免费升级、优先支持等。
+{d.customerType:showEnd}
+```
+**渲染结果**(当 `customerType` 为 "VIP" 时):
```
-{d.condTrue:ifEQ('VIP'):showBegin}
-特别条款:
+特别条款:
作为我们的 VIP 客户,您将享受额外的优惠和专属服务,包括免费升级、优先支持等。
-{d.condTrue:showEnd}
```
-当客户类型是 "VIP"时,上面的特殊条款会展示,否则会隐藏。
+**说明**:当 `customerType` 字段的值等于 "VIP" 时,`showBegin` 和 `showEnd` 之间的内容将被渲染,否则将被隐藏。
+
+### 日期格式化
+
+通过格式化器对日期字段进行格式转换,提升日期的可读性。
+
+**语法**:
+```
+{d.dateField:format(YYYY年MM月DD日)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "orderDate": "2025-01-03T10:30:00Z"
+}
+```
+
+**模板内容**:
+```
+订单日期:{d.orderDate:format(YYYY年MM月DD日)}
+```
+
+**渲染结果**:
+```
+订单日期:2025年01月03日
+```
+
+**说明**:使用 `format` 格式化器将 ISO 格式的日期转换为更易读的格式。
+
+### 数字格式化
+
+通过格式化器对数字进行格式化,如千分位分隔、小数点位数控制等。
+
+**语法**:
+```
+{d.numberField:format(0,0.00)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "totalAmount": 1234567.89
+}
+```
+
+**模板内容**:
+```
+总金额:{d.totalAmount:format('0,0.00')} 元
+```
+
+**渲染结果**:
+```
+总金额:1,234,567.89 元
+```
+
+**说明**:使用 `format` 格式化器对数字进行千分位分隔,并保留两位小数。
+
+
+## 字符串格式化器示例
+
+### 1. lowerCase( )
+
+**语法**:
+```
+{d.someField:lowerCase()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "title": "My Car"
+}
+```
+
+**模板内容**:
+```
+车辆名称:{d.title:lowerCase()}
+```
+
+**渲染结果**:
+```
+车辆名称:my car
+```
+
+**说明**:将所有英文字母转换为小写。如果值非字符串(如数字、null 等),则原样输出。
+
+---
+
+### 2. upperCase( )
+
+**语法**:
+```
+{d.someField:upperCase()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "title": "my car"
+}
+```
+
+**模板内容**:
+```
+车辆名称:{d.title:upperCase()}
+```
+
+**渲染结果**:
+```
+车辆名称:MY CAR
+```
+
+**说明**:将所有英文字母转换为大写。如果值非字符串,则原样输出。
+
+---
+
+### 3. ucFirst( )
+
+**语法**:
+```
+{d.someField:ucFirst()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "note": "hello world"
+}
+```
+
+**模板内容**:
+```
+备注:{d.note:ucFirst()}
+```
+
+**渲染结果**:
+```
+备注:Hello world
+```
+
+**说明**:仅将首字母转换为大写,其他字母保持原样。如果值为 null 或 undefined,则返回 null 或 undefined。
+
+---
+
+### 4. ucWords( )
+
+**语法**:
+```
+{d.someField:ucWords()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "description": "my cAR"
+}
+```
+
+**模板内容**:
+```
+描述:{d.description:ucWords()}
+```
+
+**渲染结果**:
+```
+描述:My CAR
+```
+
+**说明**:将字符串中每个单词的首字母转为大写。其余字母保持原样。
+
+---
+
+### 5. print( message )
+
+**语法**:
+```
+{d.someField:print('固定输出')}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "unusedField": "whatever"
+}
+```
+
+**模板内容**:
+```
+提示信息:{d.unusedField:print('此处始终显示固定提示')}
+```
+
+**渲染结果**:
+```
+提示信息:此处始终显示固定提示
+```
+
+**说明**:不管原始数据为何,都会输出指定的 `message` 字符串,相当于“强制覆盖”。
+
+---
+
+### 6. printJSON( )
+
+**语法**:
+```
+{d.someField:printJSON()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "items": [
+ { "id": 2, "name": "homer" },
+ { "id": 3, "name": "bart" }
+ ]
+}
+```
+
+**模板内容**:
+```
+原始数据:{d.items:printJSON()}
+```
+
+**渲染结果**:
+```
+原始数据:[{"id":2,"name":"homer"},{"id":3,"name":"bart"}]
+```
+
+**说明**:将对象或数组序列化为 JSON 格式的字符串,以便在模板中直接输出。
+
+---
+
+### 7. convEnum( type )
+
+**语法**:
+```
+{d.someField:convEnum('ENUM_NAME')}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "orderStatus": 1
+}
+```
+假设在 `carbone.render(data, options)` 的 `options.enum` 中配置如下:
+```json
+{
+ "enum": {
+ "ORDER_STATUS": [
+ "pending", // 0
+ "sent", // 1
+ "delivered" // 2
+ ]
+ }
+}
+```
+
+**模板内容**:
+```
+订单状态:{d.orderStatus:convEnum('ORDER_STATUS')}
+```
+
+**渲染结果**:
+```
+订单状态:sent
+```
+
+**说明**:将数字或符合定义的枚举值转换为可读文本;若枚举中未定义该值,则原样输出。
+
+---
+
+### 8. unaccent( )
+
+**语法**:
+```
+{d.someField:unaccent()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "food": "crème brûlée"
+}
+```
+
+**模板内容**:
+```
+美食名称:{d.food:unaccent()}
+```
+
+**渲染结果**:
+```
+美食名称:creme brulee
+```
+
+**说明**:去除重音符号,常用于处理带有法语、西班牙语等特殊字符的文本。
+
+---
+
+### 9. convCRLF( )
+
+**语法**:
+```
+{d.someField:convCRLF()}
+```
+> **注**:适用于 DOCX、PDF、ODT、ODS(ODS 功能为实验性)。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "content": "多行文本:\n第一行\n第二行\r\n第三行"
+}
+```
+
+**模板内容**:
+```
+转换后内容:
+{d.content:convCRLF()}
+```
+
+**渲染结果**(DOCX 场景):
+```
+转换后内容:
+多行文本:
+第一行
+第二行
+第三行
+```
+> 实际 XML 会插入 `` 等换行标签。
+
+**说明**:将 `\n` 或 `\r\n` 转换为文档正确的换行标签,用于在最终文件中准确显示多行文本。
+
+---
+
+### 10. substr( begin, end, wordMode )
+
+**语法**:
+```
+{d.someField:substr(begin, end, wordMode)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "text": "abcdefg hijklmnop"
+}
+```
+
+**模板内容**:
+```
+截取内容(从索引0到5):{d.text:substr(0, 5)}
+截取内容(从索引6到末尾):{d.text:substr(6)}
+```
+
+**渲染结果**:
+```
+截取内容(从索引0到5):abcde
+截取内容(从索引6到末尾):fg hijklmnop
+```
+
+**说明**:
+- `begin` 为起始索引,`end` 为结束索引(不含)。
+- 若 `wordMode=true`,则尽量不拆分单词;若 `wordMode='last'`,则从 `begin` 一直截取到字符串结束。
+
+---
+
+### 11. split( delimiter )
+
+**语法**:
+```
+{d.someField:split(delimiter)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "path": "ab/cd/ef"
+}
+```
+
+**模板内容**:
+```
+分隔后的数组:{d.path:split('/')}
+```
+
+**渲染结果**:
+```
+分隔后的数组:["ab","cd","ef"]
+```
+
+**说明**:使用指定的 `delimiter` 将字符串拆分为数组。可与其他数组操作配合使用,如 `arrayJoin`、索引访问等。
+
+---
+
+### 12. padl( targetLength, padString )
+
+**语法**:
+```
+{d.someField:padl(targetLength, padString)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "code": "abc"
+}
+```
+
+**模板内容**:
+```
+左侧补齐(长度8,字符'0'):{d.code:padl(8, '0')}
+```
+
+**渲染结果**:
+```
+左侧补齐(长度8,字符'0'):00000abc
+```
+
+**说明**:若 `targetLength` 小于原字符串长度,则直接返回原字符串;默认补齐字符为空格。
+
+---
+
+### 13. padr( targetLength, padString )
+
+**语法**:
+```
+{d.someField:padr(targetLength, padString)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "code": "abc"
+}
+```
+
+**模板内容**:
+```
+右侧补齐(长度10,字符'#'):{d.code:padr(10, '#')}
+```
+
+**渲染结果**:
+```
+右侧补齐(长度10,字符'#'):abc#######
+```
+
+**说明**:与 `padl` 相反,在字符串末尾进行补齐。默认补齐字符为空格。
+
+---
+
+### 14. ellipsis( maximum )
+
+**语法**:
+```
+{d.someField:ellipsis(maximum)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "articleTitle": "Carbone Report Extended Version"
+}
+```
+
+**模板内容**:
+```
+文章标题(最多5字符):{d.articleTitle:ellipsis(5)}
+```
+
+**渲染结果**:
+```
+文章标题(最多5字符):Carbo...
