WebGL 是 OpenGL ES 2.0 图形库的 JavaScript 端口
- 自 WebGL 发布以来,出现了新一代的原生 GPU API——最受欢迎的是微软的 Direct3D 12、苹果的 Metal 以及科纳斯组织的 Vulkan——它们提供了大量新特性。并没有任何计划对 OpenGL(以及 WebGL)进行更多更新,因此它将不会获得任意这些新的特性。然而,WebGPU 将在未来添加这些新特性。
- WebGL 完全基于绘制图形并将它们渲染到画布的用例。它并不能很好地处理通用 GPU(GPGPU)的计算。GPGPU 计算对于很多不同的用例显得越来越重要,例如那些基于机器学习的模型。
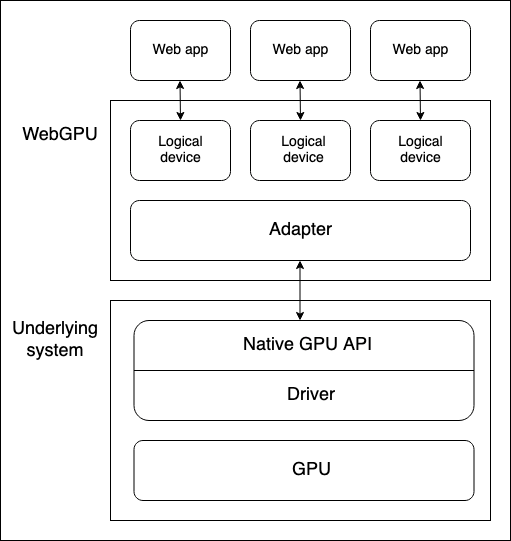
- 本机 GPU API 是操作系统(例如 macOS 上的 Metal)的一部分,是一种允许本机应用程序使用 GPU 功能的编程接口。API 指令通过驱动程序发送到 GPU(并接收响应)。一个系统可以有多个本机操作系统 API 和驱动程序可用于与 GPU 通信,尽管上述图示仅假设一个设备仅有一个本机 API/驱动器程序。
- 浏览器的 WebGPU 实现了通过本机 GPU API 与 GPU 进行通信。WebGPU 设配器在你的代码中实际上表示地是一个物理 GPU 和可利用的驱动程序。
- 逻辑设备是一种抽象,通过它,单个 web 应用程序可以以分区的方式访问 GPU 功能。逻辑设备需要提供复用的功能。因为一个物理设备的 GPU 可能同时被多个应用程序和进程使用,包括许多 web 引用程序。为了安全和逻辑上的原因,每个 web 应用程序都需要能够隔离地访问 WebGPU。
管线(pipeline)是一个逻辑结构,其包含在你完成程序工作的可编程阶段。 WebGPU 目前能够处理两种类型的管线:
用于渲染图形,通常渲染到 元素中,但它也可以在画面之外的地方渲染图形。 它有两个主要阶段:
- 顶点着色阶段:在该阶段中,顶点着色器(vertex shader)接受 GPU 输入的位置数据并使用像旋转、平移或透视等特定的效果将顶点在 3D 空间中定位。然后,这些顶点会被组装成基本的渲染图元,例如三角形等,然后通过 GPU 进行光栅化,计算出每个顶点应该覆盖在 canvas 上的哪些像素。
- 片元着色阶段:在该阶段中,片元着色器(fragment shader)计算由顶点着色器生成的基本图元所覆盖的每个像素的颜色。这些计算通常使用输入,如图像(以纹理的方式)提供表面细节以及虚拟化光源的位置和颜色。
用于通用计算。 计算管线包含单独的计算阶段,在该阶段中,计算着色器(compute shader)接受通用的数据,在指定数量的工作组之间并行处理数据,然后将结果返回到一个或者多个缓冲区。这些缓冲区可以包含任意类型的数据。
上面提到的着色器是通过 GPU 处理的指令集。WebGPU 着色器语言是用称为 WebGPU 着色器语言(WGSL)的低级的类 Rust 语言编写的。
WebGPU 着色器语言(WGSL)的低级的类 Rust 语言编写的。
Rust get-started Rust编程为什么如此流行 - 知乎 Rust是一门系统编程语言 [1] ,专注于安全 [2] ,尤其是并发安全,支持函数式和命令式以及泛型等编程范式的多范式语言。Rust在语法上和C++类似 [3] ,设计者想要在保证性能的同时提供更好的内存安全。 Rust最初是由Mozilla研究院的Graydon Hoare设计创造,然后在Dave Herman, Brendan Eich以及很多其他人的贡献下逐步完善的。 [4] Rust的设计者们通过在研发Servo网站浏览器布局引擎过程中积累的经验优化了Rust语言和Rust编译器。 [5]
创建这个新语言的目的是为了解决一个顽疾:软件的演进速度大大低于硬件的演进,软件在语言级别上无法真正利用多核计算带来的性能提升。Rust是针对多核体系提出的语言,并且吸收一些其他动态语言的重要特性,比如不需要管理内存,比如不会出现Null指针等等。 [17]
