
Στοιχεία για τον επεξεργαστή όπου προσωμειώνει ο gem5 μπορούμε να βρούμε στο αρχείο starter.py και πιο συγκεκριμένα από τον φάκελο common και το αρχείο options.py. Παρακάτω παρατίθενται τα μεγέθη των caches :
- L1 instruction : ("-- l1i_size", type="string", default="32kB")
- L1 Data : ("-- l1d_size", type="string", default="64kB")
- L2 cache : ("-- l2_size", type="string", default="2MB")
Tο associativity κάθε μίας από αυτές:
- L1 instruction : ("-- l1i_assoc", type="int", default=2)
- L1 Data : ("-- l1d_assoc", type="int", default=2)
- L2 cache : ("-- l2_assoc", type="int", default=8)
Και το μέγεθος της cache line : ("-- cacheline_size", type="int", default=64)
Για κάθε ένα από τα παρακάτω benchmarks παρατηρούμε τα εξής:
-
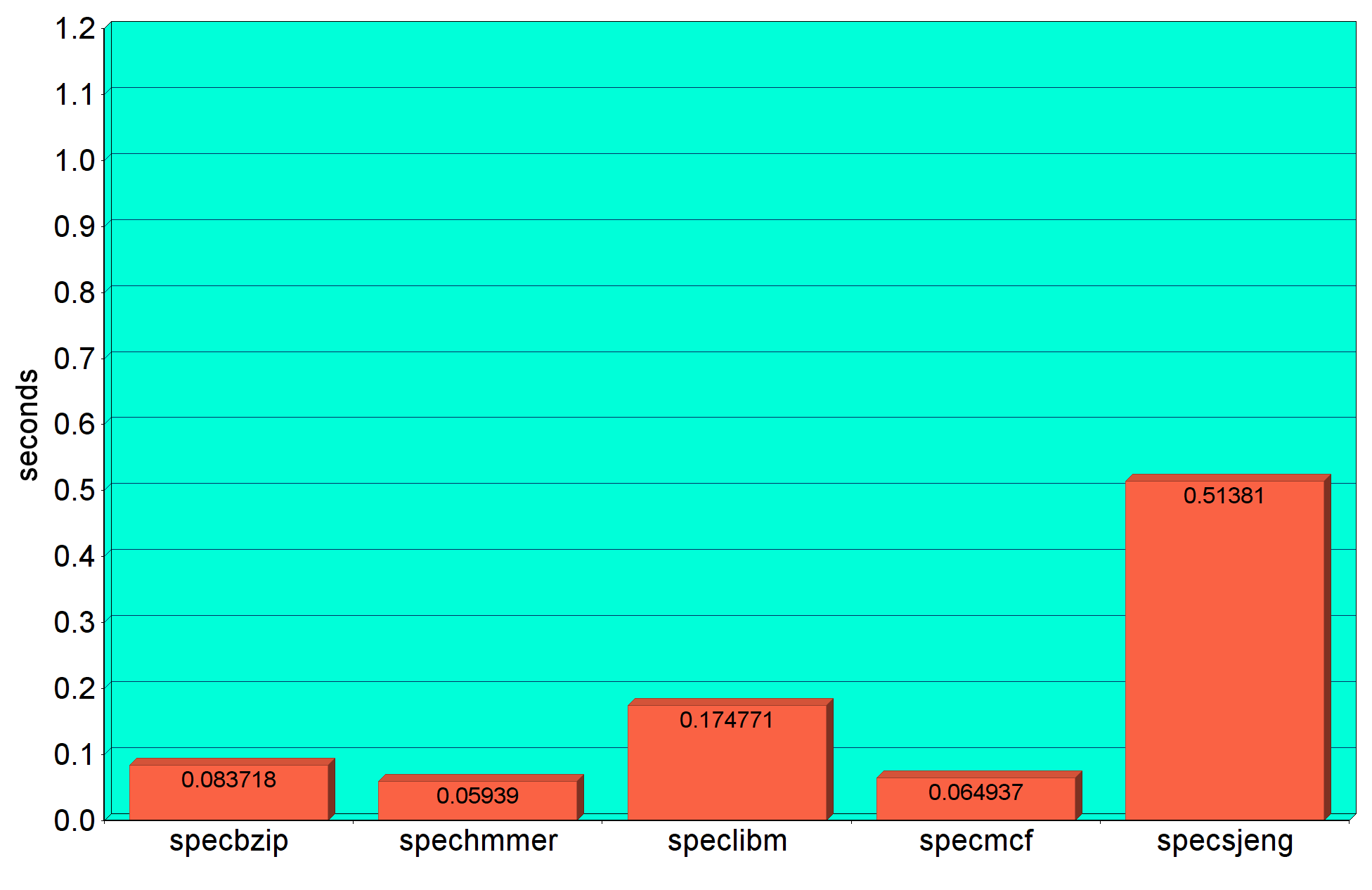
specbzip :
- χρόνος εκτέλεσης : 0.083718 seconds