+```
+
+**说明**:当字符串长度超过 `maximum` 时,会在截断后加上 `...`。
+
+---
+
+### 15. prepend( textToPrepend )
+
+**语法**:
+```
+{d.someField:prepend(textToPrepend)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "username": "john"
+}
+```
+
+**模板内容**:
+```
+用户名:{d.username:prepend('Mr. ')}
+```
+
+**渲染结果**:
+```
+用户名:Mr. john
+```
+
+**说明**:在原有字符串前追加指定文本,常用于加前缀。
+
+---
+
+### 16. append( textToAppend )
+
+**语法**:
+```
+{d.someField:append(textToAppend)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "filename": "document"
+}
+```
+
+**模板内容**:
+```
+文件名:{d.filename:append('.pdf')}
+```
+
+**渲染结果**:
+```
+文件名:document.pdf
+```
+
+**说明**:在原有字符串后追加指定文本,常用于加后缀。
+
+---
+
+### 17. replace( oldText, newText )
+
+**语法**:
+```
+{d.someField:replace(oldText, newText)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "sentence": "abcdef abcde"
+}
+```
+
+**模板内容**:
+```
+替换结果:{d.sentence:replace('cd', 'OK')}
+```
+
+**渲染结果**:
+```
+替换结果:abOKef abOKe
+```
+
+**说明**:将所有符合 `oldText` 的部分替换为 `newText`;如果未指定 `newText` 或为 `null`,则删除匹配部分。
+
+---
+
+### 18. len( )
+
+**语法**:
+```
+{d.someField:len()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "greeting": "Hello World",
+ "numbers": [1, 2, 3, 4, 5]
+}
+```
+
+**模板内容**:
+```
+文本长度:{d.greeting:len()}
+数组长度:{d.numbers:len()}
+```
+
+**渲染结果**:
+```
+文本长度:11
+数组长度:5
+```
+
+**说明**:可用于字符串和数组,返回其长度或元素个数。
+
+---
+
+### 19. t( )
+
+**语法**:
+```
+{d.someField:t()}
+```
+
+**示例**:
+
+假设你在 Carbone 配置中定义了翻译字典,将文本 `"Submit"` 翻译为 `"提交"`。
+
+**数据集**:
+```json
+{
+ "buttonLabel": "Submit"
+}
+```
+
+**模板内容**:
+```
+按钮:{d.buttonLabel:t()}
+```
+
+**渲染结果**:
+```
+按钮:提交
+```
+
+**说明**:根据翻译词典对字符串进行翻译。需要在渲染时提供对应的翻译映射。
+
+---
+
+### 20. preserveCharRef( )
+
+**语法**:
+```
+{d.someField:preserveCharRef()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "legalSymbol": "§"
+}
+```
+
+**模板内容**:
+```
+符号:{d.legalSymbol:preserveCharRef()}
+```
+
+**渲染结果**:
+```
+符号:§
+```
+
+**说明**:保留 `&#xxx;` 或 `&#xXXXX;` 形式的字符引用,避免在 XML 中被转义或替换。这在生成特定字符集或特殊符号时非常有用。
+
+---
+以下示例均遵循前文的文档风格进行编写,帮助你更好地理解和运用与**数字操作**相关的格式化器。示例中会包含**语法**、**示例**(含“数据集”“模板内容”“渲染结果”)和简要的**说明**,有些示例还会提及可选的渲染配置(`options`)以展示如何影响输出。
+
+---
+
+
+## 数字操作格式化器示例
+
+### 1. convCurr( target, source )
+
+**语法**:
+```
+{d.numberField:convCurr(target, source)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "amount": 1000
+}
+```
+
+> 假设在 `Carbone.render(data, options)` 时,`options` 设置如下:
+> ```json
+> {
+> "currency": {
+> "source": "EUR",
+> "target": "USD",
+> "rates": {
+> "EUR": 1,
+> "USD": 2
+> }
+> }
+> }
+> ```
+
+**模板内容**:
+```
+默认从 EUR 转换到 USD:{d.amount:convCurr()}
+直接指定目标为 USD:{d.amount:convCurr('USD')}
+直接指定目标为 EUR:{d.amount:convCurr('EUR')}
+EUR->USD,再强制 USD->USD:{d.amount:convCurr('USD','USD')}
+```
+
+**渲染结果**:
+```
+默认从 EUR 转换到 USD:2000
+直接指定目标为 USD:2000
+直接指定目标为 EUR:1000
+EUR->USD,再强制 USD->USD:1000
+```
+
+**说明**:
+- 若未指定 `target`,则默认使用 `options.currencyTarget`(示例中的 "USD")。
+- 若未指定 `source`,则默认使用 `options.currencySource`(示例中的 "EUR")。
+- 若 `options.currencySource` 未定义,则不进行任何转换,原值输出。
+
+---
+
+### 2. round( precision )
+
+**语法**:
+```
+{d.numberField:round(precision)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "price": 10.05123,
+ "discount": 1.05
+}
+```
+
+**模板内容**:
+```
+价格保留2位小数:{d.price:round(2)}
+折扣保留1位小数:{d.discount:round(1)}
+```
+
+**渲染结果**:
+```
+价格保留2位小数:10.05
+折扣保留1位小数:1.1
+```
+
+**说明**:
+与 `toFixed()` 不同,`round()` 使用正确的四舍五入方式处理小数,如 `1.05` 保留一位小数时得到 `1.1`。
+
+---
+
+### 3. formatN( precision )
+
+**语法**:
+```
+{d.numberField:formatN(precision)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "total": 1000.456
+}
+```
+
