Implement non-axis windows and chunks iterators #276
Comments
|
That sounds good, and I love a good illustration to go together with expressing an idea. One concern I have here is that it's probably still not an efficient way to implement convolution, to go through this. |
Thanks! :)
True! For performance the most promising implementation for convolution is to use a GPGPU approach. But what if one doesn't want to go that far? The main question for this issue for me is, if it is possible to provide such iterators with equal performance as extern definitions. But as far as I can imagine such iterators would perform much better if implemented internally in this crate with hidden data of Also: What implementation would fit best? We could implement such iterator for example by using an item-sized local
|
|
Between as_ptr, as_mut_ptr, and the |
Okay, good to know about the currently possible "hack", but yeah it wouldn't be a very natural way to encode this behavious and would require unsafe rust to deref the pointers which is unnecessary. For me both proposed iterators would be great and would be of great use for my projects! |
|
Sure, the window iterator is a good idea. If I understand correctly, chunks has a chunk size in each dimension? .axis_chunks_iter() currently covers it if you just want to chunk it along one dimension, (using the full width of every other). I also want to underline that using the |
|
For my proposed idea I cannot use the For 2-dimensions I could really use this for the pooling function within the convolution. And for a 3 dimensional array of size For both iterators it should be decided whether we also are in need of full-iterator that (as described) above iterate over the full area, instead of only the valid area. This is possible since in |
|
axis_chunks_iter gives views that have the same dimensionality (1d → 1d, 2d → 2d) though. |
Okay I will have to take another look into the docs. Maybe I have overseen things and it could really be used to simulate the chunks iterator that I proposed here. |
|
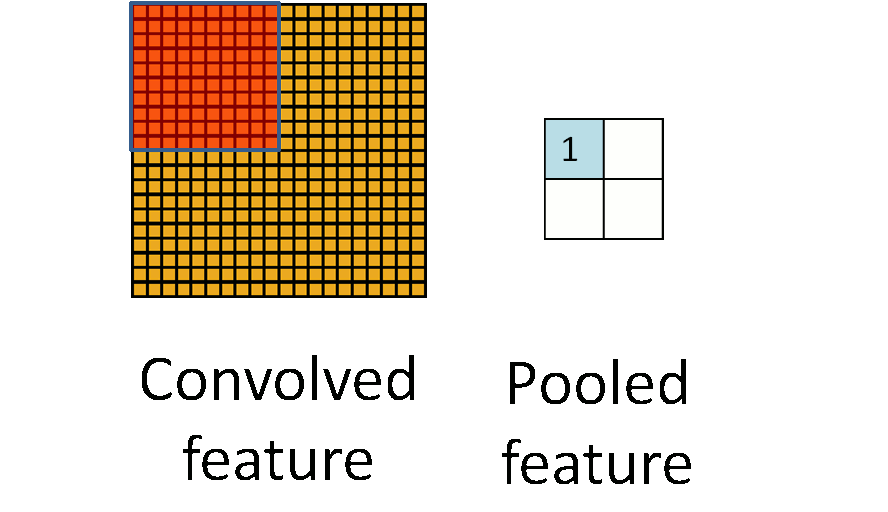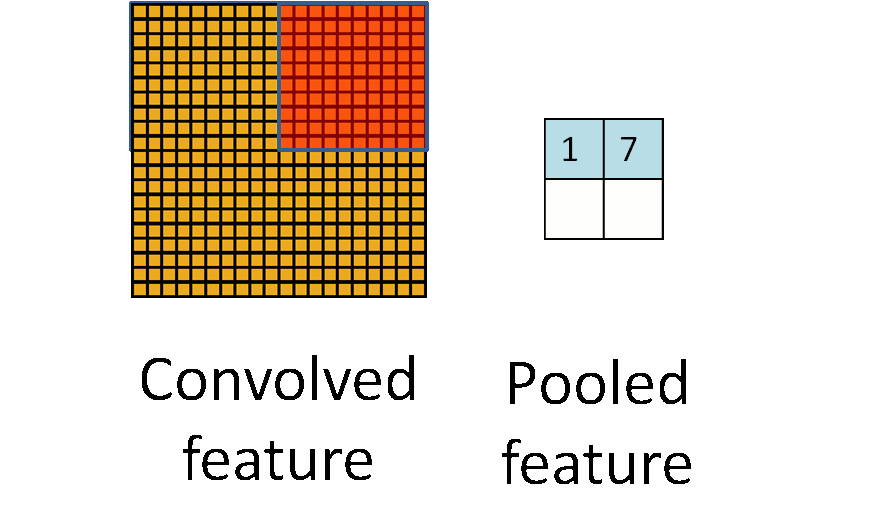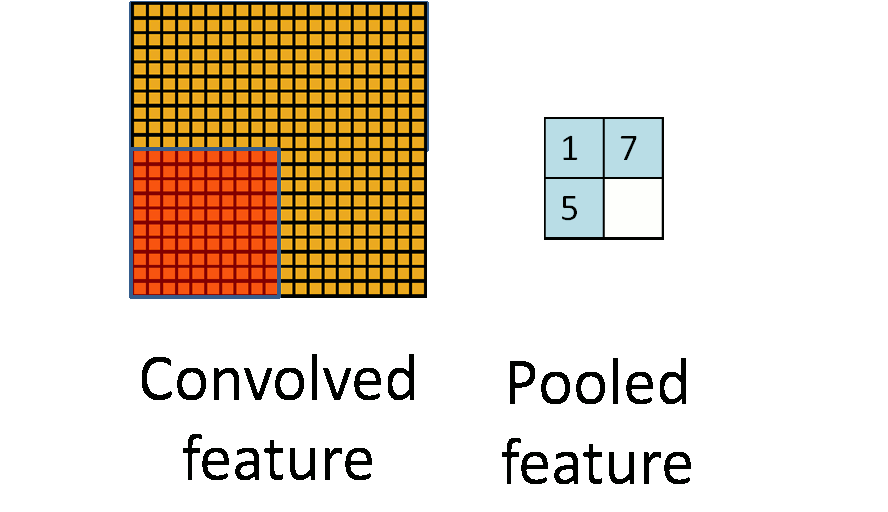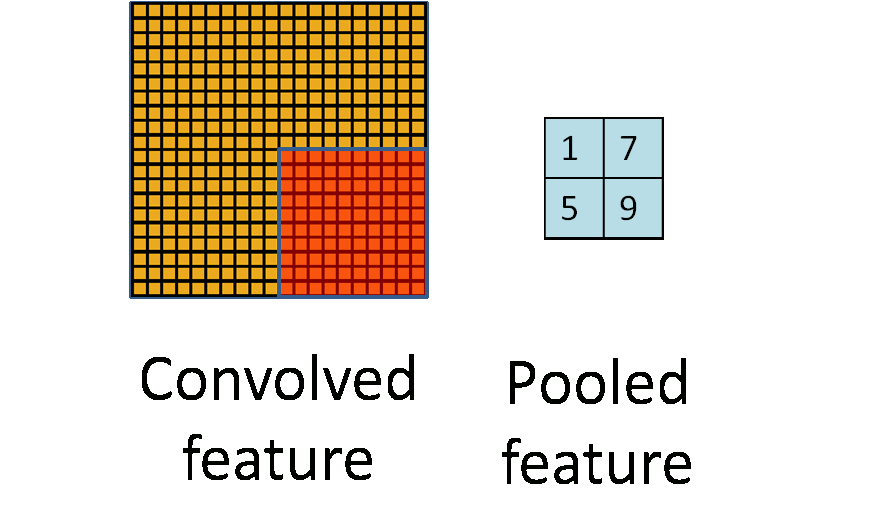
I have found a semi-nice visualization of the proposed chunks iterator for 2 dimensions here. |
{kind=link}
|
Right, the current axis_chunks_iter cuts stripes, not squares. So they are different in that way. |
|
How do you feel about the importance of a |
|
Not important, but we can try to do it |
|
How do you feel about me trying to do it via PR? (This would probably take a while since I have to wrap my head around the libraries internals.) |
|
Go ahead.
