On average, we take eight thousand steps each day; during walking, running, and other physical activities, our entire body weight relies on the support of our feet. If the feet are not healthy, it can lead to an imbalance in body alignment, potentially affecting gait and posture, and ultimately causing various types of foot pain and lower back pain. The dataset provides multiple sets of foot pressure data. Each set includes data for both the left and right foot (each with two annotated points). We will use deep learning techniques to develop a model that identifies and labels these two annotation points.
The dataset was generously provided by Shui-Mu International Co. Ltd. Each sample comprised an image depicting foot pressure and two corresponding coordinates. [link: 人工智慧共創平台 (aidea-web.tw)]
The training set consisted of 1000 samples, while the validation set comprised 424 samples, and the test set encompassed 1000 samples, as illustrated in following figure.

The images illustrating foot pressure with two red dots, representing the forefoot and heel apexes, are depicted in the following figure.

The model we used is Inception V3[1] by Google (without pretrained weights). The model architecture is shown below:
The Main Architecture :
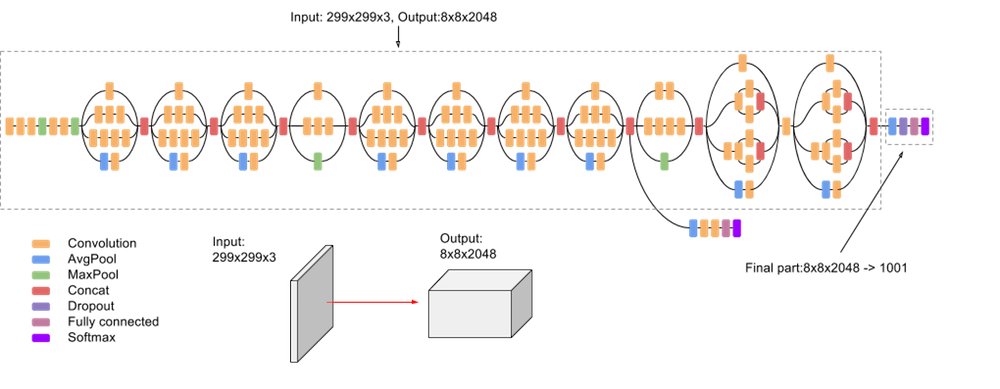
We replaced the fully connected layer with our own. We took the Inception V3 output (size 2048) and connected it to a fully connected layer with a width of 10, which was then passed to the output layer to produce four regression values.
Due to the limited availability of training data, with only 1000 samples, we performed data augmentation by flipping the images along the x-axis, y-axis, and both axes. Without this augmentation, the model could not converge to an optimal solution.
We also resized the image width to 299 pixels to match the model input size. First, we converted the image to a tensor and normalized it with mean values of [0.485, 0.456, 0.406] and standard deviation values of [0.229, 0.224, 0.225] for the RGB channels, as specified in the original paper[1]. The results are shown in the following image.

We trained the model with the following hyperparameters:
| Hyperparameter | Value |
|---|---|
| Batch Size | 32 |
| Learning Rate | 1e-4 |
| Epochs | 500 |
The model performed well enough after approximately 250 epochs.

Our model's predictions achieved a Euclidean distance error of 10.273243, achieved rank 10 on the AIdea leader board.

Here are the predictions:

[1] Szegedy, C., Vanhoucke, V., Ioffe, S., Shlens, J., & Wojna, Z. (2015, December 2). Rethinking the inception architecture for computer vision. arXiv.org. https://arxiv.org/abs/1512.00567