+> 假设在 `Carbone.render(data, options)` 时,`options.lang` 为 `en-us`,且文档类型为非 ODS/XLSX(如 DOCX、PDF 等)。
+
+**模板内容**:
+```
+数字格式化:{d.total:formatN()}
+数字格式化(保留2位小数):{d.total:formatN(2)}
+```
+
+**渲染结果**:
+```
+数字格式化:1,000.456
+数字格式化(保留2位小数):1,000.46
+```
+
+**说明**:
+- `formatN()` 会根据 `options.lang` 设置对数字进行本地化显示(千分位、使用小数点或逗号等)。
+- 如果是 ODS/XLSX 文件,数值精度主要取决于表格自身的单元格格式设置。
+
+---
+
+### 4. formatC( precisionOrFormat, targetCurrencyCode )
+
+**语法**:
+```
+{d.numberField:formatC(precisionOrFormat, targetCurrencyCode)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "amount": 1000.456
+}
+```
+
+> 假设在 `Carbone.render(data, options)` 时,配置如下:
+> ```json
+> {
+> "lang": "en-us",
+> "currency": {
+> "source": "EUR",
+> "target": "USD",
+> "rates": {
+> "EUR": 1,
+> "USD": 2
+> }
+> }
+> }
+> ```
+
+**模板内容**:
+```
+默认转换并输出货币符号:{d.amount:formatC()}
+只输出货币名称(M):{d.amount:formatC('M')}
+只输出货币名称,单数情况:{1:formatC('M')}
+数字+符号(L):{d.amount:formatC('L')}
+数字+货币名称(LL):{d.amount:formatC('LL')}
+```
+
+**渲染结果**:
+```
+默认转换并输出货币符号:$2,000.91
+只输出货币名称(M):dollars
+只输出货币名称,单数情况:dollar
+数字+符号(L):$2,000.00
+数字+货币名称(LL):2,000.00 dollars
+```
+
+**说明**:
+- `precisionOrFormat` 可以是数字(指定小数位)或字符串("M"、"L"、"LL")。
+- 若还需切换到其他货币,可传入 `targetCurrencyCode`,如 `formatC('L', 'EUR')`。
+
+---
+
+### 5. add( )
+
+**语法**:
+```
+{d.numberField:add(value)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**模板内容**:
+```
+数值加2:{d.base:add(2)}
+```
+
+**渲染结果**:
+```
+数值加2:1002.4
+```
+
+**说明**:将 `d.base` 与传入参数相加,支持字符串数字或纯数字。
+
+---
+
+### 6. sub( )
+
+**语法**:
+```
+{d.numberField:sub(value)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**模板内容**:
+```
+数值减2:{d.base:sub(2)}
+```
+
+**渲染结果**:
+```
+数值减2:998.4
+```
+
+**说明**:将 `d.base` 与传入参数相减。
+
+---
+
+### 7. mul( )
+
+**语法**:
+```
+{d.numberField:mul(value)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**模板内容**:
+```
+数值乘2:{d.base:mul(2)}
+```
+
+**渲染结果**:
+```
+数值乘2:2000.8
+```
+
+**说明**:将 `d.base` 与传入参数相乘。
+
+---
+
+### 8. div( )
+
+**语法**:
+```
+{d.numberField:div(value)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "base": 1000.4
+}
+```
+
+**模板内容**:
+```
+数值除以2:{d.base:div(2)}
+```
+
+**渲染结果**:
+```
+数值除以2:500.2
+```
+
+**说明**:将 `d.base` 与传入参数相除。
+
+---
+
+### 9. mod( value )
+
+**语法**:
+```
+{d.numberField:mod(value)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "num1": 4,
+ "num2": 3
+}
+```
+
+**模板内容**:
+```
+4 mod 2:{d.num1:mod(2)}
+3 mod 2:{d.num2:mod(2)}
+```
+
+**渲染结果**:
+```
+4 mod 2:0
+3 mod 2:1
+```
+
+**说明**:计算 `num1 % 2` 和 `num2 % 2` 的结果,用于求余操作。
+
+---
+
+### 10. abs( )
+
+**语法**:
+```
+{d.numberField:abs()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "value1": -10,
+ "value2": -10.54
+}
+```
+
+**模板内容**:
+```
+绝对值1:{d.value1:abs()}
+绝对值2:{d.value2:abs()}
+```
+
+**渲染结果**:
+```
+绝对值1:10
+绝对值2:10.54
+```
+
+**说明**:返回数字的绝对值,若是字符串形式的负数亦可处理。
+
+---
+
+### 11. ceil( )
+
+**语法**:
+```
+{d.numberField:ceil()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "dataA": 10.05123,
+ "dataB": 1.05,
+ "dataC": -1.05
+}
+```
+
+**模板内容**:
+```
+ceil(10.05123):{d.dataA:ceil()}
+ceil(1.05):{d.dataB:ceil()}
+ceil(-1.05):{d.dataC:ceil()}
+```
+
+**渲染结果**:
+```
+ceil(10.05123):11
+ceil(1.05):2
+ceil(-1.05):-1
+```
+
+**说明**:将数值向上取整到最近的更大(或相等)整数。
+
+---
+
+### 12. floor( )
+
+**语法**:
+```
+{d.numberField:floor()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "dataA": 10.05123,
+ "dataB": 1.05,
+ "dataC": -1.05
+}
+```
+
+**模板内容**:
+```
+floor(10.05123):{d.dataA:floor()}
+floor(1.05):{d.dataB:floor()}
+floor(-1.05):{d.dataC:floor()}
+```
+
+**渲染结果**:
+```
+floor(10.05123):10
+floor(1.05):1
+floor(-1.05):-2
+```
+
