| title | editor | author | date | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
The Ontolex Module for Frequency, Attestation and Corpus Information |
|
|
2025-01-21 |
This document describes the module for frequency, attestation and corpus information of the OntoLex Lexicon Model for Ontologies (OntoLex-Lemon) developed by the W3C Community Group Ontology-Lexica. The module is targeted at complementing dictionaries and other linguistic resources containing lexicographic data with a vocabulary to express
- corpus-derived information (frequency and cooccurrence information, collocation analysis),
- pointers from lexical resources to corpora and other collections of text (attestations, examples), and
- the linking of corpora and linguistic primary data with lexical information (dictionary linking).
The module tackles use cases in corpus-based lexicography and corpus linguistics, and operates in combination with the OntoLex-Lemon core module (Lemon), as well as with other lemon modules.
This document is an official report of the OntoLex community group. It does not represent the view of single individuals but reflects the consensus and agreement reached as part of the regular group discussions. The report should be regarded as the official specification of lemon.
If you wish to make comments regarding this document, please send them to [email protected] (subscribe, archives).
OntoLex-Lemon provides a core vocabulary to represent linguistic information associated with ontology and vocabulary elements. The model follows the principle of semantics by reference in the sense that the semantics of a lexical entry is expressed by reference to an individual, class or property defined in an ontology. The OntoLex module for Frequency, Attestations and Corpus-Based Information (OntoLex-FrAC) complements OntoLex-Lemon with the capability of including information drawn from or found in corpora and linguistic primary data.
In particular, the model's primary motivation is to provide a means to link lexical resources to corpora and other collections of text, and to express the relationship between lexical information and the primary data from which it is derived. As such this module will:
- Extend the use of OntoLex-Lemon to support digital lexicography,
- Contribute to the integration of lexicography, AI and human language technology communities,
- Provide a method of representing this information in a way that is compatible with the existing OntoLex-Lemon model.
This is a list of relevant namespaces that will be used in the rest of this document:
OntoLex module for frequency, attestation and corpus information
@prefix frac: <http://www.w3.org/ns/lemon/frac#> .
OntoLex (core) model and other lemon modules:
@prefix ontolex: <http://www.w3.org/ns/lemon/ontolex#> .
@prefix synsem: <http://www.w3.org/ns/lemon/synsem#> .
@prefix decomp: <http://www.w3.org/ns/lemon/decomp#> .
@prefix vartrans: <http://www.w3.org/ns/lemon/vartrans#> .
@prefix lime: <http://www.w3.org/ns/lemon/lime#> .
@prefix lexicog: <http://www.w3.org/ns/lemon/lexicog#> .Other models:
@prefix rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#>.
@prefix rdfs: <http://www.w3.org/2000/01/rdf-schema#>.
@prefix owl: <http://www.w3.org/2002/07/owl#>.
@prefix xsd: <http://www.w3.org/2001/XMLSchema#>.
@prefix lexinfo: <http://www.lexinfo.net/ontology/3.0/lexinfo#>.
@prefix dct: <http://purl.org/dc/terms/>.
@prefix oa: <http://www.w3.org/ns/oa#>.
@prefix dcterms: <http://purl.org/dc/terms/> .The following diagram depicts the OntoLex module for frequency, attestation and corpus information (OntoLex-FrAC). Boxes represent classes of the model. Arrows with filled heads represent object properties. Arrows with empty heads represent rdfs:subClassOf.
, overview")
OntoLex-FrAC provides the necessary vocabulary to express observations obtained from a language resource about any linguistic or conceptual entity that can be observed in a corpus ("observable"). By observable, we mean
- any lexical entity that can be described with OntoLex (including, but not limited to, OntoLex core classes
ontolex:LexicalEntry,ontolex:Form,ontolex:LexicalSenseorontolex:LexicalConcept), as well as - any ontological entity from a knowledge graph (corresponding to the object of an
ontolex:denotes,ontolex:referenceorontolex:isConceptOfproperty).
The top-level concepts of OntoLex-FrAC are thus frac:Observable and frac:Observation, complemented by a property frac:observedIn, pointing to the URI where the observation has been made.
Observable (Class)
URI: http://www.w3.org/ns/lemon/frac#Observable
Observable is a superclass for any element of a lexical resource that frequency, attestation or corpus-derived information can be expressed about. This includes, among others, ontolex:LexicalEntry, ontolex:LexicalSense, ontolex:Form, and ontolex:LexicalConcept. Elements that FrAC properties apply to must be observable in a corpus or another linguistic data source.

