Quick-and-dirty Python script(s) for reading a pre-decrypted WeChat SQLite database and outputting some stats and visualizations based on them.
It's important to note that the database is a client-side database, which means it is authoritative only insofar as your mobile client (WeChat on your phone) observes the universe. Which is to say probably not very far. It is not in any way linked to any WeChat API (public or private) to provide truly authoritative server-side data. But if you use WeChat on your phone and have a significantly lengthy chat history, there will be a lot of cool data to visualize.
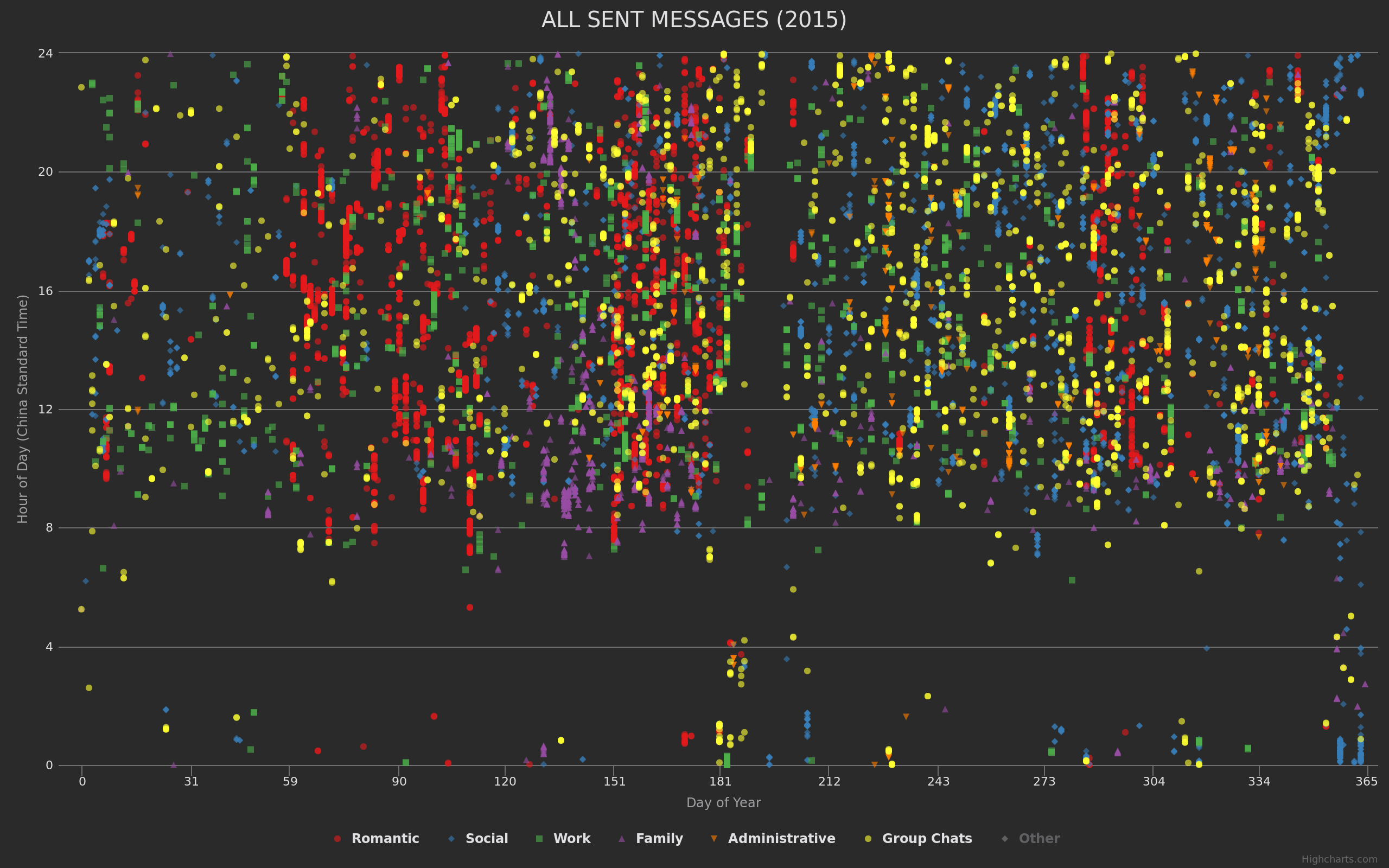
Click here for some samples of what the output looks like.
