Replace Second Delta Beta Cut with DNN #126
Conversation
|
/run all |
|
The PR was built and ran successfully in standalone mode. Here are some of the comparison plots.
The full set of validation and comparison plots can be found here. Here is a timing comparison: |
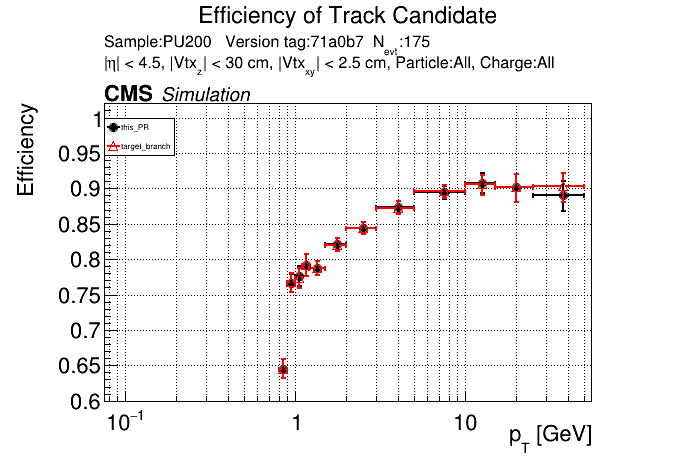
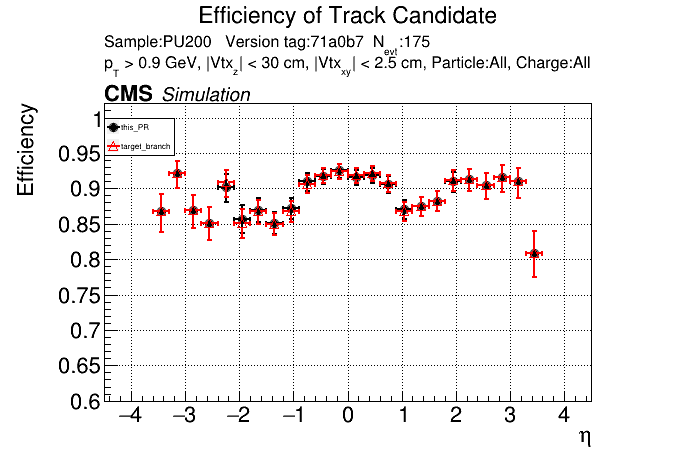
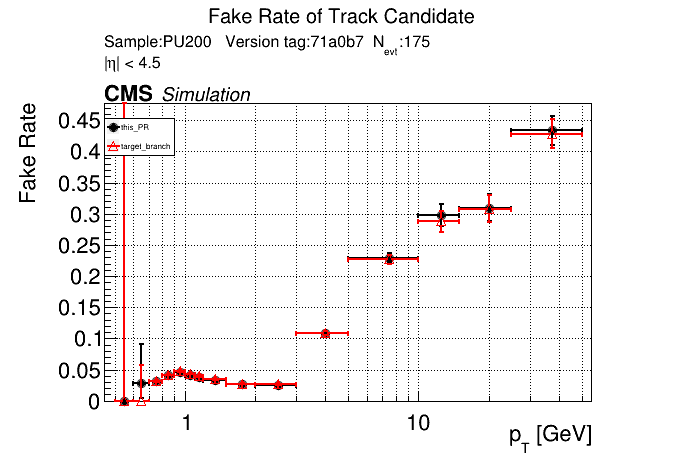
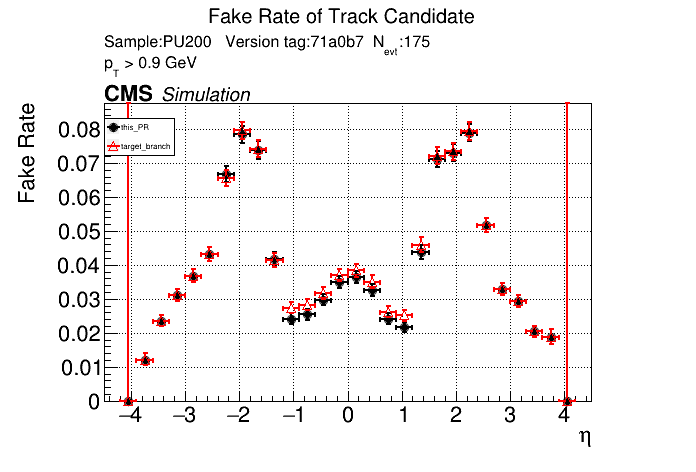
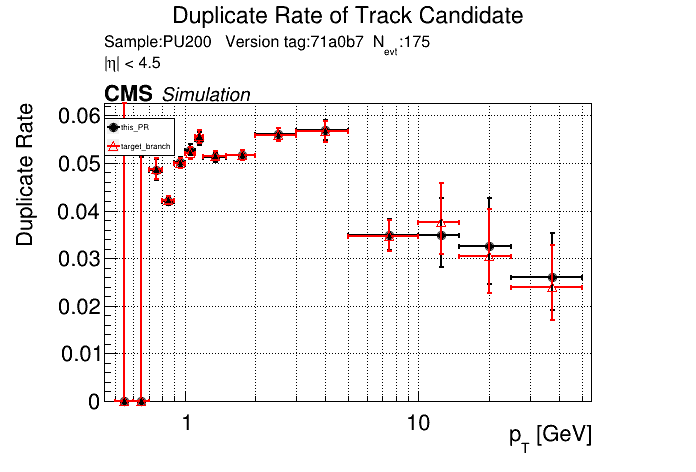
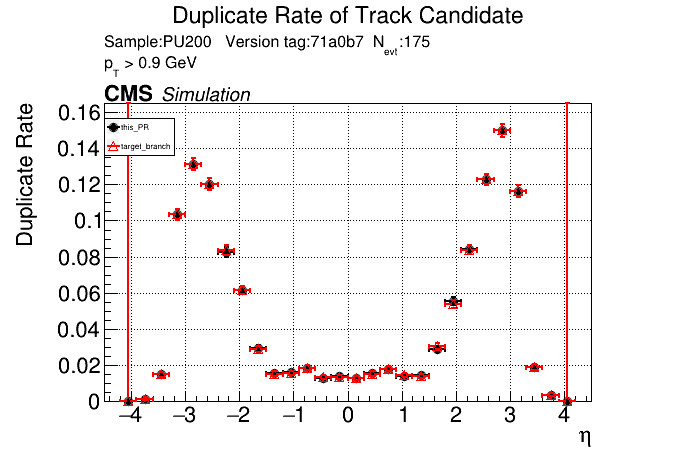
|
The PR was built and ran successfully with CMSSW. Here are some plots. OOTB All Tracks
The full set of validation and comparison plots can be found here. |
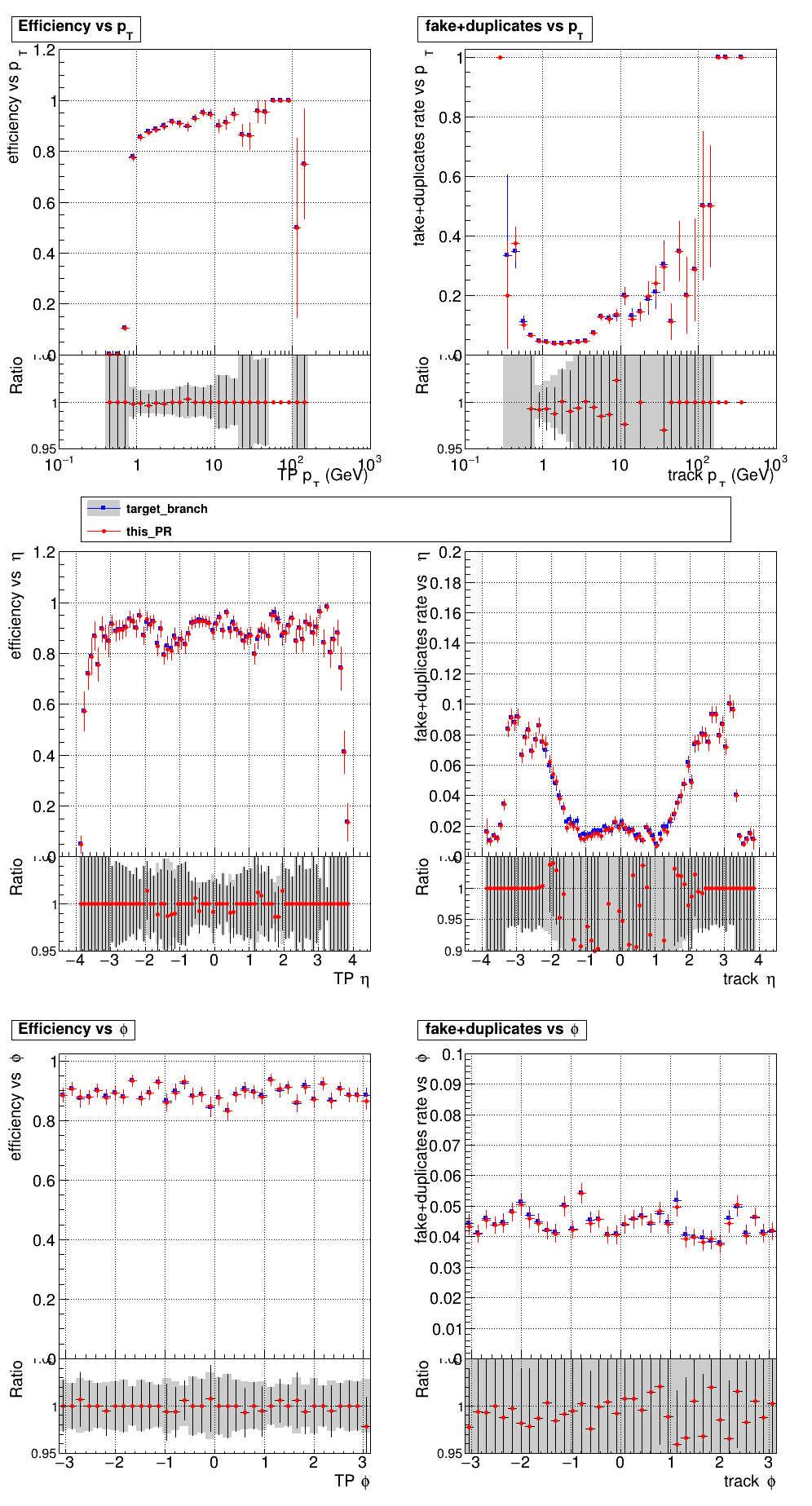
|
@slava77 It looks like this method of downsampling 80% tracks works for the second delta beta cut, but not for the first delta beta cut. It seems like the more underlying issue is network size when training on the larger sample. If