Rust致力于成为优雅解决高并发和高安全性系统问题的编程语言 [18] ,适用于大型场景,即创造维护能够保持大型系统完整的边界。这就导致了它强调安全,内存布局控制和并发的特点。标准Rust性能与标准C++性能不相上下。
每一次调用 gl.xxx 时,都会完成 CPU 到 GPU 的信号传递,改变 GPU 的状态,是立即生效的。熟悉计算机基础的朋友应该知道,计算机内部的时间和硬件之间的距离有多么重要,世人花了几十年时间无不为信号传递付出了努力,上述任意一条 gl 函数改变 GPU 状态的过程,大致要走完 CPU ~ 总线 ~ GPU 这么长一段距离。
一次使用framebuffer的webgl绘制过程
/**
* 把内容绘制在framebuffer中,再把他们当作是texture绘制
*/
let texture = this.initTexture(gl, programe,img)
gl.bindFramebuffer(gl.FRAMEBUFFER, framebuffer)
gl.viewport(...this.state.viewport[3])
this.resetGl(gl, [0.2, 0.2, 0.4, 1.0])
this.draw1(gl, programe, texture, framebuffer, buffer)
gl.viewport(0, 0, this.state.canvas.width, this.state.canvas.height);
this.resetGl(gl, [0.0, 0.0, 0.0, 1.0])
this.draw2(gl, programe, framebuffer.texture, framebuffer, buffer)我们都知道,办事肯定是一次性备齐材料的好,不要来来回回跑那么多遍,而 OpenGL 就是这样子的。有人说为什么要这样而不是改成一次发送的样子?历史原因,OpenGL 盛行那会儿 GPU 的工作没那么复杂,也就不需要那么超前的设计。
综上所述,WebGL 是存在 CPU 负载隐患的,是由于 OpenGL 这个状态机制决定的。
现代三大图形API 可不是这样,它们更倾向于先把东西准备好,最后提交给 GPU 的就是一个完整的设计图纸和缓冲数据,GPU 只需要拿着就可以专注办事。
WebGPU 虽然也有一个总管家一样的对象 —— device,类型是 GPUDevice,表示可以操作 GPU 设备的一个高层级抽象,它负责创建操作图形运算的各个对象,最后装配成一个叫 “CommandBuffer(指令缓冲,GPUCommandBuffer)”的对象并提交给队列,这才完成 CPU 这边的劳动。
所以,device.createXXX 创建过程中的对象时,并不会像 WebGL 一样立即通知 GPU 完成状态的改变,而是在 CPU 端写的代码就从逻辑、类型上确保了待会传递给 GPU 的东西是准确的,并让他们按自己的坑站好位,随时等待提交给 GPU。
指令缓冲对象具备了完整的数据资料(几何、纹理、着色器、管线调度逻辑等),GPU 一拿到就知道该干什么。


在 WebGPU 中,一个计算过程的任务就交由“管线”完成,也就是我们在各种资料里见得到的“可编程管线”的具象化 API;在 WebGPU 中,可编程管线有两类:
- 渲染管线,GPURenderPipeline
- 计算管线,GPUComputePipeline
const renderPipeline = device.createRenderPipeline({
// --- 布局 ---
layout: pipelineLayout,
// --- 五大状态用于配置渲染管线的各个阶段
vertex: {
module: device.createShaderModule({ /* 顶点着色器参数 */ }),
// ...
},
fragment: {
module: device.createShaderModule({ /* 片元着色器参数 */ }),
// ...