IMPORTANT
- This project really is quick and dirty. I built it over a couple of evenings of frantic hacking during the Lunar New Year holiday, never with a strong eye towards what the design ought to be; I was instead focused solely on obtaining the pretty pictures it generates as its output.
- Therefore, do not hesitate to propose sweeping changes to its architecture or organization.
- I've only tested this project on a rooted Android phone! I do not know if there is an analogous way to acquire the database from an iOS device, and even if you were able to do so, whether the internal schema of the database would be compatible with this project.
- Help on this front is appreciated!
If you have a rooted Android phone, go check out wechat-tools, which should make the job easier.
...
Go decrypt your database now. It might take a while to figure it out the first time, don't get discouraged. I'll wait here.
...
By the time you move on from this section, I assume you have a decrypted database, which should now be resident on the machine where you'll be running the Python scripts (i.e., you have transferred it to your computer and decrypted it, and probably in that order). To test this, you can run on most Linux machines:
sqlite3 decrypted.db .tables
... and it should give you a list of the tables in the database.
We only need a couple of things. This is as simple as:
pip install -r requirements.txt
It's up to you if you want to create a virtualenv for this project or install the dependencies globally.
To make the visualizations more useful, you should categorize your chat threads. This will allow you to see how much late-night romantic texting you do, for example. Or to prove to your boss that you really do spend a ton of time on work-related WeChats outside of office hours!
You should pick a threshold of threads you want to categorize. The recommended value is probably 80-90%. The principle here is that if you sort all your conversation threads by the number of messages you send, there will be some very popular threads at the front (friends and groups to whom you send a LOT of messages), and then towards the end there will be many, many threads which have only a message or two each.
In other words, it will be a relatively small task to categorize 85% of your threads by sent message volume, but that last 15% will be a ton of work because you'll be asked to categorize people who you barely chatted with.
For this reason, the default threshold is 0.85 (85%). But you can change it if you like (see below).
To do so, run:
python categorize.py decrypted.db
This will automatically tally up messages across all threads in the database and then ask you to categorize the most active threads, in order, which make up 85% or more of your sent messages. You can create as many categories as you want.
If you want to change the threshold, run this instead:
python categorize.py decrypted.db 0.75 # categorize only 75% of threads by volume
A couple of things to note:
- Category data is stored flat in a JSON file on disk, called
userdata.json. - No signature data for the database being used is stored in the user data file. So if you are going to switch to another chat database entirely (e.g. you are looking at a different user's database), best to blow away
userdata.json(or archive it somewhere) and categorize again! - The parser already makes a distinction between individual (1-on-1) chats and group chats, so there is no need to categorize group chats as "Group" unless you specifically want that.
- Group names are stored nicely but mapped internally with slugs ("Work Stuff" becomes
work-stuffand would collide with "work stuff"). otheris a special slug that is applied to anything uncategorized (such as the 10% of long-tail chats we don't bother to categorize). You can also manually put things in that category by specifying an "Other" category, though.userdata.jsonis saved every time you make a categorization, so you can quit (CTRL-C) and come back later.
Now that you've categorized, just run:
python test_2015.py decrypted.db
This will run a bunch of stats on your database for calendar year 2015. Outputs will be dumped in the local directory as chart0.html, chart1.html, etc.
Note
The set of visualizations run, the manner in which you choose (or don't, as the case is currently) which visualizations to run, and the format and organization of the output are all ripe for huge improvement!
The following resources were invaluable in the development of this project:
- I referred to this article on decrypting WeChat's SQLite database on Android, and the script linked therein, for the first many times I obtained and decrypted the database. Eventually, this was useful as reference in developing wechat-tools.
- The ever-awesome and incredibly easy-to-use highcharts.js (free for personal use).