+**说明**:将数值向下取整到最近的更小(或相等)整数。
+
+---
+
+### 13. int( )
+
+> **注意**:**不推荐使用**。
+> **语法**:
+```
+{d.numberField:int()}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "price": 12.34
+}
+```
+
+**模板内容**:
+```
+结果:{d.price:int()}
+```
+
+**渲染结果**:
+```
+结果:12
+```
+
+**说明**:将数值转为整数,直接去掉小数部分;官方文档建议使用更准确的 `round()` 或 `floor()`/`ceil()` 替代。
+
+---
+
+### 14. toEN( )
+
+> **注意**:**不推荐使用**。
+> **语法**:
+```
+{d.numberField:toEN()}
+```
+
+**说明**:把数字转为符合英文格式的小数点 `.` 分隔,不做本地化处理。通常建议使用 `formatN()` 以适配多语言场景。
+
+---
+
+### 15. toFixed( )
+
+> **注意**:**不推荐使用**。
+> **语法**:
+```
+{d.numberField:toFixed(decimalCount)}
+```
+
+**说明**:将数字转换为字符串并保留指定的小数位数,但可能存在不精确的四舍五入问题,建议改用 `round()` 或 `formatN()`。
+
+---
+
+### 16. toFR( )
+
+> **注意**:**不推荐使用**。
+> **语法**:
+```
+{d.numberField:toFR()}
+```
+
+**说明**:把数字转换为符合法语格式的小数点 `,` 分隔,但不做更多本地化处理。建议使用 `formatN()` 或 `formatC()` 以便在多语言和货币场景下更灵活。
+
+---
+
+## 数组操作(Array manipulation)
+
+### 1. aggStr( separator )
+> **版本**:ENTERPRISE FEATURE,NEWv4.17.0+
+> **功能**:将数组中的值合并为一个字符串,并用可选分隔符 `separator` 进行拼接。若不提供分隔符,默认为 `,`。
+
+**语法**:
+```
+{d.arrayField[].someAttr:aggStr(separator)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "cars": [
+ {"brand":"Tesla","qty":1,"sort":1},
+ {"brand":"Ford","qty":4,"sort":4},
+ {"brand":"Jeep","qty":3,"sort":3},
+ {"brand":"GMC","qty":2,"sort":2},
+ {"brand":"Rivian","qty":1,"sort":1},
+ {"brand":"Chevrolet","qty":10,"sort":5}
+ ]
+}
+```
+
+**模板内容**:
+```
+所有品牌(默认逗号分隔):
+{d.cars[].brand:aggStr}
+
+所有品牌(指定连字符分隔):
+{d.cars[].brand:aggStr(' - ')}
+
+筛选出 qty 大于 3 的品牌:
+{d.cars[.qty > 3].brand:aggStr()}
+```
+
+**渲染结果**:
+```
+所有品牌(默认逗号分隔):
+Tesla, Ford, Jeep, GMC, Rivian, Chevrolet
+
+所有品牌(指定连字符分隔):
+Tesla - Ford - Jeep - GMC - Rivian - Chevrolet
+
+筛选出 qty 大于 3 的品牌:
+Ford, Chevrolet
+```
+
+**说明**:
+- 使用 `:aggStr` 对数组中的字段进行提取与合并,可搭配过滤条件(如 `[.qty > 3]`)实现更灵活的输出。
+- `separator` 参数可省略,默认为逗号 + 空格(`, `)。
+
+---
+
+### 2. arrayJoin( separator, index, count )
+> **版本**:NEWv4.12.0+
+> **功能**:将数组元素(`String` 或 `Number`)合并为一个单一字符串;可选指定从数组中哪一段开始合并。
+
+**语法**:
+```
+{d.arrayField:arrayJoin(separator, index, count)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "names": ["homer", "bart", "lisa"],
+ "emptyArray": [],
+ "notArray": 20
+}
+```
+
+**模板内容**:
+```
+默认使用逗号分隔:{d.names:arrayJoin()}
+使用 " | " 分隔:{d.names:arrayJoin(' | ')}
+使用空字符分隔:{d.names:arrayJoin('')}
+仅合并第二项起后的所有:{d.names:arrayJoin('', 1)}
+仅合并第二项起1个元素:{d.names:arrayJoin('', 1, 1)}
+从第1项截取到倒数第1个元素:{d.names:arrayJoin('', 0, -1)}
+
+空数组:{d.emptyArray:arrayJoin()}
+非数组数据:{d.notArray:arrayJoin()}
+```
+
+**渲染结果**:
+```
+默认使用逗号分隔:homer, bart, lisa
+使用 " | " 分隔:homer | bart | lisa
+使用空字符分隔:homerbartlisa
+仅合并第二项起后的所有:bartlisa
+仅合并第二项起1个元素:bart
+从第1项截取到倒数第1个元素:homerbart
+
+空数组:
+非数组数据:20
+```
+
+**说明**:
+- `separator` 默认为逗号 + 空格(`, `)。
+- `index` 与 `count` 用于截取数组的部分元素;`count` 可为负数表示从结尾反向取元素。
+- 若非数组类型数据(`null`、`undefined`、对象或数字等),则会原样输出。
+
+---
+
+### 3. arrayMap( objSeparator, attributeSeparator, attributes )
+> **版本**:v0.12.5+
+> **功能**:将对象数组映射成字符串。可指定对象之间的分隔符、属性之间的分隔符以及需要输出的属性。
+
+**语法**:
+```
+{d.arrayField:arrayMap(objSeparator, attributeSeparator, attributes)}
+```
+
+**示例**:
+
+```json
+{
+ "people": [
+ { "id": 2, "name": "homer" },
+ { "id": 3, "name": "bart" }
+ ],
+ "numbers": [10, 50],
+ "emptyArray": [],
+ "mixed": {"id":2,"name":"homer"}
+}
+```
+
+**模板内容**:
+```
+默认映射(使用逗号+空格作为对象分隔,冒号作为属性分隔):
+{d.people:arrayMap()}
+
+对象间使用 " - " 分隔:
+{d.people:arrayMap(' - ')}
+
+对象属性使用 " | " 分隔:
+{d.people:arrayMap(' ; ', '|')}
+
+仅映射 id:
+{d.people:arrayMap(' ; ', '|', 'id')}
+
+数字数组:
+{d.numbers:arrayMap()}
+
+空数组:
+{d.emptyArray:arrayMap()}