},
primitive: { /* 设置图元状态 */ },
depthStencil: { /* 设置深度模板状态 */ },
multisample: { /* 设置多重采样状态 */ }
})WebGL 没有通道 API
在一帧的渲染过程中,有可能需要多个通道共同完成渲染。最后一次 gl.drawXXX 的调用会使用一个绘制到目标帧缓冲的 WebGLProgram,这么说可能很抽象,不妨考虑这样一帧的渲染过程:
渲染法线、漫反射信息到 FBO1 中; 渲染光照信息到 FBO2 中; 使用 FBO1 和 FBO2,把最后结果渲染到 Canvas 上。 每一步都需要自己的 WebGLProgram,而且每一步都要全局切换各种 Buffer、Texture、Uniform 的绑定,这样就需要一个封装对象来完成这些状态的切换,可惜的是 WebGL 并没有这种对象,大多数时候是第三方库使用类似的类完成的。
在复杂的 Web 三维开发中,一个通道还不足以将想要的一帧画面渲染完成,这个时候要切换着色器程序,再进行 drawArrays/drawElements,绘制下一个通道,这样组合多个通道的绘制结果,就能在一个 requestAnimationFrame 中完成想要的渲染。
一次使用framebuffer的webgl绘制过程
/**
* 把内容绘制在framebuffer中,再把他们当作是texture绘制
*/
let texture = this.initTexture(gl, programe,img)
gl.bindFramebuffer(gl.FRAMEBUFFER, framebuffer)
gl.viewport(...this.state.viewport[3])
this.resetGl(gl, [0.2, 0.2, 0.4, 1.0])
this.draw1(gl, programe, texture, framebuffer, buffer)
gl.viewport(0, 0, this.state.canvas.width, this.state.canvas.height);
this.resetGl(gl, [0.0, 0.0, 0.0, 1.0])
this.draw2(gl, programe, framebuffer.texture, framebuffer, buffer)将一个通道内的行为(即管线)、数据(即资源绑定组和各种缓冲对象)分别创建,独立于通道编码器之外,这样,面对不同的通道计算时,就可以按需选用不同的管线和数据,进而甚至可以实现管线或者资源的共用。
编码指令缓冲的对象叫做 GPUCommandEncoder,即指令编码器,它最大的作用就是创建两种通道编码器(commandEncoder.begin[Render/Compute]Pass()),以及发出提交动作(commandEncoder.finish()),最终生成这一帧所需的所有指令。
// 创建指令编码器
const commandEncoder = device.createCommandEncoder()
{
// 阴影通道的编码过程
const shadowPass = commandEncoder.beginRenderPass(shadowPassDescriptor)
// 使用阴影渲染管线
shadowPass.setPipeline(shadowPipeline)
shadowPass.setBindGroup(0, sceneBindGroupForShadow)
shadowPass.setBindGroup(1, modelBindGroup)
shadowPass.setVertexBuffer(0, vertexBuffer)
shadowPass.setIndexBuffer(indexBuffer, 'uint16')
shadowPass.drawIndexed(indexCount)
shadowPass.end()
}
{
// 渲染通道常规操作
const renderPass = commandEncoder.beginRenderPass(renderPassDescriptor);
// 使用常规渲染管线
renderPass.setPipeline(pipeline)
renderPass.setBindGroup(0, sceneBindGroupForRender)
renderPass.setBindGroup(1, modelBindGroup)
renderPass.setVertexBuffer(0, vertexBuffer)
renderPass.setIndexBuffer(indexBuffer, 'uint16')
renderPass.drawIndexed(indexCount)
renderPass.end()
}
device.queue.submit([commandEncoder.finish()]);WebGL 的总管家对象是 gl 变量,它必须依赖 HTML Canvas 元素,也就是说必须由主线程获取,也只能在主线程调度 GPU 状态,WebWorker 技术的多线程能力只能处理数据,比较鸡肋。
WebGPU 改变了总管家对象的获取方式,adapter 对象所依赖的 navigator.gpu 对象在 WebWorker 中也可以访问,所以在 Worker 中也可以创建 device,也可以装配出指令缓冲,从而实现多线程提交指令缓冲,实现 CPU 端多线程调度 GPU 的能力。
WebGPU 出厂就带这玩意儿,通过计算着色器,使用 GPU 中 CU(Compute Unit,计算单元)旁边的共享内存,速度比普通的显存速度快得多。
- 创建着色器模块:在 WGSL 写你的着色器代码并将其打包到一个或者多个着色器模块。
- 获取和配置 canvas 上下文:获取 元素的 webgpu 上下文并将其配置为从你的 GPU 逻辑设备接收有关渲染的图形信息。如果你的应用程序没有图形输出(例如仅使用计算管线),则此步骤是不需要的。
