This repo implement the caffe code refers to the paper of
Fixing Weight Decay Regularization in AdamarXiv.
id from 712 to ...
modify caffe.proto as below:
// If true, adamw solver will restart per cosine decay scheduler
optional bool with_restart = 712 [default = false];
// cosine decay, refers to paper of AdamWR
optional int32 cosine_decay_steps = 713 [default = 1000];
optional int32 cosine_decay_mult = 714 [default = 2];
modify caffe.proto as below:
enum SolverType {
SGD = 0;
NESTEROV = 1;
ADAGRAD = 2;
RMSPROP = 3;
ADADELTA = 4;
ADAM = 5;
ADAMWR = 6; // added
}
modify sgd_solvers.hpp as below:
template<typename Dtype>
class AdamWRSolver : public SGDSolver<Dtype> {
public:
explicit AdamWRSolver(const SolverParameter ¶m)
: SGDSolver<Dtype>(param) { AdamWRPreSolve(); }
explicit AdamWRSolver(const string ¶m_file)
: SGDSolver<Dtype>(param_file) { AdamWRPreSolve(); }
virtual inline const char *type() const { return "AdamWR"; }
protected:
void AdamWRPreSolve();
virtual void ComputeUpdateValue(int param_id, Dtype rate);
DISABLE_COPY_AND_ASSIGN(AdamWRSolver);
};
add adamwr_solver.cpp and adamwr_solver.cu to src/caffe/solvers/. some differents between adam and adamwr showed below
3.1 fixed weight decay regularization in Adam
// yita: schedule multiplier, alpha: learning policy
// adding yita, yita * weight_decay * weight which is different from adam
// update weight{t} <- weight{t-1} - yita(alpha * m{t} / (v{t} + delta) + local_weight_decay * weight{t-1})
// AdamWR differs from Adam
caffe_cpu_scale(N, local_rate * correction,
val_t->cpu_data(),
val_t->mutable_cpu_data());
// Y = alpha * X + Y
caffe_axpy(N, local_decay, net_params[param_id]->cpu_data(), val_t->mutable_cpu_data());
// Y = yita * X
caffe_cpu_scale(N, yita, val_t->cpu_data(), net_params[param_id]->mutable_cpu_diff());
3.2 schedule multiplier yita(fixed, decay, warm restart)
// warm restart
// yita = 0.5 + 0.5 * cos(pi * T_cur / T_i)
Dtype yita(0.5 + 0.5 * std::cos((std::acos((double(-1))) * T_cur) / T_i));
3.3 add cuda layer of AdamWR
template <typename Dtype>
__global__ void AdamWRUpdate(int N, Dtype* theta, Dtype* g, Dtype* m, Dtype* v,
Dtype beta1, Dtype beta2, Dtype eps_hat, Dtype corrected_local_rate, Dtype local_decay, Dtype yita) {
CUDA_KERNEL_LOOP(i, N) {
float gi = g[i];
float mi = m[i] = m[i]*beta1 + gi*(1-beta1);
float vi = v[i] = v[i]*beta2 + gi*gi*(1-beta2);
g[i] = yita * ((corrected_local_rate * mi / (sqrt(vi) + eps_hat)) + local_decay * theta[i]);
// g[i] = corrected_local_rate * mi / (sqrt(vi) + eps_hat);
}
}
4.1 hyperparameters newed
- with_restart
- cosine_decay_steps
- cosine_decay_mult
4.2 proposal hyperparamters
- lr_policy: "poly"
- base_lr: 0.001
- momentum: 0.9
- momentum2: 0.999
- weight_decay: 0.0005
- with_restart: true (false will set yita = 1 fixedly)
- cosine_decay_steps: 10000 (change it to observe results)
- cosine_decay_mult: 2
- type: "AdamWR"
4.3 others to take note
if you use lr_policy of step, you should take note hyperparameter of gamma, which may make loss value boomed if you use proposal value, 0.1. Perhaps, you can set gamma to 0.9 instead.
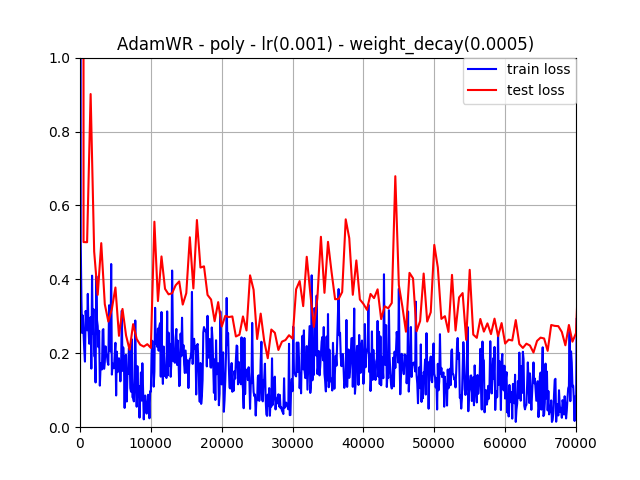
.png)
.png)
.png)
conclusion: we can observe to find comparing to solvers of Adam and SGD, AdamWR gets faster speed of convergence. And addition to warm restart, AdamWR can skip out trap of local optimal value and get a better local optimal perhaps. So, AdamWR gets less possibility to overfitting rather than Adam and SGD.
submitting issues or contacting with me ([email protected])
If this repo can help you, welcome to star and fork.