+
+非数组数据:
+{d.mixed:arrayMap()}
+```
+
+**渲染结果**:
+```
+默认映射:
+2:homer, 3:bart
+
+对象间使用 " - " 分隔:
+2:homer - 3:bart
+
+对象属性使用 " | " 分隔:
+2|homer ; 3|bart
+
+仅映射 id:
+2 ; 3
+
+数字数组:
+10, 50
+
+空数组:
+
+非数组数据:
+{ "id": 2, "name": "homer" }
+```
+
+**说明**:
+- 如果是对象数组,默认输出其中**所有**可用的一级属性,以 `属性名:属性值` 的形式拼接起来。
+- `objSeparator` 用于分隔不同对象的输出,默认为逗号 + 空格;`attributeSeparator` 用于分隔属性,默认为冒号 `:`;`attributes` 则可指定仅输出对象中的部分属性。
+- 若传入的数据不是数组,则原样输出。
+
+---
+
+### 4. count( start )
+> **版本**:v1.1.0+
+> **功能**:在循环(如 `{d.array[i].xx}`)中打印**行号**或**序号**,默认为从 1 开始。
+> **注意**:从 v4.0.0 开始,该功能内部被替换为 `:cumCount`。
+
+**语法**:
+```
+{d.array[i].someField:count(start)}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "employees": [
+ { "name": "James" },
+ { "name": "Emily" },
+ { "name": "Michael" }
+ ]
+}
+```
+
+**模板内容**:
+```
+员工列表:
+序号 | 姓名
+{d.employees[i].name:count()}. {d.employees[i].name}
+{d.employees[i+1]}
+```
+
+**渲染结果**:
+```
+员工列表:
+序号 | 姓名
+1. James
+2. Emily
+3. Michael
+```
+
+**说明**:
+- 仅在循环(包括 `{d.array[i].xx}` 等场景)有效,用于打印当前行索引的计数。
+- `start` 可指定从某个数开始计数,如 `:count(5)` 则首行从 5 开始计数。
+- Carbone 4.0+ 建议使用 `:cumCount`,功能更灵活。
+
+---
+
+# 条件输出(Conditioned output)
+
+Carbone 提供了一系列条件输出的格式化器,用于在模板中根据特定条件**隐藏**或**显示**指定内容。可根据业务需求选择**`drop`/`keep`**(简洁用法)或者**`showBegin`/`showEnd`**、**`hideBegin`/`hideEnd`**(适用于大段内容)等。
+
+### 1. drop(element)
+> **版本**:ENTERPRISE FEATURE,UPDATEDv4.22.10+
+> **功能**:若条件为真,则**删除**文档中的某个元素或若干元素,如段落、表格行、图片、图表等。
+
+**语法**:
+```
+{d.data:ifEM():drop(element, nbrToDrop)}
+```
+- `element`:可为 `p`(段落)、`row`(表格行)、`img`(图片)、`table`(整张表格)、`chart`(图表)、`shape`(形状)、`slide`(幻灯片,仅限 ODP)或 `item`(列表项,仅限 ODP/ODT)。
+- `nbrToDrop`:可选,整数,表示删除当前及后续多少个元素。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "imgUrl": null
+}
+```
+
+**模板内容**(DOCX 场景,简化示例):
+```
+这里有一张图片:{d.imgUrl:ifEM:drop(img)}
+```
+
+- 在 Word 模板中,将此占位符置于图片的标题或说明里。
+
+**渲染结果**:
+```
+这里有一张图片:
+```
+> 图片被删除,因 `imgUrl` 为空 (`ifEM` 为真)。
+
+**说明**:
+- 若 `ifEM` 条件成立,则执行 `drop(img)`,删除该图片及其所在段落内容。
+- `drop` 仅支持 DOCX/ODT/ODS/ODP/PPTX/PDF/HTML;且一旦执行 `drop`,后续不再执行其他格式化器。
+
+---
+
+### 2. keep(element)
+> **版本**:ENTERPRISE FEATURE,NEWv4.17.0+
+> **功能**:若条件为真,则**保留/显示**文档中的某个元素或若干元素,其余情况则不显示。
+
+**语法**:
+```
+{d.data:ifNEM:keep(element, nbrToKeep)}
+```
+- `element`:同 `drop` 一样,可为 `p`、`row`、`img`、`table`、`chart`、`shape`、`slide`、`item` 等。
+- `nbrToKeep`:可选,整数,表示保留当前及后续多少个元素。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "tableData": []
+}
+```
+
+**模板内容**(DOCX 场景,简化示例):
+```
+{d.tableData:ifNEM:keep(table)}
+```
+
+- 在 Word 模板中,将此占位符置于表格中某个单元格内。
+
+**渲染结果**:
+```
+(空白)
+```
+> 由于 `tableData` 为空,`ifNEM` 为假(not empty 失败),因此表格未被保留,整张表被删除。
+
+**说明**:
+- 若条件成立,则保留对应元素;否则删除该元素及其所有内容。
+- 和 `drop` 相反,`keep` 在条件不满足时删除元素。
+
+---
+
+### 3. showBegin()/showEnd()
+> **版本**:COMMUNITY FEATURE,v2.0.0+
+> **功能**:显示 `showBegin` 与 `showEnd` 之间的内容(可包含多段文本、表格、图片等),若条件为真则保留此部分,若条件为假则删除。
+
+**语法**:
+```
+{d.someData:ifEQ(someValue):showBegin}
+...显示的内容...
+{d.someData:showEnd}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "toBuy": true
+}
+```
+
+**模板内容**:
+```
+Banana{d.toBuy:ifEQ(true):showBegin}
+Apple
+Pineapple
+{d.toBuy:showEnd}grapes
+```
+
+**渲染结果**:
+```
+Banana
+Apple
+Pineapple
+grapes
+```
+> 当 `toBuy` 为 `true` 时,`showBegin` 和 `showEnd` 之间的所有内容都会展示。
+
+**说明**:
+- 适用于**多行或多页**内容的隐藏和展示;如果仅是一行,可考虑使用 `keep`/`drop` 获得更简洁的写法。
+- 推荐在 `showBegin` 与 `showEnd` 中仅使用**换行(Shift+Enter)**分隔,以确保渲染正常。
+
+---
+
+### 4. hideBegin()/hideEnd()
+> **版本**:COMMUNITY FEATURE,v2.0.0+
+> **功能**:隐藏 `hideBegin` 与 `hideEnd` 之间的内容,若条件为真则删除这部分内容,否则保留。
+
+**语法**:
+```
+{d.someData:ifEQ(someValue):hideBegin}
+...隐藏的内容...