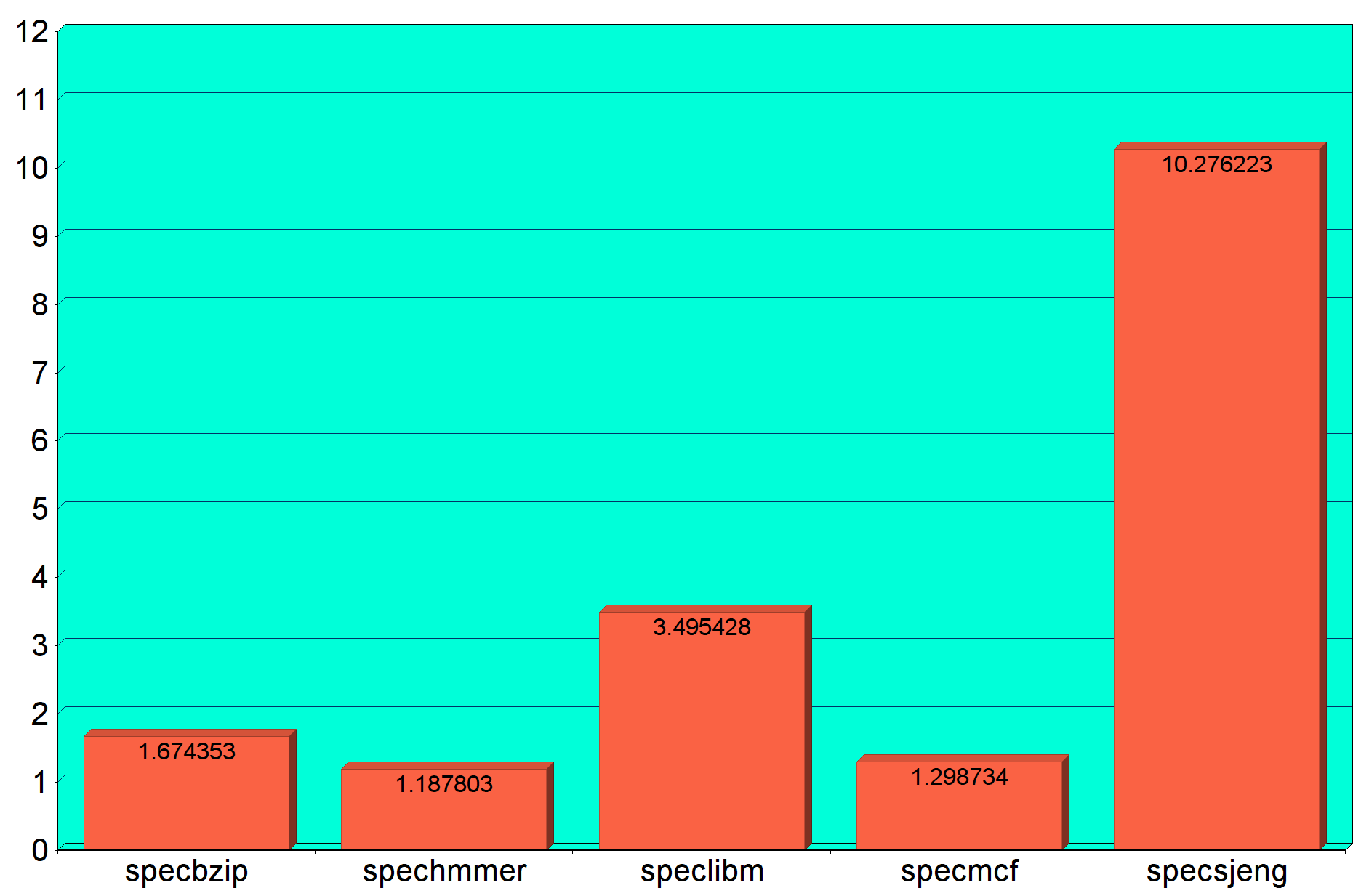
- CPI (cycles per instruction) : 1.674353
- συνολικά miss rates :
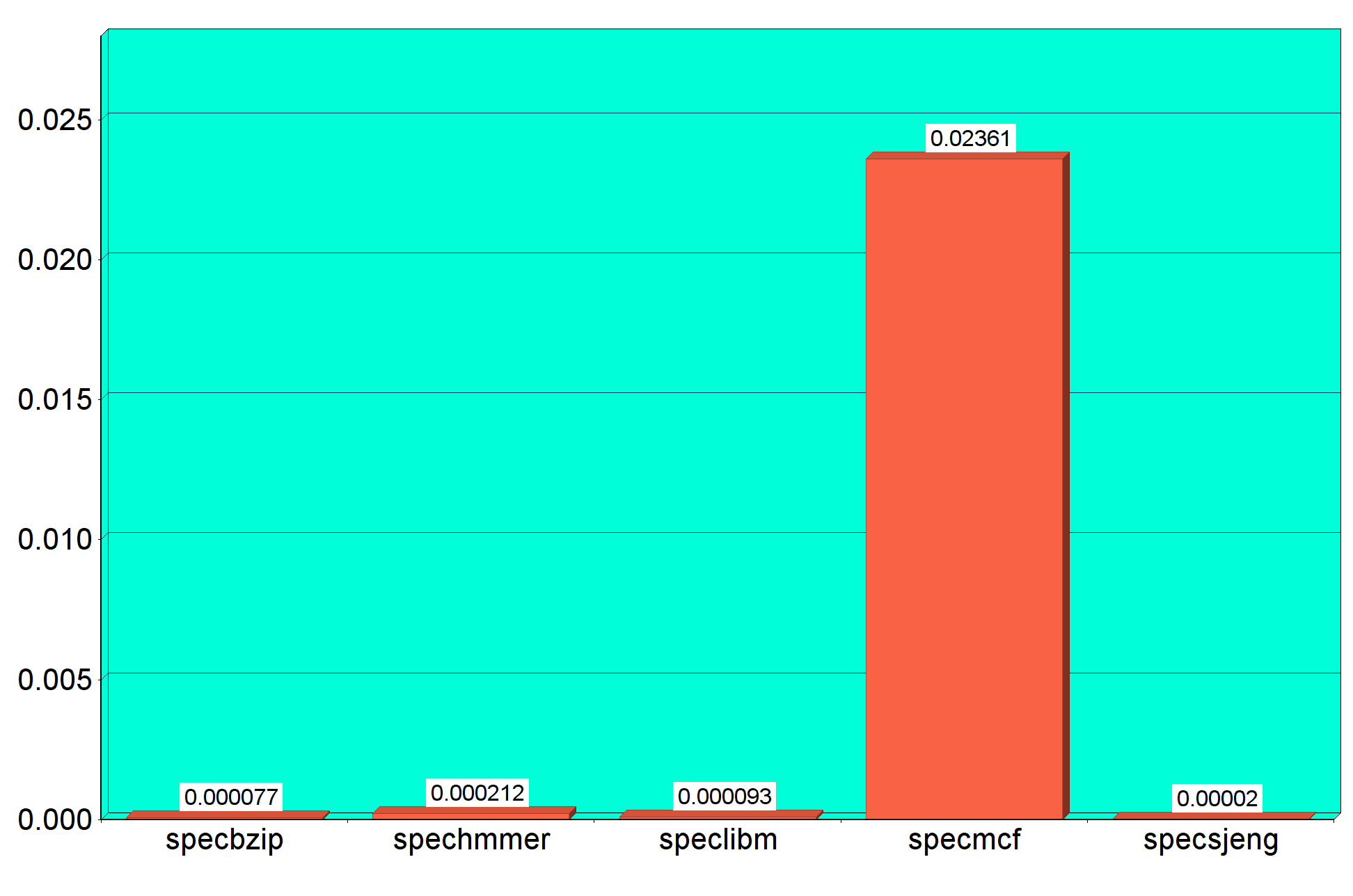
- L1 instruction : 0.000077
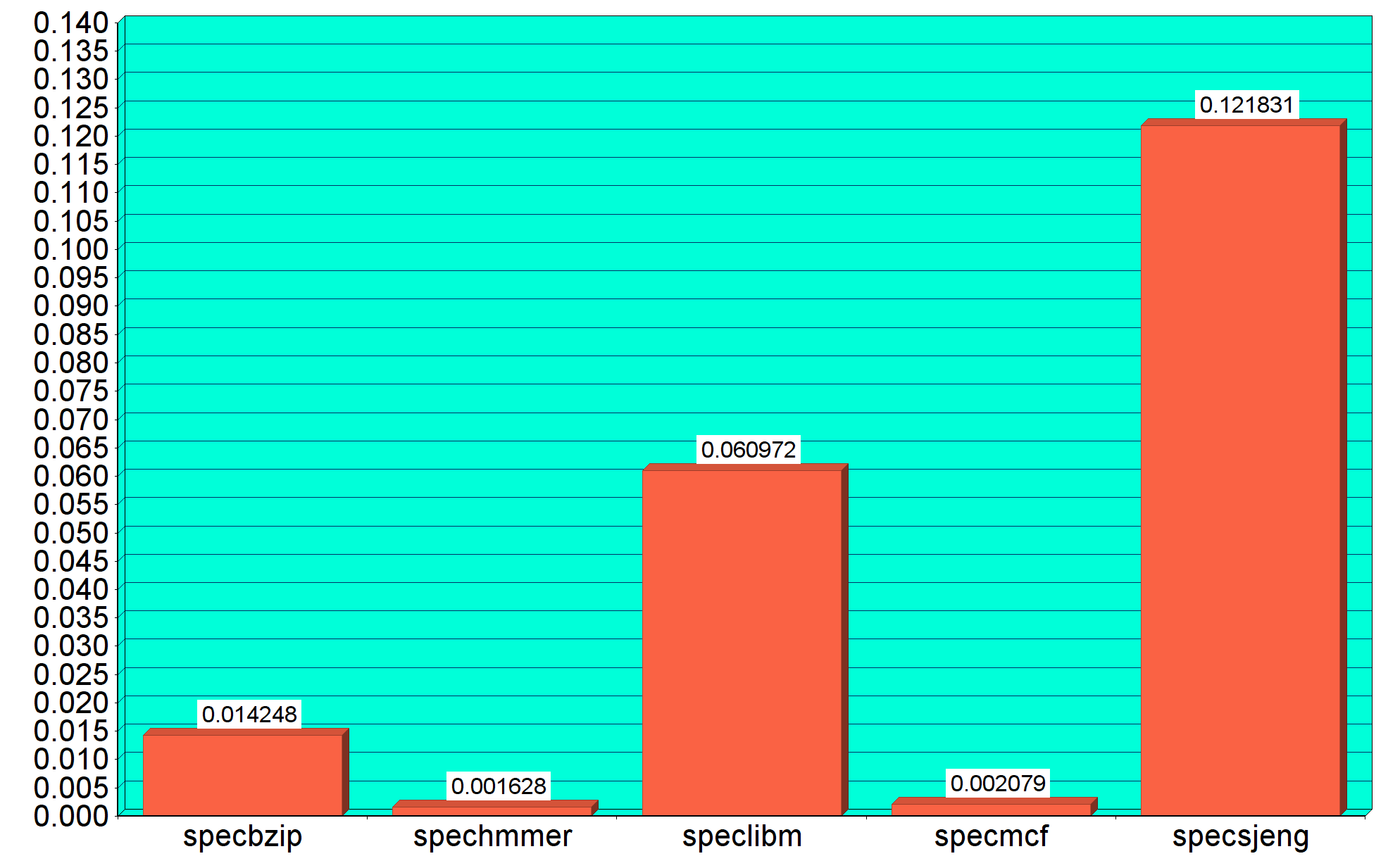
- L1 Data : 0.014248
- L2 cache : 0.295243
-
spechmmer :
- χρόνος εκτέλεσης : 0.059390 seconds
- CPI (cycles per instruction) : 1.187803
- συνολικά miss rates :
- L1 instruction : 0.000212
- L1 Data : 0.001628
- L2 cache : 0.078296
-
speclibm :
- χρόνος εκτέλεσης : 0.174771 seconds
- CPI (cycles per instruction) : 3.495428
- συνολικά miss rates :
- L1 instruction : 0.000093
- L1 Data : 0.060972
- L2 cache : 0.999944
-
specmcf :
- χρόνος εκτέλεσης : 0.064937 seconds
- CPI (cycles per instruction) : 1.298734
- συνολικά miss rates :
- L1 instruction : 0.023610
- L1 Data : 0.002079