We assume that frequency, attestation and corpus information can be provided about every linguistic content element in the OntoLex-Lemon core model and in existing or forthcoming OntoLex modules. This includes ontolex:Form (e.g., token frequency), ontolex:LexicalEntry (e.g., frequency of disambiguated lemmas), ontolex:LexicalSense (e.g., sense frequency), ontolex:LexicalConcept (e.g., synset frequency), lexicog:Entry (if used for representing homonyms: frequency of non-disambiguated lemmas).
In particular, we consider all these elements to be countable, annotatable/attestable. For this reason, we introduce frac:Observable as a top-level element within the FrAC module that is used to define the rdfs:domain of all the properties that link lexical and corpus-derived information.
Observation (Class)
URI: http://www.w3.org/ns/lemon/frac#Observation
Observation is a superclass for anything that can be observed in a corpus about an Observable.
SubClassOf: exactly 1 frac:observedIn, min 1 dct:description, exactly 1 rdf:value
Observations as understood here are empirical (quantitative) observations that are made against a corpus, a text, a document or another type of language data. Observations can be made in any kind of (collection or excerpt of) linguistic data at any scale, structured or unstructured, regardless of its physical materialization (as an electronic corpus, as a series of printed books, as a bibliographical database or as metadata record for a particular corpus).
observedIn (ObjectProperty)
URI: http://www.w3.org/ns/lemon/frac#observedIn
For a frac:Observation, the property observedIn defines the URI of the data source (or its metadata entry) that this particular observation was made in or derived from. This can be, for example, a corpus or a text represented by its access URL, a book represented by its bibliographical metadata, etc.
Domain: frac:Observation
Range: anyURI
Lexicographers use (corpus) frequency and distribution information while compiling lexical entries, as a qualitative assessment of their resources. In this module, we focus on absolute frequencies, as relative frequencies can be derived if absolute frequencies and token totals are known. Absolute frequencies are used in computational lexicography and they are an essential piece of information for NLP and corpus linguistics.
Frequency (Class)
URI: http://www.w3.org/ns/lemon/frac#Frequency
Frequency is a frac:Observation of the absolute number of attestations (rdf:value) of a particular frac:Observable (see frac:frequency) that is frac:observedIn in a particular data source. Using frac:unit, frequency objects can also identify the (segmentation) unit that their counts are based on.
SubClassOf: frac:Observation
SubClassOf: rdf:value exactly 1 , frac:observedIn exactly 1
A frequency should have a unit that specifies the segmentation unit of the frequency count. This can be, for example, "tokens", "types", "lemmas", "sentences", "paragraphs", etc.
unit (Property)
URI: http://www.w3.org/ns/lemon/frac#unit
For a frac:Frequency object, the property unit provides an identifier of the respective segmentation unit.
rdfs:range frac:Frequency
Examples of values of frac:unit include string literals such as "tokens", "sentences", etc. If a future community standard provides reference URIs for such datatypes, frac:unit should be used as a datatype property. Until such a convention has been established, it is recommended to be used as a datatype property.
frequency (ObjectProperty)
URI: http://www.w3.org/ns/lemon/frac#frequency
The property frequency assigns a particular frac:Observable a frac:Frequency.
rdfs:domain frac:Observable
rdfs:range frac:Frequency
There is only a single data source, in which the frequency is observed, so the frequency value should correspond to the aggregation of sources and languages in that dataset.
The definition above only applies to absolute frequencies. For expressing relative frequencies, we expect the associated data source (frac:observedIn) object to define a total of elements contained (frac:total). In many practical applications, it is necessary to provide relative counts, and in this way, these can be easily derived from the absolute (element) frequency provided by the Frequency class and the total defined by the underlying corpus. If the real absolute values are unknown and only relative scores are provided, data providers should use percentage values for both the Frequency rdf:value and for the frac:total (i.e., 100%) of the associated corpus.
A simple example of indicating the frequency of a word in a corpus is given below:
:cat-n a ontolex:LexicalEntry ;
ontolex:denotes :oewn-02124272-n,
:oewn-02130460-n .