+{d.someData:hideEnd}
+```
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "toBuy": true
+}
+```
+
+**模板内容**:
+```
+Banana{d.toBuy:ifEQ(true):hideBegin}
+Apple
+Pineapple
+{d.toBuy:hideEnd}grapes
+```
+
+**渲染结果**:
+```
+Banana
+grapes
+```
+> 当 `toBuy` 为 `true`,`hideBegin` 与 `hideEnd` 内的 Apple、Pineapple 内容被隐藏。
+
+**说明**:
+- 与 `showBegin()/showEnd()` 相对,用于隐藏多段文本、表格、图片等。
+- 同样建议仅在 `hideBegin` 与 `hideEnd` 中使用**换行(Shift+Enter)**分隔。
+
+---
+
+## 日期与时间操作格式化器示例
+
+> **注意**:自 v3.0.0 开始,Carbone 使用 [Day.js](https://day.js.org/docs/en/display/format) 进行日期处理。大多数和 Moment.js 相关的格式在 Day.js 中仍可用,但底层库已替换为 Day.js。
+
+### 1. {c.now} 的使用
+
+在模板中可以使用 `{c.now}` 获取当前 UTC 时间(`now`),前提是渲染时没有通过 `options.complement` 传入自定义数据覆盖它。示例如下:
+
+**数据集**(可为空或不含 `c` 字段):
+```json
+{}
+```
+
+**模板内容**:
+```
+当前时间:{c.now:formatD('YYYY-MM-DD HH:mm:ss')}
+```
+
+**渲染结果**(示例):
+```
+当前时间:2025-01-07 10:05:30
+```
+
+**说明**:
+- `{c.now}` 是一个保留标签,会自动插入系统当前 UTC 时间。
+- 配合 `:formatD()` 等格式化器输出指定格式。
+
+---
+
+### 2. formatD( patternOut, patternIn )
+
+**语法**:
+```
+{d.dateField:formatD(patternOut, patternIn)}
+```
+
+- `patternOut`:输出的日期格式,符合 Day.js 格式规范或本地化格式(如 `L`, `LL`, `LLLL` 等)。
+- `patternIn`:输入日期格式,默认为 ISO 8601,可指定如 `YYYYMMDD`、`X`(Unix 时间戳)等。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "eventDate": "20160131"
+}
+```
+
+> 假设在 `Carbone.render(data, options)` 时,设置:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**模板内容**:
+```
+日期(短格式):{d.eventDate:formatD('L')}
+日期(完整英文):{d.eventDate:formatD('LLLL')}
+星期几:{d.eventDate:formatD('dddd')}
+```
+
+**渲染结果**:
+```
+日期(短格式):01/31/2016
+日期(完整英文):Sunday, January 31, 2016 12:00 AM
+星期几:Sunday
+```
+
+**说明**:
+- `patternIn` 若不指定,默认为 ISO 8601,但这里传入的 `20160131` 也能被自动识别。若想显式指定,则用 `{d.eventDate:formatD('L', 'YYYYMMDD')}` 等。
+- `options.lang` 和 `options.timezone` 会影响输出语言及时区转换。
+
+---
+
+### 3. formatI( patternOut, patternIn )
+
+**语法**:
+```
+{d.durationField:formatI(patternOut, patternIn)}
+```
+
+- `patternOut`:输出格式,可为 `human`, `human+`, `milliseconds/ms`, `seconds/s`, `minutes/m`, `hours/h`, `days/d`, `weeks/w`, `months/M`, `years/y` 等。
+- `patternIn`:可选,输入单位默认为毫秒,也可指定 `seconds`, `minutes`, `hours`, `days` 等。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "intervalMs": 2000,
+ "longIntervalMs": 3600000
+}
+```
+
+> 假设在 `Carbone.render(data, options)` 时:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**模板内容**:
+```
+2000 毫秒转秒:{d.intervalMs:formatI('second')}
+3600000 毫秒转分钟:{d.longIntervalMs:formatI('minute')}
+3600000 毫秒转小时:{d.longIntervalMs:formatI('hour')}
+```
+
+**渲染结果**:
+```
+2000 毫秒转秒:2
+3600000 毫秒转分钟:60
+3600000 毫秒转小时:1
+```
+
+**说明**:
+- 对时间间隔进行单位换算,也可输出人性化时间(如 `human`/`human+`)来显示“几秒前”或“几分钟后”。
+- 对正负值处理时,`human+` 会输出“...ago” 或 “in a few ...”,而 `human` 只输出“a few seconds”等不带方向的表达。
+
+---
+
+### 4. addD( amount, unit, patternIn )
+
+**语法**:
+```
+{d.dateField:addD(amount, unit, patternIn)}
+```
+
+- `amount`:数值或字符串,表示要添加的数量。
+- `unit`:可用 `day`、`week`、`month`、`year`、`hour`、`minute`、`second`、`millisecond` 等(不区分大小写,且支持复数与缩写)。
+- `patternIn`:可选,指定输入日期格式,默认为 ISO8601。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "startDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+> 假设在 `Carbone.render(data, options)` 时:
+> ```json
+> {
+> "lang": "fr",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**模板内容**:
+```
+在 startDate 上加 3 天:{d.startDate:addD('3', 'day')}
+在 startDate 上加 3 个月:{d.startDate:addD('3', 'month')}
+```
+
+**渲染结果**:
+```
+在 startDate 上加 3 天:2017-05-13T12:57:23.769Z
+在 startDate 上加 3 个月:2017-08-10T12:57:23.769Z
+```
+
+**说明**:
+- 结果会在 UTC 时间下显示,若要本地化输出可再配合 `formatD('YYYY-MM-DD HH:mm')` 等格式化器。
+- 如果输入日期为类似 `20160131` 并未显式指定 `patternIn`,Day.js 也可能自动识别,但最好用 `{d.field:addD('...', '...', 'YYYYMMDD')}` 以确保准确。
+
+---
+
+### 5. subD( amount, unit, patternIn )
+
+**语法**:
+```
+{d.dateField:subD(amount, unit, patternIn)}
+```
+
+- 用法和 `addD()` 类似,只是把时间往前推。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "myDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**模板内容**:
+```
+在 myDate 上减 3 天:{d.myDate:subD('3', 'day')}
+在 myDate 上减 3 个月:{d.myDate:subD('3', 'month')}
+```
+
+**渲染结果**:
+```
+在 myDate 上减 3 天:2017-05-07T12:57:23.769Z
+在 myDate 上减 3 个月:2017-02-10T12:57:23.769Z
+```
+
+**说明**:
+- 与 `addD` 相反,`subD` 会向过去方向移动日期。
+- 支持相同的单位和格式配置。
+
+---
+
+### 6. startOfD( unit, patternIn )
+
+**语法**:
+```
+{d.dateField:startOfD(unit, patternIn)}