I increase network size substantially it fixes the issue without having to downsample tracks, although I think it would take a substantial amount of effort to make a larger model that has competitive timing to the current hybrid approach. Closing this PR for now. I'm going to shift my focus to work on loading the weights properly and hopefully getting a timing improvement with lower precision weights. |
|
Here is the big dnn code with associated training notebook for future reference. |
two more layers and double the hidden features; right? |
The number of parameters increases by a factor of ~7.6x, the t5 timing increases by a factor of 12x (1ms->12ms). I didn't check to see if a smaller network also fixes the issue though. |
running a profiler may help. |
On the 1000 event RelVal plots (not shown here yet) this PR leads to a higher efficiency at a lower FR. Considering that issue #123 was fixed though, I think it makes sense to only merge this PR if I can replace both delta beta cuts at a performance improvement. Leaving this PR as a draft for now.
Continuation of PR #122, although I heavily downsample 80% matched tracks during training in this PR to get better overall performance and a DNN cut more similar to the existing delta beta cuts.
Edit: It looks like this method of downsampling 80% tracks works for the second delta beta cut, but not for the first delta beta cut. It seems like the more underlying issue is network size when training on the larger sample. If I increase network size substantially it fixes the issue without having to downsample tracks, although I think it would take a substantial amount of effort to make a larger model that has competitive timing to the current hybrid approach. Closing this PR for now. I'm going to shift my focus to work on loading the weights properly and hopefully getting a timing improvement with lower precision weights.