:oewn-02124272-n ;
skos:definition "feline mammal usually having thick soft fur and no ability to roar: domestic cats; wildcats"@en ;
frac:frequency [
a frac:Frequency ;
rdf:value 46
frac:observedIn <https://wordnetcode.princeton.edu/glosstag.shtml>
]
] .
:oewn-02130460-n ;
skos:definition "any of several large cats typically able to roar and living in the wild"@en ;
frac:frequency [
a frac:Frequency ;
rdf:value 4
frac:observedIn <https://wordnetcode.princeton.edu/glosstag.shtml>
]
] .The identifiers and data is drawn from the Open English Wordnet project, however, it is simplified for explanatory purposes.
The following example illustrates word and form frequencies for the Sumerian word a (n.) "water" from the Electronic Penn Sumerian Dictionary and the frequencies of the underlying corpus.
# word frequency, over all form variants
epsd:kalag_strong_v a ontolex:LexicalEntry;
frac:frequency [
a frac:Frequency;
rdf:value "2398"^^xsd:int;
frac:observedIn <http://oracc.museum.upenn.edu/epsd2/pager>
] .
# form frequency for individual orthographical variants
epsd:kalag_strong_v ontolex:canonicalForm [
ontolex:writtenRep "kal-ga"@sux-Latn;
frac:frequency [
a frac:Frequency;
rdf:value "2312"^^xsd:int;
frac:observedIn <http://oracc.museum.upenn.edu/epsd2/pager>
]
] .
epsd:kalag_strong_v ontolex:otherForm [
ontolex:writtenRep "kalag"@sux-Latn;
frac:frequency [
a frac:Frequency;
rdf:value "70"^^xsd:int;
frac:observedIn <http://oracc.museum.upenn.edu/epsd2/pager>
]
] .The example shows an orthographic variation (in the Latin transcription). It is slightly simplified insofar as the ePSD2 provides individual counts for different periods and only three of six orthographical variants are given. Note that these are orthographical variants, not morphological variants (which are not given in the dictionary).
total (ObjectProperty)
URI: http://www.w3.org/ns/lemon/frac#total
The object property total assigns any potential FrAC data source (i.e., dct:Collection, dct:Dataset, dct:Text or any other member of DCMI Type) the total number of elements that it contains as a frac:Frequency object.
Domain: class that is a dcam:memberOf DCMI Type
Range: frac:Frequency
For frac:total, users should provide both the frequency and the segmentation/unit over which this frequency is obtained. For an observable, relative frequencies (for any given unit u) can then be calculated from the object values of frac:frequency/rdf:value and frac:frequency/frac:observedIn/frac:total/rdf:value if (and only if) the corresponding units match.
An example of the use of frac:total is given below:
<https://wordnetcode.princeton.edu/glosstag.shtml> a dct:Collection ;
frac:total [
a frac:Frequency ;
rdf:value 1634691 ;
frac:unit "tokens"
] .Attestations constitute a special form of citation that provide evidence for the existence of a certain lexical phenomena; they can elucidate meaning or illustrate various linguistic features.
In scholarly dictionaries, attestations are a representative selection from the occurrences of a headword in a textual corpus. These citations often consist of a quotation accompanied by a reference to the source. The quoted text usually contains the occurrence of the headword.
Attestation (Class)
URI: http://www.w3.org/ns/lemon/frac#Attestation
An Attestation is a frac:Observation that represents one exact or normalized quotation or excerpt from a source document that illustrates a particular form, sense, lexeme or features such as spelling variation, morphology, syntax, collocation, register.
For an attestation, rdf:value represents the text of a quotation as represented in the original source.
SubClassOf: rdf:value max 1
SubClassOf: frac:Observation
Attestations are linked with the frac:attestation property to the frac:Observable they attest.
attestation (ObjectProperty)
URI: http://www.w3.org/ns/lemon/frac#attestation
The property frac:attestation associates an attestation to the frac:Observable. This is a subproperty of frac:citation using concrete data as evidence.