+```
+
+- `unit`:`day`、`month`、`year`、`week` 等,将日期设为该单位的开始时间(如 `day`=凌晨,`month`=1号 00:00:00 等)。
+- `patternIn`:可选,指定输入日期格式。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "someDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**模板内容**:
+```
+把 someDate 设为当天开始:{d.someDate:startOfD('day')}
+把 someDate 设为当月开始:{d.someDate:startOfD('month')}
+```
+
+**渲染结果**:
+```
+把 someDate 设为当天开始:2017-05-10T00:00:00.000Z
+把 someDate 设为当月开始:2017-05-01T00:00:00.000Z
+```
+
+**说明**:
+- 常用于报表统计、对齐到某个时间粒度等场景。
+
+---
+
+### 7. endOfD( unit, patternIn )
+
+**语法**:
+```
+{d.dateField:endOfD(unit, patternIn)}
+```
+
+- `unit`:`day`、`month`、`year` 等,将日期设为该单位的末尾时间(如 `day`=23:59:59.999,`month`=最后一天 23:59:59.999 等)。
+- `patternIn`:可选,指定输入日期格式。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "someDate": "2017-05-10T15:57:23.769561+03:00"
+}
+```
+
+**模板内容**:
+```
+把 someDate 设为当天结束:{d.someDate:endOfD('day')}
+把 someDate 设为当月结束:{d.someDate:endOfD('month')}
+```
+
+**渲染结果**:
+```
+把 someDate 设为当天结束:2017-05-10T23:59:59.999Z
+把 someDate 设为当月结束:2017-05-31T23:59:59.999Z
+```
+
+**说明**:
+- 与 `startOfD` 相对应,将日期“推到”当天、当月、当年的最末时刻。
+
+---
+
+### 8. diffD( toDate, unit, patternFromDate, patternToDate )
+
+**语法**:
+```
+{d.fromDate:diffD(toDate, unit, patternFromDate, patternToDate)}
+```
+
+- `toDate`:对比的目标日期,可为字符串或数字(Unix 时间戳)。
+- `unit`:可选,支持 `day/d`, `week/w`, `month/M`, `year/y`, `hour/h`, `minute/m`, `second/s`, `millisecond/ms`,默认为毫秒。
+- `patternFromDate` / `patternToDate`:可选,指定输入日期的格式。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "start": "20101001"
+}
+```
+**模板内容**:
+```
+默认毫秒间隔:{d.start:diffD('20101201')}
+以秒为单位:{d.start:diffD('20101201', 'second')}
+以天为单位:{d.start:diffD('20101201', 'days')}
+```
+
+**渲染结果**:
+```
+默认毫秒间隔:5270400000
+以秒为单位:5270400
+以天为单位:61
+```
+
+**说明**:
+- 若原始日期格式与目标日期格式不同时,可通过 `patternFromDate` 和 `patternToDate` 分别指定。
+- 差值为正表示 `toDate` 比 `fromDate` 晚或大;为负表示 `toDate` 比 `fromDate` 早或小。
+
+---
+
+### 9. convDate( patternIn, patternOut )
+
+> **注意**:**不推荐使用**
+> 自 v3.0.0 开始,官方更推荐使用 `formatD(patternOut, patternIn)`,它提供了更灵活的功能和与 Day.js 更好的兼容性。
+
+**语法**:
+```
+{d.dateField:convDate(patternIn, patternOut)}
+```
+
+- `patternIn`:输入日期格式。
+- `patternOut`:输出日期格式。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "myDate": "20160131"
+}
+```
+
+> 假设在 `Carbone.render(data, options)` 时:
+> ```json
+> {
+> "lang": "en",
+> "timezone": "Europe/Paris"
+> }
+> ```
+
+**模板内容**:
+```
+简短日期:{d.myDate:convDate('YYYYMMDD', 'L')}
+完整日期:{d.myDate:convDate('YYYYMMDD', 'LLLL')}
+```
+
+**渲染结果**:
+```
+简短日期:01/31/2016
+完整日期:Sunday, January 31, 2016 12:00 AM
+```
+
+**说明**:
+- 与 `formatD` 用法相似,但已标为 **不推荐**(UNRECOMMENDED)。
+- 建议在新项目中统一使用 `formatD`。
+
+---
+
+### Day.js 日期格式速查表
+
+在 `patternOut` 中可使用以下常用格式(部分例子):
+
+| 格式 | 示例输出 | 描述 |
+|:---- |:------------------------ |:------------------------------------------------ |
+| `X` | `1360013296` | Unix 时间戳(单位:秒) |
+| `x` | `1360013296123` | Unix 毫秒时间戳 |
+| `YYYY`| `2025` | 四位数年份 |
+| `MM` | `01-12` | 两位数月份 |
+| `DD` | `01-31` | 两位数日期 |
+| `HH` | `00-23` | 24 小时制小时数,两位数 |
+| `mm` | `00-59` | 分钟(两位数) |
+| `ss` | `00-59` | 秒(两位数) |
+| `dddd`| `Sunday-Saturday` | 星期的全称 |
+| `ddd` | `Sun-Sat` | 星期的缩写 |
+| `A` | `AM` / `PM` | 上下午(大写) |
+| `a` | `am` / `pm` | 上下午(小写) |
+| `L` | `MM/DD/YYYY` | 本地化短日期格式 |
+| `LL` | `MMMM D, YYYY` | 本地化日期,带月份全称 |
+| `LLL` | `MMMM D, YYYY h:mm A` | 带时间、月份全称的本地化日期 |
+| `LLLL`| `dddd, MMMM D, YYYY h:mm A` | 带周几的完整本地化日期 |
+
+更多格式可参考 [Day.js 官方文档](https://day.js.org/docs/en/display/format) 或上文列出的清单。
+
+---
+
+
+
+
+
+
+## 其他条件控制器
+
+Carbone 提供了许多**判断**(`ifEQ`、`ifNE`、`ifGT`、`ifGTE`、`ifLT`、`ifLTE`、`ifIN`、`ifNIN`、`ifEM`、`ifNEM`、`ifTE` 等),以及**组合逻辑**(`and()`、`or()`)和**分支输出**(`show(message)`、`elseShow(message)`)等。它们可以搭配用于在模板中实现灵活的条件逻辑。以下仅列出常用的示例,更多可参见官方文档:
+
+- **ifEM()**:判断是否为空(`null`、`undefined`、`[]`、`{}`、`""` 等)。
+- **ifNEM()**:判断是否不为空。
+- **ifEQ(value)** / **ifNE(value)** / **ifGT(value)** / **ifGTE(value)** / **ifLT(value)** / **ifLTE(value)**:常规比较运算。
+- **ifIN(value)** / **ifNIN(value)**:判断字符串或数组中是否包含指定内容。
+- **ifTE(type)**:判断数据的类型(string、number、array、object、boolean、binary 等)。
+- **and(value)** / **or(value)**:改变默认的条件连接方式。
+- **show(message)** / **elseShow(message)**:在条件为真或假时,输出对应的消息字符串。
+
+**示例**:
+
+**数据集**:
+```json
+{
+ "status1": 1,
+ "status2": 2,
+ "status3": 3
+}
+```
+
+**模板内容**:
+```
