This api lists movie trailers by gathering informations from IMDb and Youtube.
-
Using Node.js with Express
-
Secured with Okta OAuth 2.0
-
Using AWS ElastiCache to cache collected data to speed up response time
-
Using jest on tests
-
Using helmet package to enhance api security
-
Using morgan package as a request logger middleware
-
Using cors package for enabling CORS for all requests.
-
Has two endpoints
-- api/v1/trailers
-- api/v1/movies -
Currently hosted on AWS EC2 instance for demonstration
http://ec2-13-48-6-117.eu-north-1.compute.amazonaws.com:3000
api/v1/movies
Returns lists of movies gathered from configured movie service. It uses AWS Elasticache to cache results coming from the service to speed up response time and not to send so much request to the configured service. Currently it is configured to use IMDb service. IT can be attachted to any service by implementing new service class that extends HttpService.js and configuring related env variables. Related environment variables used for this service are listed below --- MOVIE_SEARCH_SERVICE=imdb --- IMDB_API_HOST=imdb8.p.rapidapi.com --- IMDB_API_KEY=**
curl -H "Content-Type:application/json" -X GET "http://ec2-13-48-6-117.eu-north-1.compute.amazonaws.com:3000/api/v1/movies?q=batman"
{
"status": 200,
"msg": "Success",
"records": [
{
"id": "/title/tt0289879/",
"title": "The Butterfly Effect",
"year": 2004,
"imageUrl": "https://m.media-amazon.com/images/M/MV5BODNiZmY2MWUtMjFhMy00ZmM2LTg2MjYtNWY1OTY5NGU2MjdjL2ltYWdlXkEyXkFqcGdeQXVyNTAyODkwOQ@@._V1_.jpg"
}
]
}{
"code": 400,
"msg": "Query string is empty. Make sure that using 'q' query string parameter for search phrase."
}api/v1/trailers
Returns lists of trailers gathered from configured video service. It uses AWS Elasticache to cache results coming from the service to speed up response time and not to send so much request to the configured service. Currently it is configured to use Youtube service. IT can be attachted to any service by implementing new service class that extends HttpService.js and configuring related env variables. Related environment variables used for this service are listed below --- VIDEO_SEARCH_SERVICE=imdb --- YOUTUBE_API_HOST=imdb8.p.rapidapi.com --- YOUTUBE_API_KEY=**
curl -H "Content-Type:application/json" -X GET "http://ec2-13-48-6-117.eu-north-1.compute.amazonaws.com:3000/api/v1/trailers?q=batman"
{
"status": 200,
"msg": "Success",
"records": [
{
"id": "B8_dgqfPXFg",
"publishedAt": "2009-12-06T15:51:43Z",
"title": "The Butterfly Effect (2004) Trailer",
"description": "The Butterfly Effect Trailer taken from The Butterfly Effect [DVD] This Video Clip Is In No Way Profitable, All Copyright Reserved To Their Owners. Ripped Using ...",
"thumbnails": {
"default": {
"url": "https://i.ytimg.com/vi/B8_dgqfPXFg/default.jpg",
"width": 120,
"height": 90
},
"medium": {
"url": "https://i.ytimg.com/vi/B8_dgqfPXFg/mqdefault.jpg",
"width": 320,
"height": 180
},
"high": {
"url": "https://i.ytimg.com/vi/B8_dgqfPXFg/hqdefault.jpg",
"width": 480,
"height": 360
}
}
}
]
}{
"code": 500,
"msg": "We are having problems on our server now. Please try again later."