Domain: Observable
Range: Attestation
SubPropertyOf: citation
As an example of an attestation, consider the following example from Open English Wordnet:
:02105605-a a skos:Concept ;
skos:definition "concerned chiefly or only with yourself and your advantage
to the exclusion of others"@en ;
frac:attestation [
rdf:value "We're asked to see Rachel as this spoilt, self-centred woman
but the rest of them are just as bad, if not worse."@en ;
frac:observedIn <https://www.newstatesman.com/culture/tv/2023/10/
friends-comedy-humour-legacy-matthew-perry> ] .In general, the object of a citation represents the successful act of citing an entity which can be referred to by a standardised bibliographic reference, cf. Peroni (2012) \cite{peroni2012fabio}:
[a Citation is] “a conceptual directional link from a citing entity to a cited entity, created by a human performative act of making a citation, typically instantiated by the inclusion of a bibliographic reference in the reference list of the citing entity, or by the inclusion within the citing entity of a link, in the form of an HTTP Uniform Resource Locator (URL), to a resource on the World Wide Web”.
Citations are given with the following property:
citation (ObjectProperty)
URI: http://www.w3.org/ns/lemon/frac#citation
The property frac:citation associates a citation to the Observable citing it.
Domain: Observable
However, note that FrAC does not formally define a general "Citation" class to define the range of citation, but only provides Attestation as one specific possibility. Beyond attestations, different vocabularies have been suggested for linking bibliographical information, and we advise users of FrAC to make a consistent choice among them, adequate for their respective needs and the conventions of their users' community. frac:citation serves as an interface to these external vocabularies. If the CITO vocabulary is used in a particular resource, their FrAC Citations can be defined as the subclass of CITO citations having frac:Observable as citing entity and attestations would correspond to citations with the cito:hasCitationCharacterization value citesAsEvidence. Other relevant vocabularies include, for example, BIBFRAME, FRBR and FaBiO, but also, generic vocabularies such as schema.org.
Glosses are used to give the form of the text as used in the dictionary. This property should not be used to provide direct quotations from the original data source, which should be represented by rdf:value. Instead, its recommended use is for representations that are either enriched (e.g., by annotations and metadata), amended (e.g., by expanding ligatures or omissions), simplified (e.g., by omissions from the original context, e.g., of the lexeme under consideration) or otherwise differentiated from the plain text representation of the context.
gloss (Property)
URI: http://www.w3.org/ns/lemon/frac#gloss
The gloss of an attestation contains the text content of an attestation as represented within a dictionary.
Domain: Attestation
Range: xsd:String
As an example, for Old English hwæt-hweganunges, Bosworth (2014) gives the example "Ða niétenu ðonne beóþ hwæthuguningas [MS. Cote. -hwugununges] .... In OntoLex-FrAC, this would be the frac:gloss because it contains additional information about spelling variation/normalized spelling not found in the quoted source (MS. Cote.):
<https://bosworthtoller.com/20070> a ontolex:LexicalEntry;
frac:attestation [
a frac:Attestation;
rdf:value "Ða niétenu ðonne beóþ hwæthwugununges" ;
frac:gloss "Ða niétenu ðonne beóþ hwæthuguningas [MS. Cote. -hwugununges] ..."
] .In many applications, it is desirable to specify the precise location of the occurrence of a headword in the quoted text of an attestation, for example, by means of character offsets. The FrAC standard supports referencing using RFC5147 character offsets, Text Fragments, NIF URIs, or by means of Web Annotation references (see Section 6). As different vocabularies can be used to establish locus objects, the FrAC vocabulary is underspecified with respect to the exact nature of the locus object. Accordingly, the locus property that links an attestation with its source takes any URI as its object.
locus (ObjectProperty)
URI: http://www.w3.org/ns/lemon/frac#locus
frac:locus points to the location at which the relevant word(s) can be found.
Domain: Attestation
:lexical_entry a ontolex:LexicalEntry ;
ontolex:canonicalForm [
ontolex:writtenRep "lexical entry" ;
frac:attestation [
a frac:Attestation ;
rdf:value "lexical entry" ;
frac:locus
<https://www.w3.org/2016/05/ontolex/#:~:text=of%20a-,lexical%20entry,-is%20expressed> ;
frac:observedIn <https://www.w3.org/TR/ontolex/>
]
] .frac:locus denotes a specific location within a text, e.g., a character offset or a URI pointing to a specific location in a text. In contrast, frac:observedIn can refer to a corpus of other collections of texts. frac:locus normally refers to a location identified by RFC5147 character offsets, NIF URIs, Open Annotation or Text Fragments references, whereas frac:observedIn refers to dct:Texts or dct:Collections.
A collocation is a sequence of words or terms that co-occur more often than would be expected by chance. Often, collocations are idiomatic expressions, but they can also be more general, such as "strong tea" or "heavy rain".