|
|
Okay I will try! :) |
|
Today I looked into the ndarray code to wrap my head around the iterator and especially the It is not yet very clear to me but could it be possible to design a windows or chunks iterator without any copy operations into an iterator-internal owning I need feedback on this. |
|
I recognize it's not super easy to implement a new iterator, since it's so much about ndarray implementation details. I think you would want do do something like InnerIter: have a Baseiter and also extra information. However for chunks/windows it needs to have a whole dimension/stride set, not just a single number (Basically |
|
Yep I got that point with the Let's see if I can get it working. :S |
|
If I think of the chunks iterator and am not mistaken I think that We use sliced dimension and sliced stride to initialize Baseiter (One can slice in place using the array method |
|
This code could also be read to understand how to use a slice / subview of an array as a “map” of array views. Imagine we have an array of N dimensions and want to cut it into separate one-dimensional “sticks” (or “lanes”). That's what these methods do. Only difference is they use a callback instead of an iterator. |
|
I think I understood how I can utilize I could also use The part that is currently unclear to me is, how I can perform the n-dimensional iteration of all possible We need an efficient way for iterating over all possible slices or indices. I saw that the iteration |
|
The iteration That means if D is |
|
This is maybe not so straightforward, you could leave this to me if you want. |
That's awesome!
I would like to try it out now if this is okay for you. So I think I can design struct Windows<'a, A: 'a, D: 'a + Dimension> {
/// view of the entire array under iteration
view : ArrayView<'a, A, D>,
/// iterator for all possible valid window indices
indices: Indices<D>,
/// the shape of the windows
shape : Shape<D>
}
pub fn windows<'a, A: 'a, D: 'a + Dimension>(array: ArrayView<'a, A, D>, shape: Shape<D>) -> Windows<'a, A, D> {
Windows{
view: array.view(),
indices: indices_of(&array), // restrict array to area for valid windows shapes:
// e.g. array.shape() == [10, 8], window shape is [5, 4], then indices, area
// should be (0..5, 0..4).
shape: shape
}
}
impl<'a, A: 'a, D: 'a + Dimension> Iterator for Windows<'a, A, D> {
type Item = ArrayView<'a, A, D>;
fn next(&mut self) -> Option<Self::Item> {
match self.indices.next() {
None => None,
Some(idx) => {
let slice_arg = slice_at_idx_of_shape(self.shape, idx); // function that converts a shape and a given index into a SliceArg
Some(self.view.slice(slice_arg)) // return window with given shape at current index
}
}
}
}Questions for me to solve:
How close or far am I from your theory behind the codes for the windows iterator? To create a windows-slice for fn slice_at_idx_of_shape_2d<D: Dimension>(shape: D, idx: D) -> [Si; 2] {
[
Si(idx[0] as isize, Some((idx[0] + shape[0]) as isize), 1),
Si(idx[1] as isize, Some((idx[1] + shape[1]) as isize), 1)
]
}Provided that this implementation is correct it would be best imo to create a 1D, 2D, ... 6D version for it and a generalize dynamic allocation requiring method to avoid dynamic allocation up to 5 dimensional arrays. |
|
I have created a prototype implementation of a generic, malloc avoiding This makes it possible to map a pair of |
|
Making SliceArg available like that is good |
|
I have sort of gone into this territory with Zip, a chunk iterator might show up there. |
|
I haven't had quite enough time to work on this the last few days.