}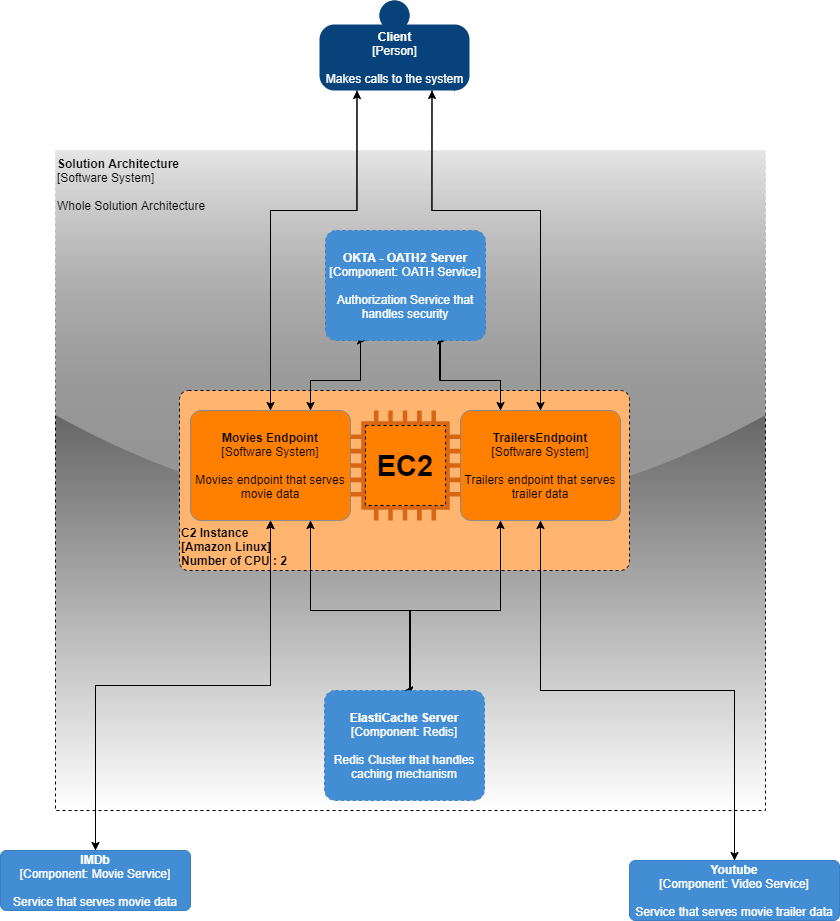
Api secured with Okta OAuth2 service. Every api call should have bearer token that is got from Okta. This token should be get by apps/clients that are using this service.
Each endpoint uses AWS ElastiCache Redis Cluster with 3 nodes. Every call firstly checks for the data is available with the cache coming from querystring. Keys are made from the format like below;
- for movies endpoint => movies_{querystringLowerCasedAndCleardFromSpaces}
- for trailers endpoint => videos_{querystringLowerCasedAndCleardFromSpaces}
If there is no cache found in ElastiCache Redis cluster, data is cached for 1h with the related cache key. Cache time can be expanded to 1d/1w. I used 1h since I'm using free tier and I don't want to get it grow so much.