Collocation analysis is an important tool for lexicographical research and instrumental for modern NLP techniques. It has been the mainstay of 1990s corpus linguistics and continues to be an area of active research in this field as well as in computational philology and lexicography.
Collocations are usually defined on surface-oriented criteria, i.e., as a relation between forms or lemmas (lexical entries), not between senses, but they can be analyzed on the level of word senses (the sense that gave rise to the idiom or collocation). Indeed, collocations often contain a variable part, which can be represented by a ontolex:LexicalConcept.
Collocations can involve two or more words, they are thus modelled as an rdfs:Container of frac:Observables. Collocations may have a fixed or a variable word order. Where fixed word order is required, the collocation must be defined as a sequence (rdf:Seq), otherwise, the default interpretation is as an ordered set (rdf:Bag).
Collocations obtained by quantitative methods are characterized by their method of creation (dct:description), their collocation strength (rdf:value), and the corpus or data source used to create them (frac:observedIn). Collocations share these characteristics with other frac:Observations and thus, these are inherited from the frac:Observation class.
Collocation (Class)
URI: http://www.w3.org/ns/lemon/frac#Collocation
A Collocation is a frac:Observation that describes the co-occurrence of two or more frac:Observables within the same context window and that can be characterized by their collocation score (or weight, rdf:value) in a particular data source (frac:observedIn).
SubClassOf: frac:Observation, rdfs:Container, frac:Observable
rdfs:member: only frac:Observable
SubClassOf: frac:head max 1
Collocations are collections of frac:Observables, and formalized as rdfs:Container, i.e., rdf:Seq or rdf:Bag. The elements of any collocation can be accessed by rdfs:member. In addition, the elements of an ordered collocation (rdfs:subClassOf rdf:Seq) can be accessed by means of numerical indices (rdf:_1, rdf:_2, etc.).
By default, frac:Collocation is insensitive to word order. If a collocation is word order sensitive, it should be defined as rdfs:subClassOf rdf:Seq. Collocation analysis typically involves additional parameters such as the size of the context window considered. Such information can be provided in human-readable form in dct:description.
FrAC collocations can be used to represent collocations both in the lexicographic sense (as complex units of meaning) and in the quantitative sense (as determined by collocation metrics over a particular corpus), but that the quantitative interpretation is the preferred one in the context of FrAC. To mark collocations in the lexicographic sense as such, they can be assigned a corresponding lexinfo:termType, e.g., by means of lexinfo:idiom, lexinfo:phraseologicalUnit or lexinfo:setPhrase. If explicit sense information is being provided, the recommended modelling is by means of ontolex:MultiWordExpression and the OntoLex-Decomp module rather than frac:Collocation. To provide collocation scores about a ontolex:MultiWordExpression, it can be linked via rdfs:member with a frac:Collocation.
Since collocations are frac:Observables, they can be ascribed frac:frequency, frac:attestation, frac:embedding and they can be nested inside larger collocations.
Collocations can be described in terms of various collocation scores. If scores for multiple metrics are being provided, these should not use the generic rdf:value property, but a designated subproperty of frac:cScore:
URI: http://www.w3.org/ns/lemon/frac#cScore
Collocation score is a subproperty of rdf:value that provides the value for one specific type of collocation score for a particular collocation in its respective corpus. Note that this property should not be used directly, but instead, its respective sub-properties for scores of a particular type.