Does that mean that you are able to implement a I came to the conclusion that a |
|
What I want now with Zip is that one can zip together chunk producers and arrays. If an array is dim (10, 10) and we get a chunks producer with (2, 2) chunks, the chunks producer has dim (5, 5) and we can zip it with other (5, 5) arrays. Iterators are stateful, and handling the halfway-iterated state is troublesome. So I'm going the route (like rayon) of having “Producers” (Think of that as IntoIterator for the array zip). A producer can be split etc for parallelization. Some objects like Chunks is a Producer and IntoIterator, other objects like AxisIter can implement Producer and Iterator directly (because the axis iter is one dimensional, this is not a problem). |
|
Sounds very nice so far - especially the improved integration with rayon! If you no longer need it, I can at least serve you with the test cases implementation I came up with.
Odd chunks are shaped so fit into the remaining valid region, as in the standard chunks iterator. We could maybe also implement an |
|
I've only implemented the "EvenChunks" case so far (I called it WholeChunks to be less ambiguous). Basically it was there because I needed it to ensure that the trait for n-ary Zip could support it. I think that yes we want at least the windows iterator (and windows producer!) |
For whole chunks, the result must be 0 chunks (all chunks produced have the requested size), for ragged chunks it would be as many ragged chunks that fit. If the chunk is larger than the array in all dimensions, the result is 1 chunk, surely? Not sure what to do if the source array is size 0. |
|
How do you like working with the I personally thing the cleanest solution would be to simply return a zero sized ragged chunk, however, this is not the best solution to point a user to a logic error if this scenario is the result of one. |
|
If it's a logic error and programmer's error we have a convention to just panic; for example I'm not sure zero sized arrays are common. |
|
I think I have prototyped an implementation for the The implementations for the I am going to write some tests for the |
|
Great! I wrote some chunks tests for whole chunks (the easy version), maybe those can inspire. tests/iterator_chunks.rs I'm wishing that we make an NdProducer out of Windows, so that we can use it in azip. |
|
I have inspected your #[test]
fn test_windows_iterator_simple() {
let a = Array::from_iter(10..30).into_shape((5, 4)).unwrap();
let mut iter = windows(a.view(), Dim((3, 2)));
assert_eq!( iter.next().unwrap(), arr2(&[ [10, 11], [14, 15], [18, 19] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [11, 12], [15, 16], [19, 20] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [12, 13], [16, 17], [20, 21] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [14, 15], [18, 19], [22, 23] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [15, 16], [19, 20], [23, 24] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [16, 17], [20, 21], [24, 25] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [18, 19], [22, 23], [26, 27] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [19, 20], [23, 24], [27, 28] ]) );
assert_eq!( iter.next().unwrap(), arr2(&[ [20, 21], [24, 25], [28, 29] ]) );
assert_eq!( iter.next(), None );
}I wanted to (KISS) keep it simple stupid. :S |
|
Looks pretty good. I'm trying to learn to write more “exhaustive” style tests than just inputting examples. Your tests look good as they are, I'd probably use itertools::assert_equal to test the iterator's sequence though. |
|
So for example I'd prefer a test that tested all possible window sizes, since that's more exhaustive. |
Okay thanks!
Awesome! Didn't know about its existance. :)
True! I will first implement some naive implementations and later add some exhaustive tests. I would also like to test other dimensionalities, such as 3D. |
#[test]
fn test_windows_iterator_simple() {
let a = Array::from_iter(10..30).into_shape((5, 4)).unwrap();
itertools::assert_equal(
windows(a.view(), Dim((3, 2))),
vec![
arr2(&[ [10, 11], [14, 15], [18, 19] ]),
arr2(&[ [11, 12], [15, 16], [19, 20] ]),
arr2(&[ [12, 13], [16, 17], [20, 21] ]),
arr2(&[ [14, 15], [18, 19], [22, 23] ]),
arr2(&[ [15, 16], [19, 20], [23, 24] ]),
arr2(&[ [16, 17], [20, 21], [24, 25] ]),
arr2(&[ [18, 19], [22, 23], [26, 27] ]),
arr2(&[ [19, 20], [23, 24], [27, 28] ]),
arr2(&[ [20, 21], [24, 25], [28, 29] ])
]);
} |
|
All tests are passing now but this one: /// Test that verifites that no windows are yielded on oversized window sizes.