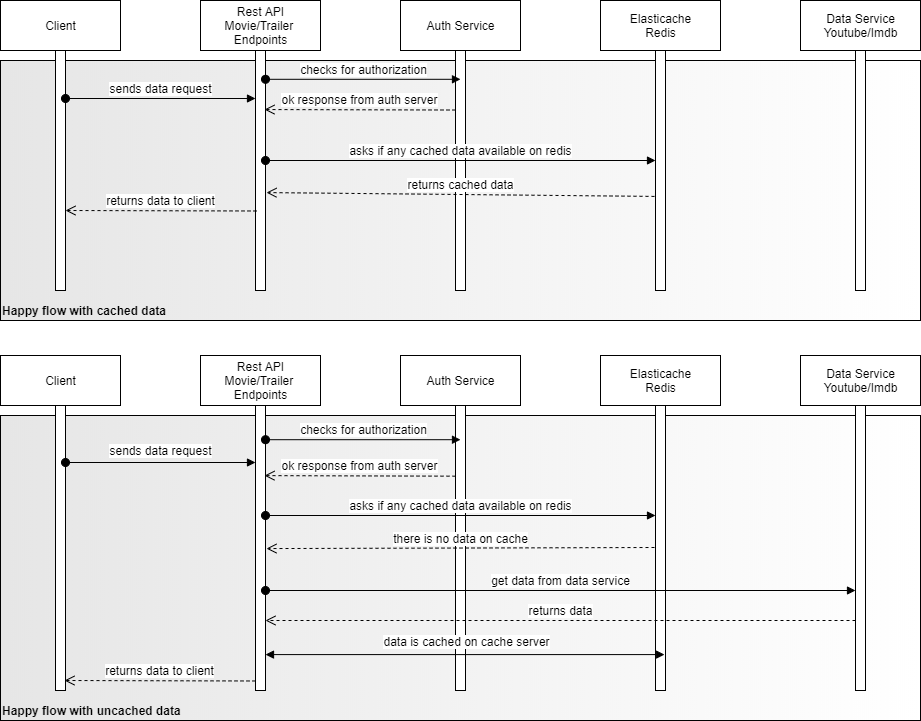
Each service is constructed with LocalServiceRegistry class. LocalServiceRegistry class is a factory who has the service domain information. Every service that will be integrated with the system should be added registry constant variable of this class so it can build the service by its name.
const registry = {
imdb: new IMDbService(),
youtube: new YoutubeService()
};This name also should be added to enviroment variables like below.
MOVIE_SEARCH_SERVICE=imdb
VIDEO_SEARCH_SERVICE=youtube
A service can be built with the code below.
// building the service
var localServiceRegistery = new LocalServiceRegistry();
var movieSearchService = localServiceRegistery.get(process.env.MOVIE_SEARCH_SERVICE);
// movie search request
var records = await movieSearchService.sendRequest({
q: searchPhrase
});As a result; we can change our data services anytime by changing environment variable values. No dependencies.
By using AWS Elasticache cluster, api requests will be faster as it is used further. Populer search phrases will provide better results in time.
Security is handled with a third party service so there is no responsibility on the API. API is only responsible for checking if token is still valid for the request coming from the client. But in here we have a dependency on the oauth service. But we can further improve this and remove this dependeny by using LocalServiceRegistry class. I just didn't have time for it.
Tests are implemented with Jest Testing framework. There are three types of test file in /tests folder. -- endpoint.test.js file is responsible for api endpoint tests. -- integrations.test.js file is responsible for service integration tests (youtube, imdb) -- redisClient.test.js file is responsible for to test redis server availability checks
API response time can be speed up further by adding a queue solution. What I have in mind to have a queue for movies that is coming from movie service. Each movie should be added to queue and a cron job can search for it's trailers with a cron job to fuel the ElastiCache cluster. So trailer data can be succesfuly gathered from cache.
Also we can implement this uproach for popular search phrases as well. System can hold every search phrase within MongoDB. So we can have popular search phrases report in time. A cron job can use this data to fullfil the cache cluster for movies as well.
But those can be made with a paid data service subscription since I went over the quota limit once for youtube.
Since system uses only one account for auth checks, auth token may not be valid for a request on high usage of the system.
Because auth token should be gathered from client/apps that is used this service. So auth token can be refreshed between two calls. This situation can create invalid token exceptions.
So as an improvem auth token checks should be made with client id's coming from client/app.
Install dependencies
npm install
Create .env filelike below on root folder
REDIS_CLUSTER_HOST=127.0.10.1
ISSUER={okta auth issuer host name}
SCOPE={okta scope name}
CLIENT_ID={auth client id}
CLIENT_SECRET={auth pssword}
IMDB_API_HOST={imdb api service host}
IMDB_API_KEY={imdb api key}
YOUTUBE_API_HOST=www.googleapis.com
YOUTUBE_API_KEY={youtube api key}
MOVIE_SEARCH_SERVICE=imdb
VIDEO_SEARCH_SERVICE=youtube
Start server: npm run start
Run tests: npm run tests
You can also find test postman collection in /assets/postman folder.