SubPropertyOf: rdf:value
domain: frac:Collocation
LexInfo defines a number of popular collocation metrics as sub-properties of frac:cScore:
lexinfo:relFreq(relative frequency): RF(x,y|x)=fxyfx(=Rx) (asymmetric, requiresfrac:head)lexinfo:pmi(pointwise mutual information, sometimes referred to as MI-score or association ratio, cf. Church and Hanks 1990, via Ewert 2005: PMI(x,y)=log2fxyNfxfylexinfo:pmi2(PMI²-score): PMI2(x,y)=log2fxy2Nfxfylexinfo:pmi3(PMI³-score, cf. Daille 1994 in Ebert 2005, p.89): PMI3(x,y)=log2fxy3Nfxfylexinfo:pmiLogFreq(PMI.log-f, salience, formerly default metric in SketchEngine): PMI.log−f(x,y)=log2fxyNfxfy×logfxylexinfo:dice(Dice coefficient): Dice(x,y)=2fxyfx×fylexinfo:logDice(default metric in SketchEngine, Rychly 2008): LogDice(x,y)=log2Dice(x,y)lexinfo:minSensitivity(minimum sensitivity, cf. Pedersen 1998): MS(x,y)=min(Rx,Ry)
with
- x,y the (head) word and its collocate
- fx the number of occurrences of the word x
- fy the number of occurrences of the word y
- fxy the number of co-occurrences of the words x and y
- Ry=fxyfy relative frequency of y
- N the total number of words in the corpus, this should be documented in
dct:description
In addition to collocation scores, also statistical independence tests can be employed as collocation scores:
lexinfo:logLikelihood(log likelihood, G² Dunning 1993, via Ewer 2005)lexinfo:tScore(Student's t test, T-score, cf. Church et al. 1991, via Ewert 2005, p.82 ): T(x,y)=fxy−(fxfy)Nfxylexinfo:chi2(Person's Chi-square test Manning 1999 ): χ2(x,y)=N(O11O22−O12O21)2(O11×O12)(O11×O21)(O12×O22)(O21×O22)
with
- O11=fxy
- O12=fy−fxy
- O21=fx−fxy
- O22=N−fx−fy×2fxy
- N - the total number of words in the corpus
In addition to classical collocation metrics, as established in computational lexicography and corpus linguistics, related metrics can also be found in different disciplines and are represented here as subproperties of frac:cScore, as well. This includes metrics for association rule mining. In this context, an association rule (collocation) x→y means that the existence of word x implies the existence of word y
lexinfo:support(the support is an indication of how frequently the rule appears in the dataset): support(x→y)=fxyN (with N the total number of collocations)lexinfo:confidence(the confidence is an indication of how often the rule has been found to be true): confidence(x→y)=fxyfxlexinfo:lift(the lift or interest of a rule measures how many times more often x and y occur together than expected if they are statistically independent): lift(x→y)=fxyfxfylexinfo:conviction(the conviction of a rule is interpreted as the ratio of the expected frequency that x occurs without y, i.e., the frequency that the rule makes an incorrect prediction, if x and y are independent divided by the observed frequency of incorrect predictions): conviction(x→y)=(1−fy)fxfx−fxy
Many of these metrics are asymmetric and distinguish the lexical element they are about (the head) from its collocate(s). If such metrics are provided, a collocation should explicitly identify its head:
URI: http://www.w3.org/ns/lemon/frac#head
The head property identifies the element of a collocation that its scores are about. A collocation must not have more than one head.
domain: frac:Collocation
range: frac:Observable
As an example, the relative frequency score is the number of occurrences of a collocation relative to the overall frequency of its head.
The following example illustrates collocations as provided by the Wortschatz portal (scores and definitions as provided for beans, spill the beans, etc.
@prefix wsen: <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012&word=>
# selected lexical entries
# (we assume that every Wortschatz word is an independent lexical entry)
wsen:beans a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "beans"@en.
wsen:spill a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "spill"@en.
wsen:green a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "green"@en.
wsen:about a ontolex:LexicalEntry;
ontolex:canonicalForm/ontolex:writtenRep "about"@en
# collocations, non-lexicalized
[ rdfs:member wsen:spill, wsen:beans ] a frac:Collocation;
rdf:value "182";
dct:description "cooccurrences in the same sentence, unordered";
frac:observedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>.
[ rdf:_1 wsen:green; rdf:_2 wsen:beans ] a frac:Collocation, rdf:Seq ;
rdf:value "778";
dct:description "left neighbor cooccurrence";
frac:observedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>;
lexinfo:termType lexinfo:idiom.
[ rdf:_1 wsen:beans; rdf:_2 wsen:about ] a frac:Collocation, rdf:Seq;
rdf:value "35";
dct:description "right neighbor cooccurrence";
frac:observedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>;
lexinfo:termType lexinfo:idiom.
# multi-word expression, lexicalized (!)
wsen:spill+the+beans a ontolex:MultiWordExpression;
ontolex:canonicalForm/ontolex:writtenRep "spill the beans"@en.