- L2 cache : 0.055082
-
specsjeng :
- χρόνος εκτέλεσης : 0.51381 seconds
- CPI (cycles per instruction) : 10.276223
- συνολικά miss rates :
- L1 instruction : 0.000020
- L1 Data : 0.121831
- L2 cache : 0.999972
Χρόνος εκτέλεσης
CPI (Cycles per instruction)
L1 instruction cache miss rate
L1 data cache miss rate
L2 cache miss rate
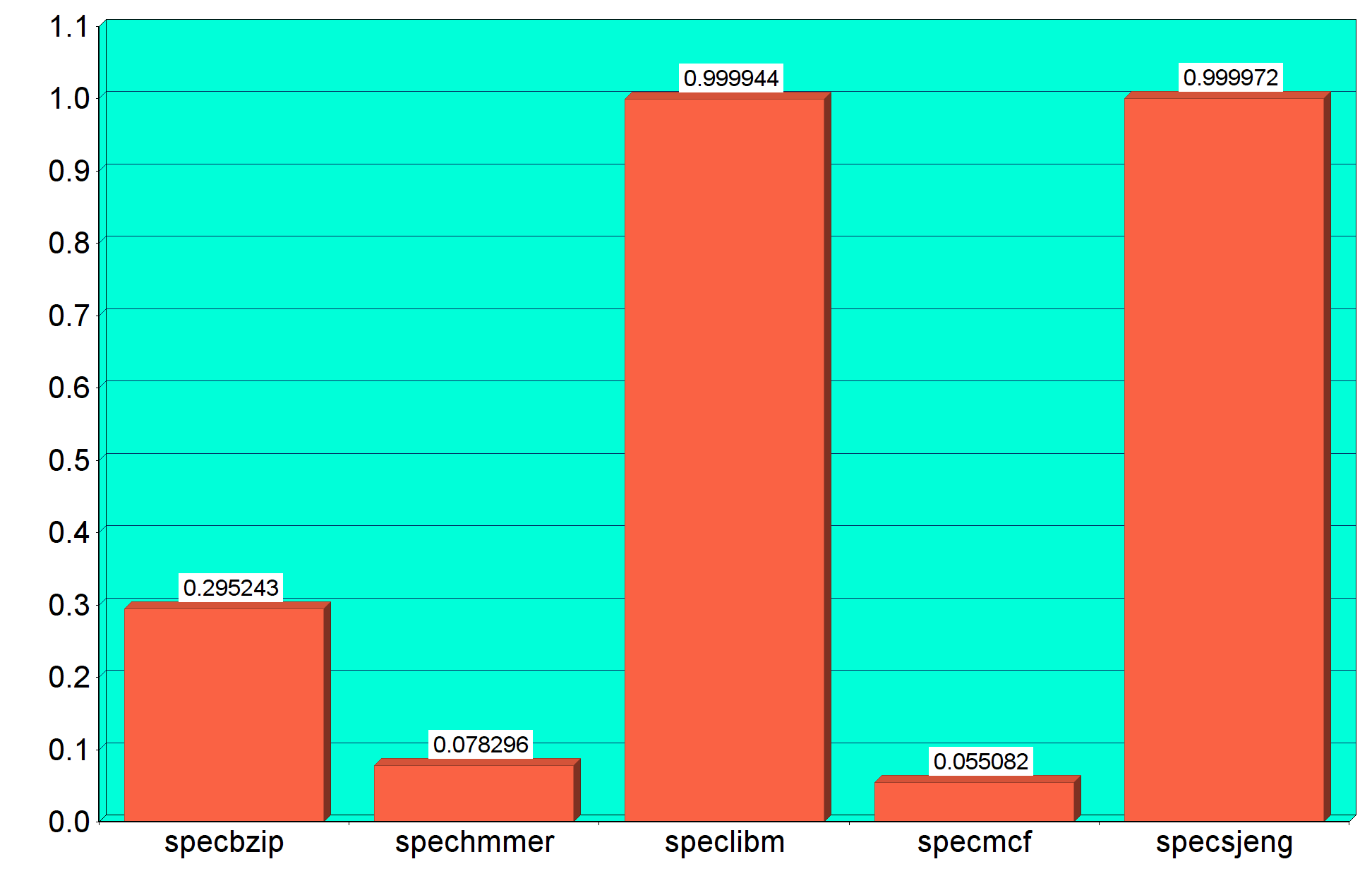
Από τα γραφήματα παρατηρούμε ότι το specsjeng είναι το πιο αργό benchmark και έχει και τα
μεγαλύτερα cache miss rates στις L2,L1 data, ενώ το μικρότερο σε L1 instruction. Ωστόσο το μεγαλύτερο L1 instruction miss rate παρατηρείται στο specmcf. Επιπλέον μπορούμε να συμπαιράνουμε ότι όσο μεγαλύτερο χρόνο εκτέλεσης έχει το benchmark, ανάλογα είναι και τα CPI,L1 Data και L2 cache miss rates, ενώ το L1 instruction miss rate είναι ανεξάρτητο.