+one = { d.status1:ifEQ(2):show(two):or(.status1):ifEQ(1):show(one):elseShow(unknown) }
+
+two = { d.status2:ifEQ(2):show(two):or(.status2):ifEQ(1):show(one):elseShow(unknown) }
+
+three = { d.status3:ifEQ(2):show(two):or(.status3):ifEQ(1):show(one):elseShow(unknown) }
+```
+
+**渲染结果**:
+```
+one = "one"
+two = "two"
+three = "unknown"
+```
+
+**说明**:
+- `:ifEQ(2):show(two)` 表示若值等于2,则输出 "two";否则继续下一个判断(`or(.status1):ifEQ(1):show(one)`)。
+- `or()` 和 `and()` 用于配置逻辑操作符。
+- `elseShow('unknown')` 用于在所有前置条件均不成立时,输出 "unknown"。
+
+---
+通过**数组操作**和**条件输出**示例,你可以:
+1. **灵活处理数组**:使用 `:aggStr`、`:arrayJoin`、`:arrayMap`、`:count` 等操作,实现**合并、拼接、映射**以及**计数**功能。
+2. **精准控制内容展示**:通过 `drop` / `keep` 或 `showBegin` / `showEnd` / `hideBegin` / `hideEnd` 等方式,根据条件(`ifEQ`、`ifGT` 等)决定是否保留文档中**特定元素**或**大段内容**。
+3. **组合多种判断**:与数字、字符串相关的格式化器(如 `ifNEM`、`ifIN` 等)相配合,可实现更为复杂的业务逻辑控制。
+---
+
+以下示例延续前文的文档风格,展示了 **日期与时间操作** 相关的格式化器使用方法。为了更好地理解每个格式化器的用途,示例中包含了**语法**、**示例**(含“数据集”“模板内容”和“渲染结果”)以及必要的**说明**。某些格式化器可以配合渲染配置(`options`)中的时区(`timezone`)、语言(`lang`)等选项共同使用,从而实现更灵活的日期时间处理。
+
+---
+
+## 常见问题与解决方案
+
+### 1. Excel 模板中的空列和空单元格在渲染结果中消失
+
+**问题描述**:在 Excel 模板中,如果某个单元格没有内容或样式,渲染时可能会被去除,导致最终文档中缺失该单元格。
+
+**解决方法**:
+
+- **填充背景色**:为目标区域的空单元格填充背景色,确保单元格在渲染过程中保持可见。
+- **插入空格**:在空单元格内插入一个空格字符,即使没有实际内容,也能保持单元格的结构。
+- **设置边框**:为表格添加边框样式,增强单元格的边界感,避免渲染时单元格消失。
+
+**示例**:
+
+在 Excel 模板中,为所有目标单元格设置浅灰色背景,并在空单元格中插入空格。
+
+### 2. 合并单元格在输出时无效
+
+**问题描述**:在使用循环功能输出表格时,如果模板中存在合并单元格,可能会导致渲染结果异常,如合并效果丢失或数据错位。
+
+**解决方法**:
+
+- **避免使用合并单元格**:尽量避免在循环输出的表格中使用合并单元格,以确保数据的正确渲染。
+- **使用跨列居中**:如果需要文本在多个单元格中横向居中,可以使用“跨列居中”功能,而不是合并单元格。
+- **限制合并单元格的位置**:若必须使用合并单元格,请仅在表格的上方或右侧进行合并,避免在下方或左侧合并,以防渲染时合并效果丢失。
+
+**示例**:
+
+**错误示范**:
+
+| 姓名 | 部门 | 职位 |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*如果在“部门”列合并单元格,可能导致渲染异常。*
+
+**正确示范**:
+
+| 姓名 | 部门 | 职位 |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
+
+*保持每个单元格独立,避免合并单元格。*
+
+### 3. 模板渲染时出现错误提示
+
+**问题描述**:在模板渲染过程中,系统弹出错误提示,导致渲染失败。
+
+**可能原因**:
+
+- **占位符错误**:占位符名称与数据集字段不匹配或语法错误。
+- **数据缺失**:数据集中缺少模板中引用的字段。
+- **格式化器使用不当**:格式化器参数错误或不支持的格式化类型。
+
+**解决方法**:
+
+- **检查占位符**:确保模板中的占位符名称与数据集中的字段名称一致,且语法正确。
+- **验证数据集**:确认数据集中包含所有模板中引用的字段,且数据格式符合要求。
+- **调整格式化器**:检查格式化器的使用方法,确保参数正确,并使用支持的格式化类型。
+
+**示例**:
+
+**错误模板**:
+```
+订单编号:{d.orderId}
+订单日期:{d.orderDate:format('YYYY/MM/DD')}
+总金额:{d.totalAmount:format('0.00')}
+```
+
+**数据集**:
+```json
+{
+ "orderId": "A123456789",
+ "orderDate": "2025-01-01T10:00:00Z"
+ // 缺少 totalAmount 字段
+}
+```
+
+**解决方法**:在数据集中添加 `totalAmount` 字段,或从模板中移除对 `totalAmount` 的引用。
+
+### 4. 模板文件上传失败
+
+**问题描述**:在模板配置页面上传模板文件时,出现上传失败的情况。
+
+**可能原因**:
+
+- **文件格式不支持**:上传的文件格式不在支持范围内(仅支持 `.docx`、`.xlsx`、`.pptx`)。
+- **文件大小过大**:模板文件过大,超过系统允许的上传大小限制。
+- **网络问题**:网络连接不稳定,导致上传中断或失败。
+
+**解决方法**:
+
+- **检查文件格式**:确保上传的模板文件为 `.docx`、`.xlsx` 或 `.pptx` 格式。
+- **压缩文件大小**:如果文件过大,尝试压缩模板文件或优化模板内容,减少文件大小。
+- **稳定网络连接**:确保网络连接稳定,再次尝试上传操作。
+
+
+
+## 总结
+
+模板打印插件提供了强大的功能,支持多种文件格式的模板编辑与动态数据填充。通过合理配置和使用丰富的模板语法,可以高效地生成各类定制化文档,满足不同业务需求,提升工作效率和文档质量。
+
+**关键优势**:
+
+- **高效性**:自动化数据填充,减少手动操作,提高工作效率。
+- **灵活性**:支持多种模板格式和复杂的数据结构,适应多样化的文档需求。
+- **专业性**:格式化器和条件输出等功能,提升文档的专业度和可读性。
+
+## 常见问题
+
+### 1. Excel 模板中的空列和空单元格在渲染结果中消失
+
+**问题描述**:在 Excel 模板中,如果某个单元格没有内容或样式,渲染时可能会被去除,导致最终文档中缺失该单元格。
+
+**解决方法**:
+
+- **填充背景色**:为目标区域的空单元格填充背景色,确保单元格在渲染过程中保持可见。
+- **插入空格**:在空单元格内插入一个空格字符,即使没有实际内容,也能保持单元格的结构。
+- **设置边框**:为表格添加边框样式,增强单元格的边界感,避免渲染时单元格消失。
+
+**示例**:
+
+在 Excel 模板中,为所有目标单元格设置浅灰色背景,并在空单元格中插入空格。
+
+### 2. 合并单元格在输出时无效
+
+**问题描述**:在使用循环功能输出表格时,如果模板中存在合并单元格,可能会导致渲染结果异常,如合并效果丢失或数据错位。
+
+**解决方法**:
+
+- **避免使用合并单元格**:尽量避免在循环输出的表格中使用合并单元格,以确保数据的正确渲染。
+- **使用跨列居中**:如果需要文本在多个单元格中横向居中,可以使用“跨列居中”功能,而不是合并单元格。
+- **限制合并单元格的位置**:若必须使用合并单元格,请仅在表格的上方或右侧进行合并,避免在下方或左侧合并,以防渲染时合并效果丢失。
+
+**示例**:
-## 模板样式
+**错误示范**:
-### 常见问题
+| 姓名 | 部门 | 职位 |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
-#### 1. Excel模板文件中的空列和空单元格在渲染结果中消失
+*如果在“部门”列合并单元格,可能导致渲染异常。*
-如果 Excel 文件中的某个单元格没有内容或样式,渲染时可能会被去除。为确保单元格在渲染过程中不会消失,建议在制作 Excel 文件时,为目标区域填充背景色或在单元格内插入空格,即使该单元格为空也能保持可见。
+**正确示范**:
-#### 2. 合并单元格在输出时没有效果
+| 姓名 | 部门 | 职位 |
+|---|---|---|
+| {d.staffs[i].name} | {d.staffs[i].department} | {d.staffs[i].position} |
+| {d.staffs[i+1].name} | {d.staffs[i+1].department} | {d.staffs[i+1].position} |
-在使用循环功能输出表格时,如果同时使用了合并单元格,可能会导致无法预料的问题。原则上,我们不推荐使用合并单元格。如果需要文本在多个单元格中横向居中,建议使用跨列居中功能。若必须使用合并单元格,请仅限于表格的上方和右侧。若在表格下方或左侧使用合并单元格,渲染数据时合并效果可能会消失。
+*保持每个单元格独立,避免合并单元格。*