[ rdfs:member wsen:beans, wsen:spill+the+beans ] a frac:Collocation;
rdf:value "401";
dct:description "cooccurrences in the same sentence, unordered";
frac:obsevedIn <http://corpora.uni-leipzig.de/en/res?corpusId=eng_news_2012>.The Ontolex Module for Frequency, Attestation and Corpus Information does not specify a vocabulary for annotating corpora or other data with lexical information, as this is being provided by the Web Annotation Vocabulary. The following description is non-normative as Web Annotation is defined in a separate W3C recommendation. The definitions below are reproduced and refined only insofar as domain and range declarations have been refined to our use case.
In Web Annotation terminology, the annotated element is the ‘target’, the content of the annotation is the ‘body’, and the process and provenance of the annotation is expressed by properties of oa:Annotation.
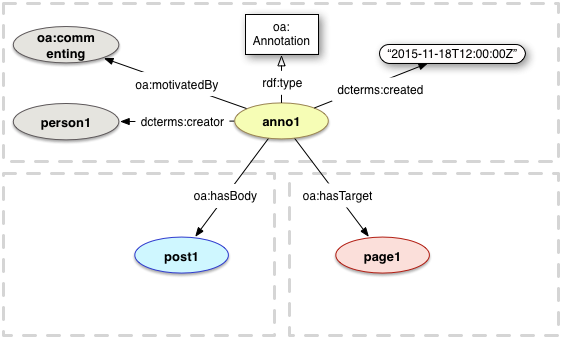
Annotation as linked with the oa:hasBody and oa:hasTarget properties:
The Web Annotation Vocabulary supports different ways to define targets. This includes:
- plain URI: The target can be a URI defined within the corpus (e.g., if corpus data is provided as native RDF, or by means of the @about attribute in an HTML/XML+RDFa document, or by means of @xml:id in a TEI/XML document).
- string URI: String URIs provide the possibility to point directly to a text fragment in a web document, using the URI schemas as provided by RFC5147 (text files only) or NIF (all text-based formats).
- oa:TextPositionSelector: a range of text defined by the start and end positions of the selection in the stream
- oa:DataPositionSelector: a range of data by recording the start and end positions of the selection in the stream
- oa:TextQuoteSelector: The TextQuoteSelector describes a range of text by copying it. The TextQuoteSelector can include some of the text immediately before (a prefix) and after (a suffix) to distinguish between multiple copies of the same sequence of characters. If this does suffice for disambiguation, all matching text fragments in the document are being annotated.
- oa:XPathSelector: select elements and content within a resource that supports the Document Object Model via a specified XPath value.
- oa:RangeSelector: identify the beginning and the end of the selection by using other Selectors.
:annotation a oa:Annotation, frac:Attestation ;
oa:hasTarget :target ;
frac:locus :target ;
oa:hasBody :lex_entry .
:target a oa:TexPositionSelector ;
oa:start 123 ;
oe:end 456 .
:lex_entry frac:attestation :annotation .oa:Annotation explicitly allows n:m relations between ontolex:Elements and elements in the annotated elements. It is thus sufficient for every ontolex:Element to appear in one oa:hasBody statement in order to produce a full annotation of the corpus.
As for frequency, embeddings, etc., resource-specific annotation classes can be defined by owl:Restriction so that modelling effort and verbosity are reduced. These should follow the same conventions.
The NLP Interchange Format (NIF) is a standard for the representation of text annotations. It is based on RDF and allows for the representation of text, its structure, and annotations. NIF is particularly useful for the representation of text annotations in the context of the Semantic Web. The NIF standard is defined in the NIF 2.1 specification.
NIF strings can be used as a locus for an attestation as follows:
@prefix nif: <http://persistence.uni-leipzig.org/nlp2rdf/ontologies/nif-core#> .
:annotation a frac:Attestation ;
frac:locus <http://example.org/text#char=123,456> .
<http://example.org/text#char=123,456> a nif:String ;
nif:beginIndex "123"^^xsd:nonNegativeInteger ;
nif:endIndex "456"^^xsd:nonNegativeInteger ;
nif:isString "The quick brown fox jumps over the lazy dog."@en .In this example, the string "The quick brown fox jumps over the lazy dog." is annotated as an attestation at character positions 123 to 456.
Alternatively, the loci of attestations may be given as RFC5147 URIs or as Text Fragments. The following example illustrates the use of RFC5147 URIs:
:annotation a frac:Attestation ;
frac:locus <http://example.org/text#char=123,456> .In this example, the string "The quick brown fox jumps over the lazy dog." is annotated as an attestation at character positions 123 to 456.