Από τα αρχεία stats.txt των benchmarks παρατηρούμε ότι το system_clock παραμένει στο 1GHz, ενώ το cpu_clock είναι αυτό που αλλάζει. Από το αρχείο config.json προκύπτει ο ίδιο συμπέρασμα, και αυτό συμβαίνει διότι αυτό που μας ενδιαφέρει να ρυθμίσουμε είναι το cpu_clock καθώς εκεί εκτελούντε τα instructions και γενικότερα το πρόγραμμα. Αν προσθέσουμε έναν ακόμα επεξεργαστή η συχνότητα του θα είναι 2GHz.
Οι χρόνοι εκτέλεσης φαίνονται στον παρακάτω πίνακα :
| benchmarks | 1GHz | 2GHz |
|---|---|---|
| specbzip | 0.1604 | 0.0837 |
| spechmmer | 0.1185 | 0.0593 |
| speclibm | 0.2622 | 0.1747 |
| spemcf | 0.1278 | 0.0649 |
| specsjeng | 0.7054 | 0.5138 |
Παρατηρούμε ότι στα specbzip, spechmmer, spemcf είναι σχεδόν 2 φορές πιο γρήγορο όταν 2πλασιάζουμε την συχνότητα. Ωστόσο στα speclibm, specsjeng, η αναλογία δεν είναι η ίδια. Επίσης σε αυτά τα δύο παρατηρούμε τα μεγαλύτερα L1 Data, L2 cache miss rates. Οπότε παρατηρούμε ότι το μεγάλο miss rate στις caches επηρεάζει και επιβραδύνει πολύ το πρόγραμμα, το οποίο είναι φυσιολογικό καθώς ο επεξεργαστής πρέπει να ανατρέξει αλλού να βρει αυτό που ψάχνει (από L1 -> L2 , και από L2 -> κύρια μνήμη), ανεξαρτήτως δηλαδή αν αυξήσουμε την συχνότητα, το όφελος είναι μικρό.
Σε αυτό το βήμα τροποποιούμε τις παραμέτρους των επεξεργαστών ώστε να μειώσουμε όσο γίνεται τους χρόνους εκτέλεσης και τα CPI των benchmarks. Για τη δημιουργία των γραφημάτων δημιουργήθηκε ένα script στo matlab.
Πιο συγκεκριμένα για το benchmark specbzip, δημιουργούμε τους παρακάτω συνδυασμούς παραμέτρων, όπου ο κάθε αριθμός αντιπροσωπεύει και έναν διαφορετικό συνδυασμό με τον αριθμό 1 να είναι τα αποτελέσματα από τις εκτελέσεις του προηγούμενου βήματος. Για τις εκτελέσεις των διαφορετικών commands δημιουργήθηκε ένα bash script :
- 2 -> l1_assoc=1 , l2_assoc=2, cacheline=64 ,l1i_size=64 ,l1d_size=32 , l2_size=512
- 3-> l1_assoc=8 , l2_assoc=16, cacheline=64 ,l1i_size=64 ,l1d_size=32 , l2_size=512
- 4 -> l1_assoc=64 , l2_assoc=64, cacheline=64 ,l1i_size=64 ,l1d_size=32 , l2_size=512
- 5 -> l1_assoc=2 , l2_assoc=8, cacheline=32 ,l1i_size=64 ,l1d_size=32 , l2_size=512
- 6 -> l1_assoc=4 , l2_assoc=16, cacheline=64 ,l1i_size=32 ,l1d_size=64 , l2_size=1MB
- 7 -> l1_assoc=4 , l2_assoc=16, cacheline=64 ,l1i_size=128 ,l1d_size=32 , l2_size=4MB
- 8 -> l1_assoc=8 , l2_assoc=16, cacheline=32 ,l1i_size=64 ,l1d_size=32 , l2_size=1MB
Στις l1d cache & l1i cache χρησιμοποιούμε την ίδια τιμή στο associetivity, και --cpu-clock=2GHz (default).