- 创建包含你数据的资源:你想要通过你的管线处理的数据存储在 GPU 缓冲区或者纹理中,以供应用程序访问。
- 创建管线:定义管线描述符,详细地描述管线,包含所需的数据结构、绑定、着色器和资源布局,然后从中创建管线。我们的基本演示仅包含单个管线,但复杂的应用程序通常会包含多个用于不同目的的管线。
- 允许计算/渲染通道:这涉及许多子步骤: i. 创建一个指令编码器,它可以对一组传递给 GPU 的指令执行编码。 ii. 创建一个通道编码器对象,该对象用于发出计算/渲染指令。 iii. 运行指令,指定使用哪些管线、从哪个缓冲区获取数据、运行多少次绘制操作等。 iv. 完成指令列表后,将其封装到指令缓冲区中。 v. 通过逻辑设备的指令队列提交指令到缓冲区。
// 在异步函数中
const device = await adapter.requestDevice()
const buffer = device.createBuffer({
/* 装配几何,传递内存中的数据,最终成为 vertexAttribute 和 uniform 等资源 */
})
const texture = device.createTexture({
/* 装配纹理和采样信息 */
})
const pipelineLayout = device.createPipelineLayout({
/* 创建管线布局,传递绑定组布局对象 */
})
/* 创建着色器模块 */
const vertexShaderModule = device.createShaderModule({ /* ... */ })
const fragmentShaderModule = device.createShaderModule({ /* ... */ })
/*
计算着色器可能用到的着色器模块
const computeShaderModule = device.createShaderModule({ /* ... * / })
*/
const bindGroupLayout = device.createBindGroupLayout({
/* 创建绑定组的布局对象 */
})
const pipelineLayout = device.createPipelineLayout({
/* 传递绑定组布局对象 */
})
/*
上面两个布局对象其实可以偷懒不创建,绑定组虽然需要绑定组布局以
通知对应管线阶段绑定组的资源长啥样,但是绑定组布局是可以由
管线对象通过可编程阶段的代码自己推断出来绑定组布局对象的
本示例代码保存了完整的过程
*/
const pipeline = device.createRenderPipeline({
/*
创建管线
指定管线各个阶段所需的素材
其中有三个阶段可以传递着色器以实现可编程,即顶点、片段、计算
每个阶段还可以指定其所需要的数据、信息,例如 buffer 等
除此之外,管线还需要一个管线的布局对象,其内置的绑定组布局对象可以
让着色器知晓之后在通道中使用的绑定组资源是啥样子的
*/
})
const bindGroup_0 = deivce.createBindGroup({
/*
资源打组,将 buffer 和 texture 归到逻辑上的分组中,
方便各个过程调用,过程即管线,
此处必须传递绑定组布局对象,可以从管线中推断获取,也可以直接传递绑定组布局对象本身
*/
})
const commandEncoder = device.createCommandEncoder() // 创建指令缓冲编码器对象
const renderPassEncoder = commandEncoder.beginRenderPass() // 启动一个渲染通道编码器
// 也可以启动一个计算通道
// const computePassEncoder = commandEncoder.beginComputePass({ /* ... */ })
/*
以渲染通道为例,使用 renderPassEncoder 完成这个通道内要做什么的顺序设置,例如
*/
// 第一道绘制,设置管线0、绑定组0、绑定组1、vbo,并触发绘制
renderPassEncoder.setPipeline(renderPipeline_0)
renderPassEncoder.setBindGroup(0, bindGroup_0)
renderPassEncoder.setBindGroup(1, bindGroup_1)
renderPassEncoder.setVertexBuffer(0, vbo, 0, size)
renderPassEncoder.draw(vertexCount)
// 第二道绘制,设置管线1、另一个绑定组并触发绘制
renderPassEncoder.setPipeline(renderPipeline_1)
renderPassEncoder.setBindGroup(1, another_bindGroup)
renderPassEncoder.draw(vertexCount)
// 结束通道编码
renderPassEncoder.endPass()
// 最后提交至 queue,也即 commandEncoder 调用 finish 完成编码,返回一个指令缓冲
device.queue.submit([
commandEncoder.finish()
])
- Navigator.gpu 属性(或 WorkerNavigator.gpu,如果你在 worker 内部使用 WebGPU 功能)为当前上下文返回 GPU 对象。
- 通过 GPU.requestAdapter() 方法访问适配器。该方法接受一个可选的设置对象,其允许你请求一个高性能或者低功耗的适配器。如果没有可选的对象,设备将提供对默认适配器的访问,这对于大多数用途来说足够了。
- 设备可以通过 GPUAdapter.requestDevice() (en-US) 请求。该方法接受一个可选的对象(称为描述符),该设备可以用于指定你想要逻辑设备具有的确切特性和限制。如果没有可选的对象,所提供的设备将使用合理的通用的规则,这对于大多数用途来说够了。