CRNN原理分析
Convolutional Recurrent Neural Network
#原理介绍
Convolutional Recurrent Neural Network (CRNN)主要用于端到端地对不定长的文本序列进行识别,不用先对单个文字进行切割,而是将文本识别转化为时序依赖的序列学习问题,就是基于图像的序列识别。
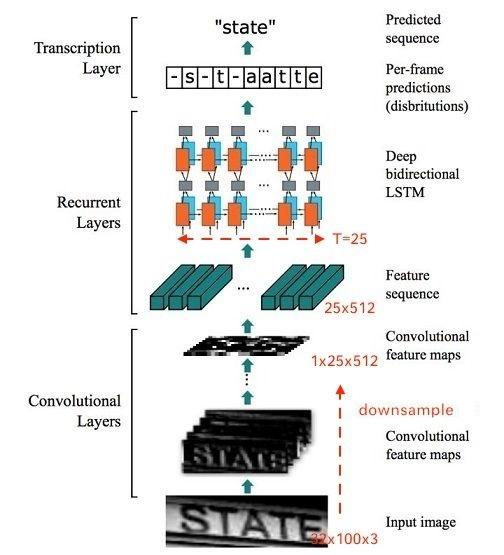
整个CRNN网络结构包含三部分,从下到上依次为:
- CNN(卷积层),使用深度CNN,对输入图像提取特征,得到特征图;
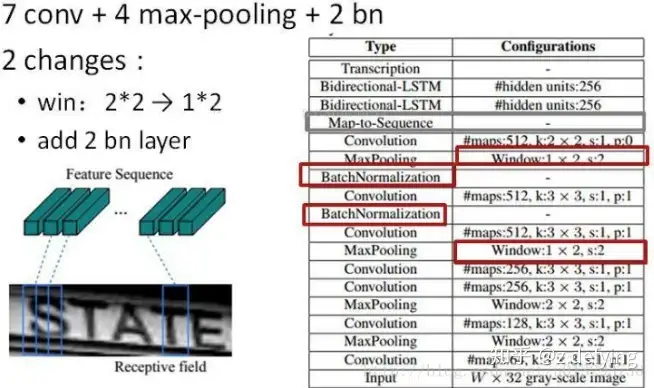
卷积层一共有四个最大池化层,但是最后两个池化层的窗口尺寸由 2x2 改为 1x2,也就是图片的高度减半了四次(除以2^4),而宽度则只减半了两次(除以2^2),这是因为文本图像多数都是高较小而宽较长,所以其feature map也是这种高小宽长的矩形形状,如果使用1×2的池化窗口可以尽量保证不丢失在宽度方向的信息,更适合英文字母识别(比如区分i和l)。
- RNN(循环层),使用双向RNN(BLSTM)对特征序列进行预测,对序列中的每个特征向量进行学习,并输出预测标签(真实值)分布;
CRNN借鉴了语音识别中的LSTM+CTC的建模方法,不同点是输入进LSTM的特征,从语音领域的声学特征(MFCC等),替换为CNN网络提取的图像特征向量。CRNN算法最大的贡献,是把CNN做图像特征工程的潜力与LSTM做序列化识别的潜力,进行结合。CRNN借鉴了语音识别中的LSTM+CTC的建模方法,不同点是输入进LSTM的特征,从语音领域的声学特征(MFCC等),替换为CNN网络提取的图像特征向量。CRNN算法最大的贡献,是把CNN做图像特征工程的潜力与LSTM做序列化识别的潜力,进行结合。
首先会将图像缩放到 32×W×1 大小,然后经过CNN后变为 1×(W/4)× 512,接着针对LSTM,设置 T=(W/4) , D=512 ,即可将特征输入LSTM。LSTM有256个隐藏节点,经过LSTM后变为长度为T × nclass的向量,再经过softmax处理,列向量每个元素代表对应的字符预测概率,最后再将这个T的预测结果去冗余合并成一个完整识别结果即可。


- CTC loss(转录层),使用 CTC 损失,把从循环层获取的一系列标签分布转换成最终的标签序列。
RNN进行时序分类时,不可避免地会出现很多冗余信息,比如一个字母被连续识别两次,这就需要一套去冗余机制。CTC为了解决这种二义性,提出了插入blank机制,比如我们以“-”符号代表blank,则若标签为“aaa-aaaabb”则将被映射为“aab”,而“aaaaaaabb”将被映射为“ab”。

ctc会计算loss ,从而找到最可能的像素区域对应的字符。事实上,这里loss的计算本质是对多路径概率的归纳。