Παρακάτω προκύπτουν τα ακόλουθα γραφήματα :
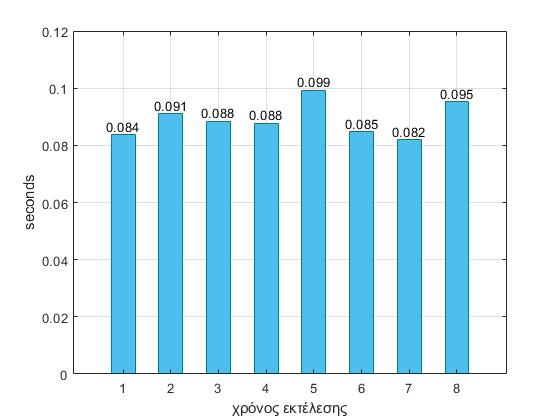
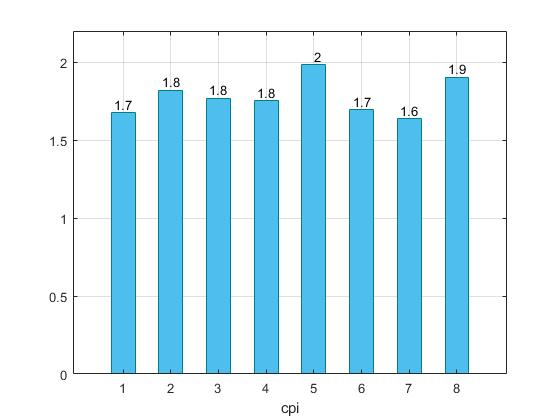
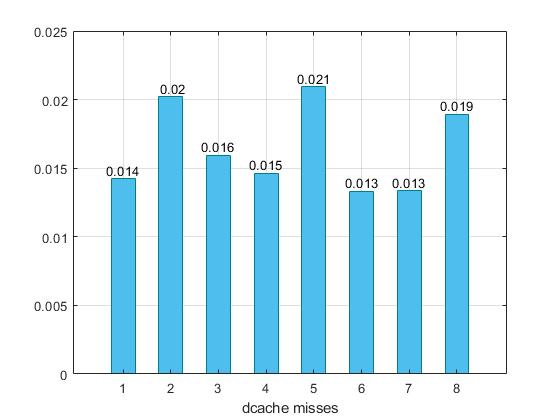
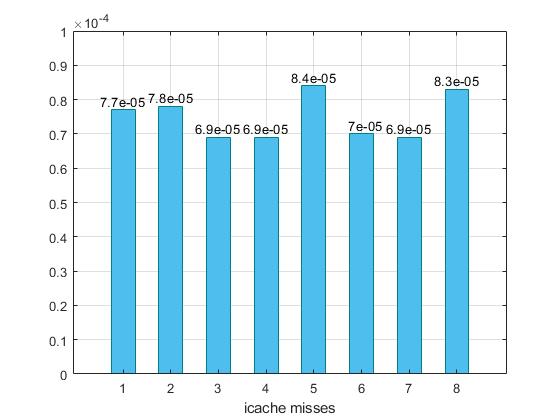
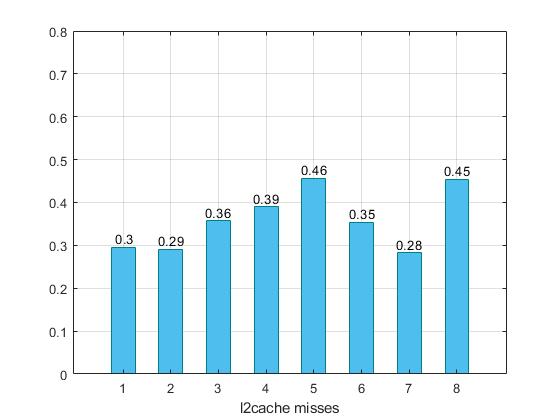
Παρατηρούμε ότι στον συνδυασμό 7 έχουμε κάπως καλύτερα αποτελέσματα, αυξάνοντας λίγο το associativity, αλλά και το μέγεθος των l1i=128 ,l1d=32 , και l2=4ΜΒ. Επιπλέον μπορούμε να συμπαιράνουμε οτί μειώνοντας το cacheline είτε με μικρό (5), είτε με μεγάλο (8) assosiciativity τα cache misses αυξάνοντε και μαζί τους το CPI και χρόνος εκτέλεσης. Στον συνδυασμό 4 όπου έχουμε full associativity, παρατηρούμε μικρή επιβράνδυση. Στο συγκεκριμένο benchmark οι συνδυασμοί επιλέχθηκαν τυχαία.
Για το benchmark speclibm ακολουθήθηκε άλλη στρατηγική, αλλάζοντας κάθε φορά από μία ή δύο παραμέτρους και αφήνοντας τις υπόλοιπες στις by default τιμές τους, ο αριθμός 1 αντιστοιχεί στα αποτελέσματα από το βήμα 1. Για τις εκτελέσεις των διαφορετικών commands δημιουργήθηκε ένα bash script
- 2 -> l1_assoc=32, l2_assoc=64
- 3 -> cacheline_size=32
- 4 -> l1_size = 192 , l2=2MB
- 5 -> l1_size = 256 , l2=1MB
- 6 -> l1_assoc=32, l2_assoc=64, cacheline_size=32
- 7 -> l1_assoc=16 , l2_assoc=32 , l2 4MB, l1i,d=192
Παρακάτω προκύπτουν τα εξής γραφήματα :
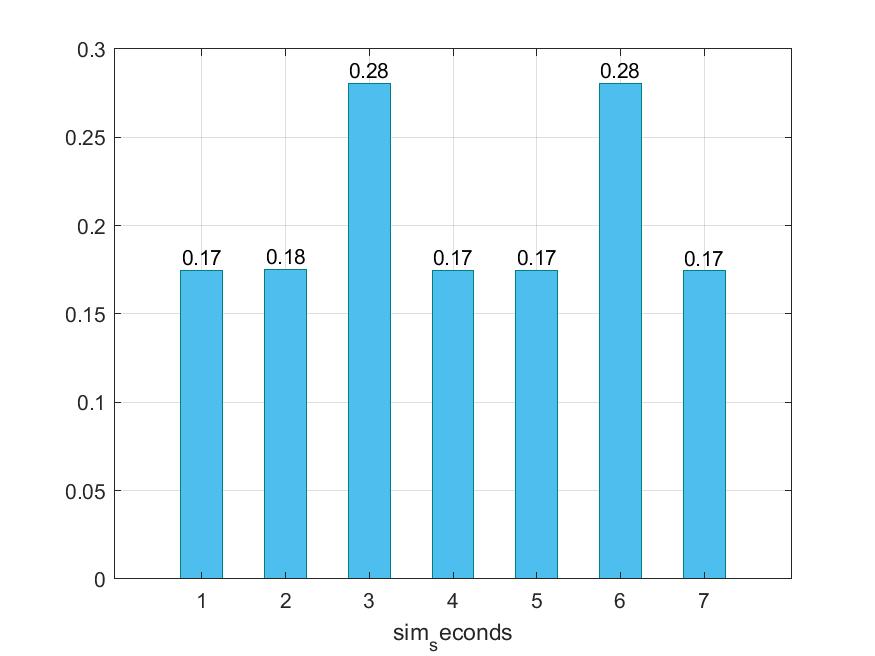
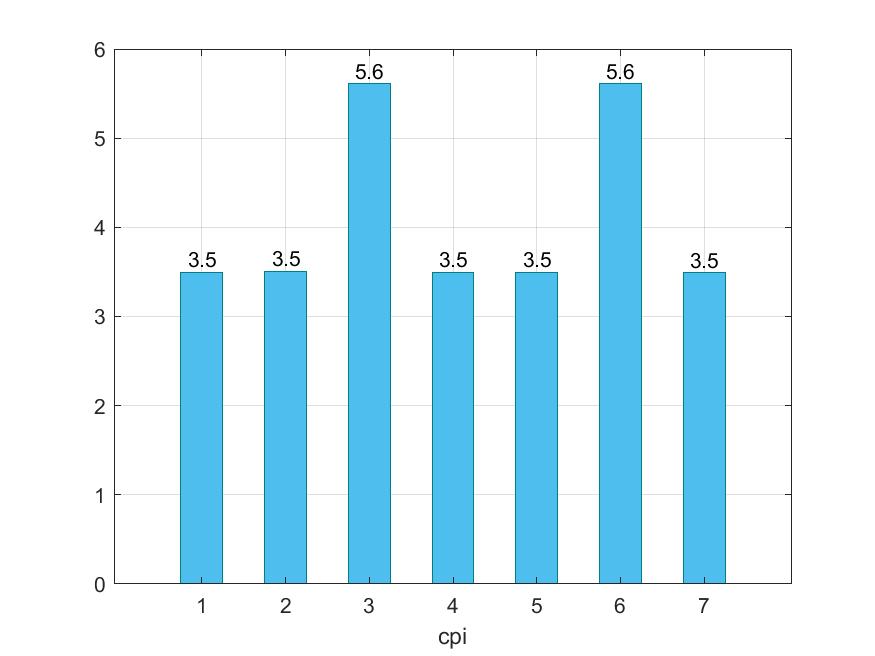
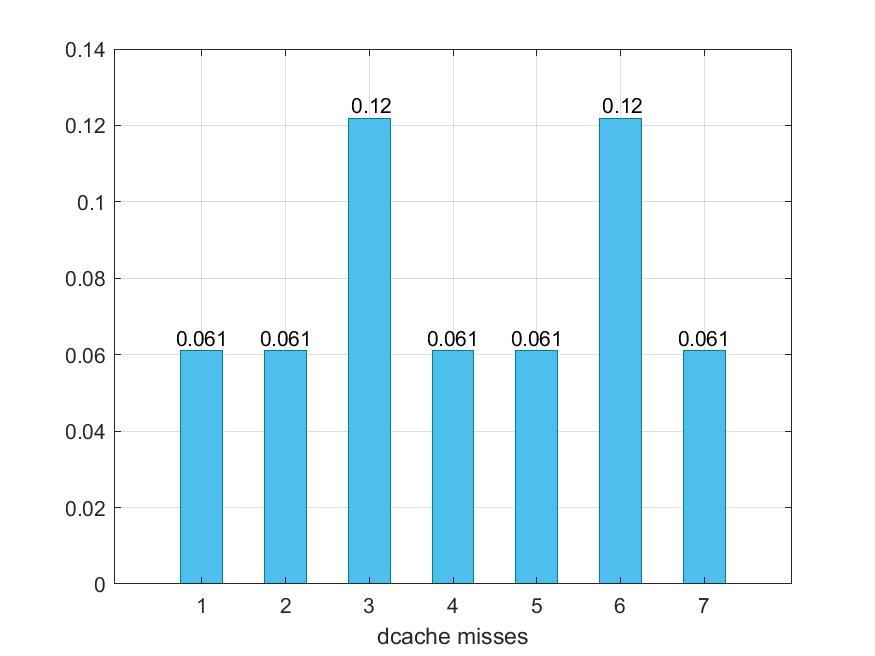
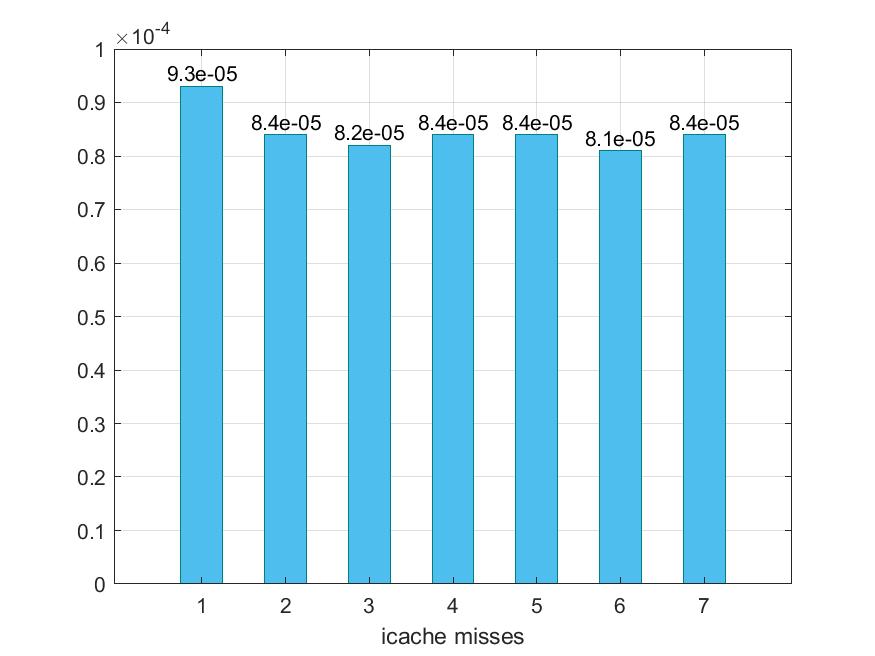
Ακολουθώντας την στρατηγική τροποποίησης παραμέτρων που αναφέραμε παραπάνω προκύπτει ότι δε καταφέραμε να μειώσουμε τον χρόνο εκτέλεσης και το CPI. Παρ'όλο αυτά μπορούμε να διακρίνουμε ότι στις περιπτώσεις 3 και 6 έχουμε αρκετή επιβράνδυση και αυτό οφείλεται στο ότι και στις δύο περιπτώσεις έχουμε αλλάξει τo cacheline_size σε 32. To L2 cache παραμένει υψηλό σε όλα.