#[test]
fn windows_iterator_oversized() {
let a = Array::from_iter(10..37)
.into_shape((3, 3, 3))
.unwrap();
let mut iter = windows(a.view(), Dim((4, 3, 2))); // (4,3,2) doesn't fit into (3,3,3) => oversized!
assert_eq!(iter.next(), None);
}How is this functionality achieved in itertors using |
|
Just make sure the dimension of the iterator is computed to be |
|
Ah nice, I got screwed by this because of another bug with underflowed subtraction. All tests are working now. |
|
Sorry for all the churn around NdProducer and so on. It's a big project to make it work.. and a lot needs to change around it. Let me know, I'm fine with merging a windows iterator and fixing it to be ndproducer. |
|
Sorry for not notifying you on the status of the current windows implementation and tests. |
|
PR completed #306 - awaiting feedback |
|
I have added a task-list for the todos until this issue can finally be closed. |
|
Good. Lists are good. Checking things off is the next best thing to closing issues 😉 Thanks for working on Windows and working with ndarray in general. |
And thank you for maintaining all these awesome, high-quality libraries that are critical for the well-being of the rust ecosystem! |
|
Thanks a lot for this awesome work! Not being a Rust expert, I was wondering if it would be a lot of work to implement a full-window iterator with different array-border modes such as in scipy? Those kind of things are used a lot in image processing. |
|
I can remember that we were talking about similar things for the windows and chunks iterators but implemented only the simplest approaches of introducing them initially. I cannot tell you if implementation of different modes like wrap would incur overhead that'd make it impractical. Maybe @bluss can tell us more. :) |
|
One challenge with extending windows/chunks at the edges beyond the original array is that ideally we'd minimize copying the data as much as possible. The existing chunks and windows producers don't have to copy any of the data because they return
If all that's needed is an equivalent to If all that's needed is the ability to call a closure on chunks/windows, then idea (6) would be the simplest to implement. It would also be the cheapest because it could allocate a single owned array for handling all of the edge chunks/windows (by reusing it for each edge chunk/window). (Producers based on idea (4) would have to allocate a new owned array for each edge chunk/window because they lose ownership.) If we actually want producers that return the chunks/windows, though, I would recommend idea (4). (I've found other potential uses for a |
What is the status of this? |
Already implemented features and todos:
ExactChunksandExactChunksMutaswell as theirNdProducerimplRaggedChunksor simplyChunksaswell as theirNdProducerimplWindowsNdProducerimpl forWindowsImplement n-dimensional
windowsandchunksiterators.Windows-iterators are especially useful for convolutional neural networks while chunk iterations may prove useful for paralell algorithms.
N-Dimensionality for both iterators use N-dimensionally shaped items.
For example for a 1-dimensional Array the
windowsandchunksitems are also 1-dimensional.For a 2-dimensional Array the
windowsandchunksitems are 2-dimensional, and so on.For
windowsiterator it could be useful to support two different kinds ofwindowsiterators.One for "valid" windows only that iterate only over windows within a valid region.
For example in a valid-windows iterator over a
10x10shaped 2d-array and window sizes of4x4the iterator would iterate totally over(10-4+1)x(10-4+1)items of size4x4.A full-windows iterator would also iterate over the windows with invalid elements (on the edges of the array) and would simulate missing elements with zero elements.
Semi-nice visualization of n-dimensional chunks and windows iterators.
A similar approach could be used for n-dimensional chunks that iterate beyond the array sizes and replace missing/invalid array elements with zero elements.
The text was updated successfully, but these errors were encountered: