We recommend at least 4GB of RAM (at least 8GB, or better yet 16GB or more is recommended) Neo4j on its own requires a minimum of 2GB of RAM (16GB or better recommended) according to official documentation
During test runs, simply bringing the full BirdSpider stack up with no tasks running used slightly over 1GB of RAM. This usage rose further when tasks were running.
For quick deployment (for testing, or for small scale production use) BirdSpider can be deployed in Docker as outlined below using the Dockerfiles and docker-compose included in the project. For larger installations, it may be desirable to split out and run the Neo4j and Solr containers separately to the BirdSpider tasks (which run on Celery and Redis). This can be done by changing the appropriate settings for the locations of the Neo4j and Solr hosts .
Make sure you have Docker and Docker Compose installed. Clone the repository, make a copy of the example "run.sh" script, then build/pull the containers.
git clone https://github.com/augeas/BirdSpider.git
cd BirdSpider
cp eg_run.sh run.sh
docker-compose build
You will need to apply for a Twitter development account and create a new app. Then you can fill in the credentials in "run.sh". You should also change a Neo4j password and probably increase its container's RAM.
NEO_USER=neo4j \
NEO_PW=birdspider \
NEO_RAM=2G \
CONSUMER_KEY=CONSUMER_KEY \
CONSUMER_SECRET=CONSUMER_SECRET \
OAUTH_TOKEN=OAUTH_TOKEN \
OAUTH_TOKEN_SECRET=OAUTH_TOKEN_SECRET \
ACCESS_TOKEN=ACCESS_TOKEN \
docker-compose run --rm birdspider celery worker -l info -A app
Now you can start the database and Celery worker:
./run.sh
The crawler is controlled by a set of Celery tasks. Before starting any tasks, you should verify that Neo4j is running by visiting the "NEO_HOST" host in a web Browser and logging in with the credentials specified in "run.sh". By default this uses application level OAUTH2 authorization. See later is this guide for OAUTH1 instructions. Having installed celery, you can call the tasks by name. To get all the Tweets for the @emfcamp account:
from celery import Celery
app = Celery('birdspider', broker='redis://localhost:6379', backend='redis://localhost:6379')
app.send_task('twitter_tasks.getTweets', args=['emfcamp'])The tweets for the account will be visible in the Neo4j Browser when you expand the account's node by clicking on it. Find the node with the Cypher query:
MATCH (n:twitter_user {screen_name: 'emfcamp'}) RETURN n
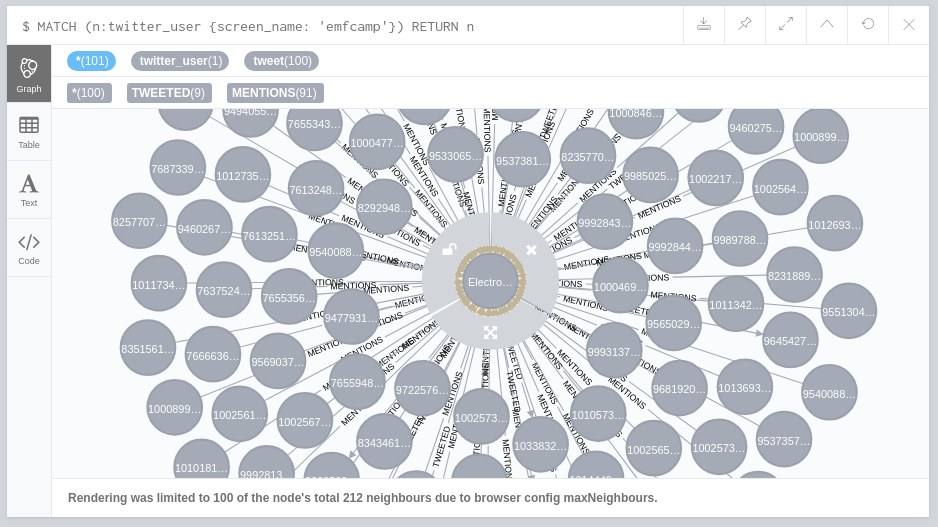
To start a user scrape, call the celery twitter_task seedUser with scrape='True'
from celery import Celery
app = Celery('birdspider', broker='redis://localhost:6379', backend='redis://localhost:6379')
app.send_task('twitter_tasks.seedUser', args=['emfcamp', 'True'])A user scrape has a stopping condition within it, but you may sometimes wish to stop a scrape early. Scraping a user checks that the cache key user_scrape == 'true' to signal 'keep going' If you wish to halt a running scrape before it finishes, for the moment you should change this key to 'false'. To do this you will need to keep the task_id returned as the result of calling Celery app.send_task
result = app.send_task(task_name,args=[arg0,arg1..., argn]) task_id = result.task_id
this can now be called as a celery task
from celery import Celery
app = Celery('birdspider', broker='redis://localhost:6379', backend='redis://localhost:6379')
task_id = 'id of the task you wish to stop here'
app.send_task('twitter_tasks.stop_scrape', args=[task_id])this can also be done by directly editing the cache keys in redis
import redis
# assuming redis is accessible on localhost, substitute hostname as appropriate
task_id = 'root task id of seedUser task you want to stop goes here'
cache = redis.StrictRedis(host='localhost')
cache.set('user_scrape_' + task_id, 'false')Please see the Twitter API documentation for details on possible search term formats There are optional keyword arguments as well as the search terms the most useful ones have the following defaults if not overridden: page_size=100 lang='en' maxTweets=False (search will not cut itself off before hitting the twitter API limit on a search result, can instead be set to a numeric value to limit the total number of tweets returned) Below are examples both just using the defaults and using the keyword args:
from celery import Celery
app = Celery('birdspider', broker='redis://localhost:6379', backend='redis://localhost:6379')
app.send_task('twitter_tasks.search', args=['#emfcamp'])
app.send_task('twitter_tasks.search', args=['#emfcamp'], kwargs={'maxTweets' : 300})As noted above by default BirdSpider now uses application level OAUTH2 authorisation for Twitter API calls. This means all calls are using one single rate limit on calls. User level OAUTH1 calls can be used to spread calls across multiple rate limits, as each user will have their own rate limit. Note: the user should have authorised the application, also note that at the moment this is not securing or encrypting the keys and that fact needs fixing!
example is for scraping a user
import json
from celery import Celery
credentials = {
'oauth1_token': 'your_user_oauth_token_here',
'oauth1_secret': 'your_user_oauth_secret_here',
}
app = Celery('birdspider', broker='redis://localhost:6379', backend='redis://localhost:6379')
app.send_task('twitter_tasks.seedUser', args=['emfcamp', 'True'], kwargs={ 'credentials': json.dumps(credentials)})The filter stream task requires user level OAUTH1 credentials to run (all other twitter API calls can use either OAUTH2 or OAUTH1)
The twitter filter API call can be accessed from BirdSpider. See Twitter's API documentation for limitation on the filter terms
Be certain to save the task_id for the job that starts the filter stream, as you will need to to request BirdSpider to stop streaming tweets.
import json
from celery import Celery
app = Celery('birdspider', broker='redis://localhost:6379', backend='redis://localhost:6379')
credentials = {
'oauth1_token': 'your_user_oauth_token_here',
'oauth1_secret': 'your_user_oauth_secret_here',
}
result = app.send_taskapp.send_task('twitter_tasks.start_stream', kwargs={'track': '#RevokeArticle50', 'credentials': json.dumps(credentials)})
task_id = result.task_id
....
To stop a filter stream
Use the task_id saved when starting the stream.
BirdSpider will kill the task that is streaming from Twitter via the filter API call.
This stops new tweets being added to the pile needing to be processed, but allows any other tasks
that have already started to process prior tweets in the stream to finish what they are doing.
(Please note that any tweets streamed but not yet sent to another task for processing are simply dropped as
though they had not been streamed.)
Presuming you are still in the same python session as when you requested the stream to start do the following.
(otherwise, re-do the steps to start python and set up a celery app. You will not need twitter credentials.
Then set task_id = the task_id you saved above)app.send_task('twitter_tasks.stop_stream', args=[task_id]) ....
from celery import Celery
app = Celery('birdspider', broker='redis://localhost:6379', backend='redis://localhost:6379')
app.send_task('clustering_tasks.cluster', args=['emfcamp', 'twitter_user', 'TransFoF'])Cypher queries to view the clustering results:
all clustering nodes: (clusters are members of the clustering run that created them)
MATCH (n:clustering) RETURN n
clustering for a given seed user:
MATCH p=(n:twitter_user {screen_name: 'Dino_Pony'})-[r:SEED_FOR]->() RETURN p LIMIT 25