Στο benchmark specsjeng γίνονται οι παρακάτω τροποποιήσεις :
- 2 -> l1_assoc=32, l2_assoc=64
- 3 -> cacheline_size=32
- 4 -> l1_size = 192 , l2=2MB
- 5 -> l1_size = 256 , l2=1MB
- 6 -> l1_assoc=32, l2_assoc=64, cacheline_size=32
- 7 -> assoc=16,32 , l2 = 4MB, l1i,d=192
- 8 -> l1d_size = 64 , l1i_size =128, l2_size = 4MB , assoc=4,16
- 9 -> l1d_size = 32 , l1i_size =64, l2_size = 2MB , assoc=64,64
- 10 -> l1d_size = 32 , l1i_size =64, l2_size = 4MB , assoc=1,2
- 10 -> l1d_size = 128 , l1i_size =128, l2_size = 4MB , assoc=128,256
Για τις εκτελέσεις των διαφορετικών commands δημιουργήθηκε ένα bash script
Παρακάτω πρκύπτουν τα εξής γραφήματα :





Για το benchmark spechmmer γίνονται οι εξής τροποποιήσεις :
- 1 -> default
- 2 -> --l1d_size=128kB --l1i_size=128kB --l2_size=512kB --l1i_assoc=1 --l1d_assoc=1 --l2_assoc=2
- 3 -> --l1d_size=128kB --l1i_size=128kB --l2_size=512kB --l1i_assoc=32 --l1d_assoc=32 --l2_assoc=64
- 4 ->--l1d_size=32kB --l1i_size=64kB --l2_size=512kB --l1i_assoc=1 --l1d_assoc=1 --l2_assoc=2
- 5 -> --l1d_size=32kB --l1i_size=64kB --l2_size=512kB --l1i_assoc=32 --l1d_assoc=32 --l2_assoc=64
- 6 -> --l1d_size=128kB --l1i_size=128kB --l2_size=4MB --l1i_assoc=8 --l1d_assoc=8 --l2_assoc=16
Παρακάτω προκύπτουν τα εξής γραφήματα :
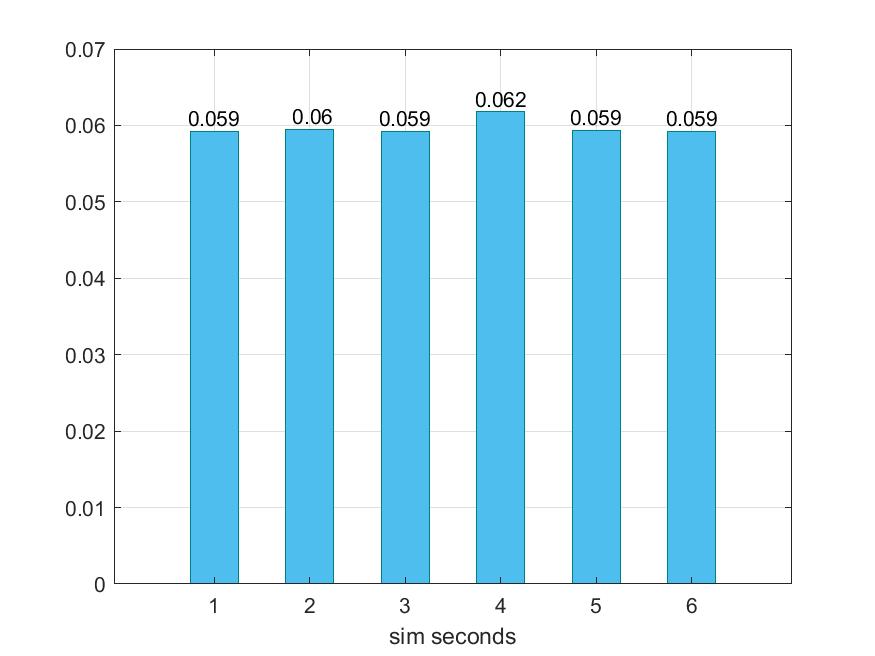
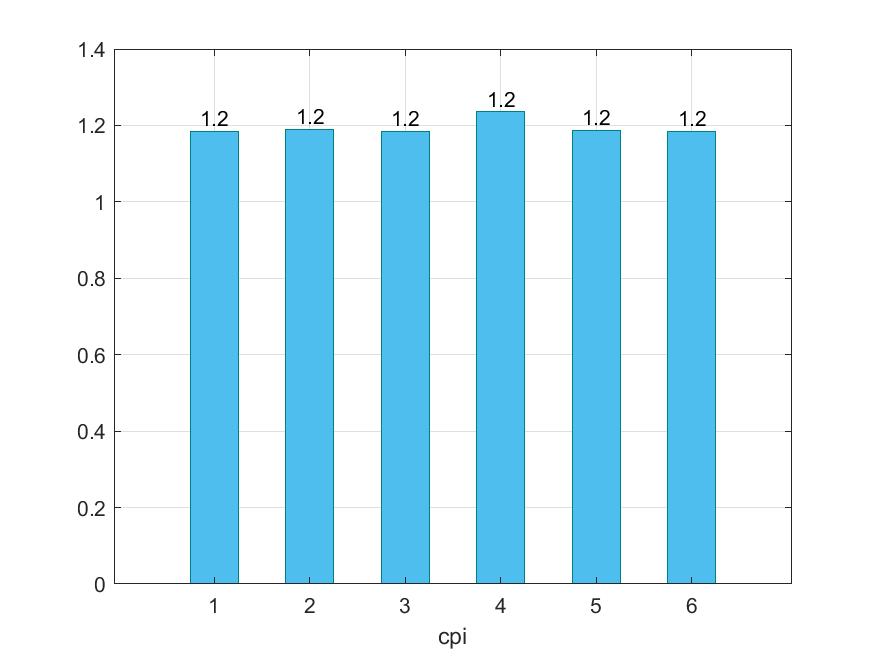
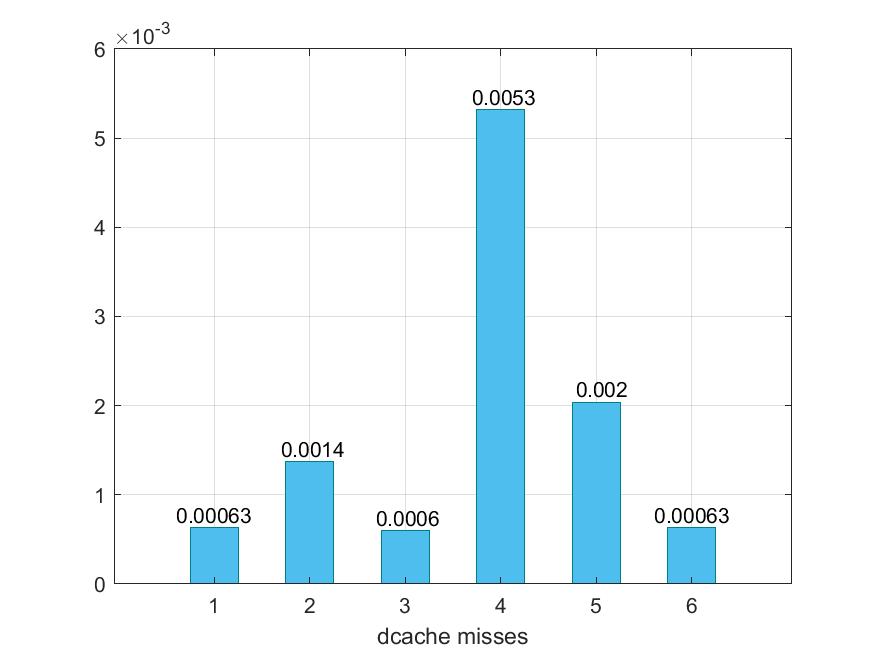
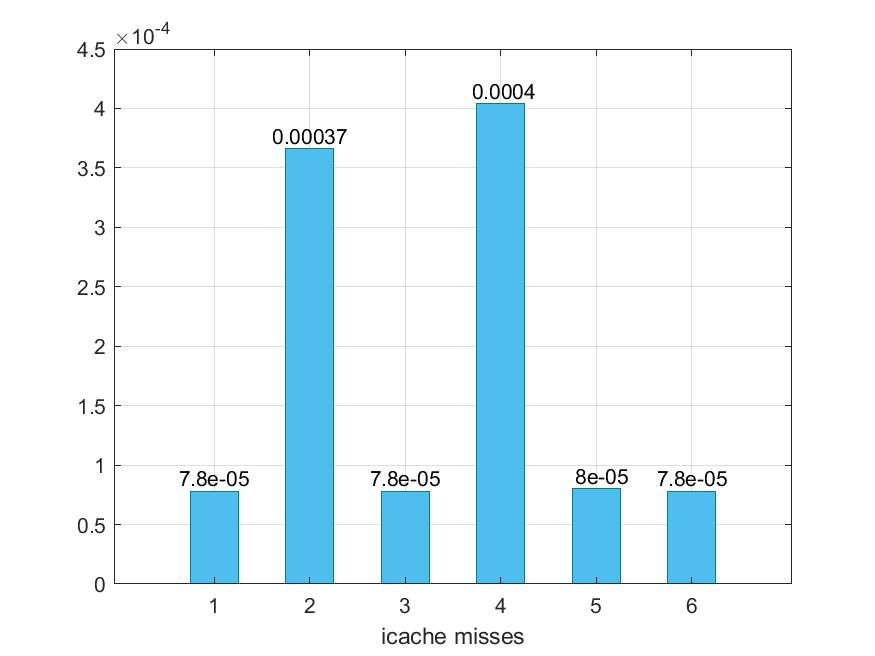
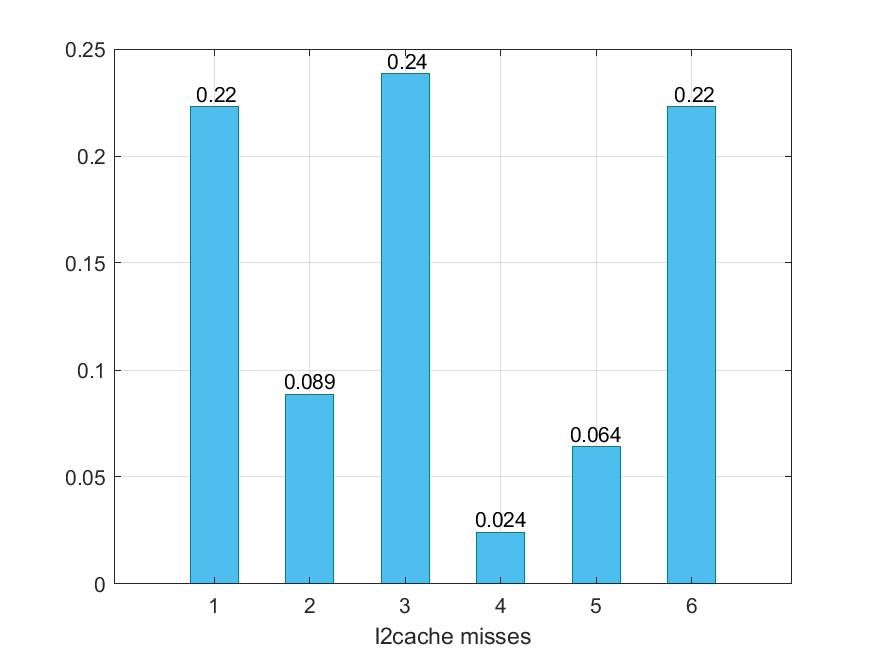
Παρατηρούμε ότι αυξάνοντας τα sizes των caches, και όχι τα associativities, στο συγκεκριμένο benchmark δε παρατηρούμε κάποια βελτίωση, ενώ αυξάνοντας και τα δύο υπάρχει μια ελάχιστη βελτίωση. Στην περίπτωση 4 όπου τα associativities είναι τα μικρότερα δυνατά, υπάρχει επιβράνδυση, μεγάλα dcache και icache miss rates, και μικρότερο l2 miss rate , το οποίο είναι λογικό αφού ότι δε βρίσει στις L1 το βρίσκει κατα πάσα πιθανότητα στις L2.
Από μελέτη σχετικής βιβλιογραφίας εδώ , εδώ & εδώ, και από τις δοκιμές που κάναμε παραπάνω προκύπτουν κάποια συμπεράσματα σχετικά με το πως επηρεάζουν οι παράμετροι της cpu την ταχύτητα και αποτελεσματικότητα της.

-
Όπως φαίνεται και στο γράφημα, αλλά και αναφέρεται στην παραπάνω βιβλιογραφία, η αύξηση του μεγέθους της l2 κυρίως cache βοηθάει σημαντικά στη αύξηση των hit rates, και στην μείωση δηλαδή των miss. Ωστόσο μεγαλύτερη cache οδηγεί σε περισσότερο "ψάξιμο", και άρα μεγαλύτερους χρόνους.
-
Επιπλέον παρατηρήσαμε ότι μείωση της cacheline οδηγεί σε σημαντικές καθυστερήσεις.
-
Κάτι ακόμα που παρατηρούμε αλλά αναφέρεται και στην βιβλιογραφία που επισυνάψαμε, είναι ότι αύξηση του associativity οδηγεί σε μικρότερα miss rates αλλά επιβαρύνει επίσης την ταχύτητα.
-
Άρα μεγαλύτερο associativity, δηλαδή block sizes, και μεγαλύτερη μνήμη μπορούν να μειώσουν σημαντικά τα miss rates, αλλά να οδηγήσουν σε σημαντικές καθυστερήσεις.
Με βάση λοιπόν όσα παρατηρήσαμε θα δοκιμάσουμε κάποιες τροποποιήσεις για το specmcf, το οποίο αποτελεί ένα σχετικά καλό benchmark με μικρα miss rates στην L2 και L1 data , αλλά μεγάλο στην L1 instruction, και καλό χρόνο εκτέλεσης και CPI.
- 1 -> default
- 2 -> --l1d_size=32kB --l1i_size=64kB --l2_size=512kB --l1i_assoc=4 --l1d_assoc=4 --l2_assoc=8
- 3 -> --l1d_size=128kB --l1i_size=128kB --l2_size=2MB --l1i_assoc=8 --l1d_assoc=8 --l2_assoc=16
- 4 -> --l1d_size=32kB --l1i_size=32kB --l2_size=512kB --l1i_assoc=2 --l1d_assoc=2 --l2_assoc=4
- Τα 5,6,7 είναι τα ίδια με τα 2,3,4 αντίστοιχα με τη μόνη διαφορά το --cpu-clock=1GHz
Παρακάτω πρκύπτουν τα εξής γραφήματα :





Παρατηρούμε λοιπόν ότι αυξάνοντας στην περίπτωση 2 τα associativities στην L1 σε 4 , πετυχαίνουμε καλύτερο χρόνο αυξάνοντας λίγο το cpi. Επιπλέον αυξάνοντας στην περίπτωση 3 τα sizes των L1 και L2 και αναλογικά και τα associativities παρατηρούμε επίσης καλό χρόνο , μικρότερο dcache miss rate. Στην περίπτωση 4 , μειώνοντας τα instruction sizes παρατηρούμε κάποια βελτιώση στον χρόνο , ωστόσο αύξηση στο cpi και στα icache misses και μια αναμενόμενη μείωση στo L2 miss rate, αφού ότι δε βρίσκεται στην L1 θα βρεθεί λογικά στην L2. Με αλλαγή στην συχνότητα της CPU σε 1GHz παρατηρούμε διπλάσιους χρόνους όπως και αναμενόταν.
Από όλες τις περιπτώσεις η καλύτερη είναι η 3 και άρα συμπαιρένουμε ότι μια αναλογική-γραμμική αύξηση των associativities και των μεγεθών των caches, πετυχαίνουμε καλύτερους χρόνους.
Μετά το συγκεκριμένο εργαστήριο καταφέραμε να αποκτήσουμε μια εικόνα για το πως οι διάφοροι παράμετροι επηρεάζουν την ταχύτητα και τον τρόπο λειτουργίας ενός CPU, για το πως λειτουργούν οι caches, και ποια η διαφορά των system clock και cpu clock. Επιπλέον λόγω του μεγάλου χρόνου που απαιτούσε η κάθε προσομοιώση, οδηγηθήκαμε στην αυτοματοποίηση διάφορων πράξεων με bash scripts και μικρά scripts για τα plots στο matlab. Οπότε σε γενικότερες γραμμές ήταν ένα αρκετά επικοδομητικό εργαστήριο.