提示:transformer结构的目标检测解码器,包含loss计算,附有源码
@TOC
最近重温DETR模型,越发感觉detr模型结构精妙之处,不同于anchor base 与anchor free设计,直接利用100框给出预测结果,使用可学习learn query深度查找,使用二分匹配方式训练模型。为此,我基于detr源码提取解码decode、loss计算等系列模块,并重构、修改、整合一套解码与loss实现的框架,该框架可适用任何backbone特征提取接我框架,实现完整训练与预测,我也有相应demo指导使用我的框架。那么,接下来,我将完整介绍该框架源码。同时,我将此源码进行开源,并上传github中,供读者参考。
在介绍main函数代码前,我先说下整体框架结构,该框架包含2个文件夹,一个losses文件夹,用于处理loss计算,一个是obj_det文件,用于transformer解码模块,该模块源码修改于detr模型,也包含main.py,该文件是整体解码与loss计算demo示意代码,如下图。
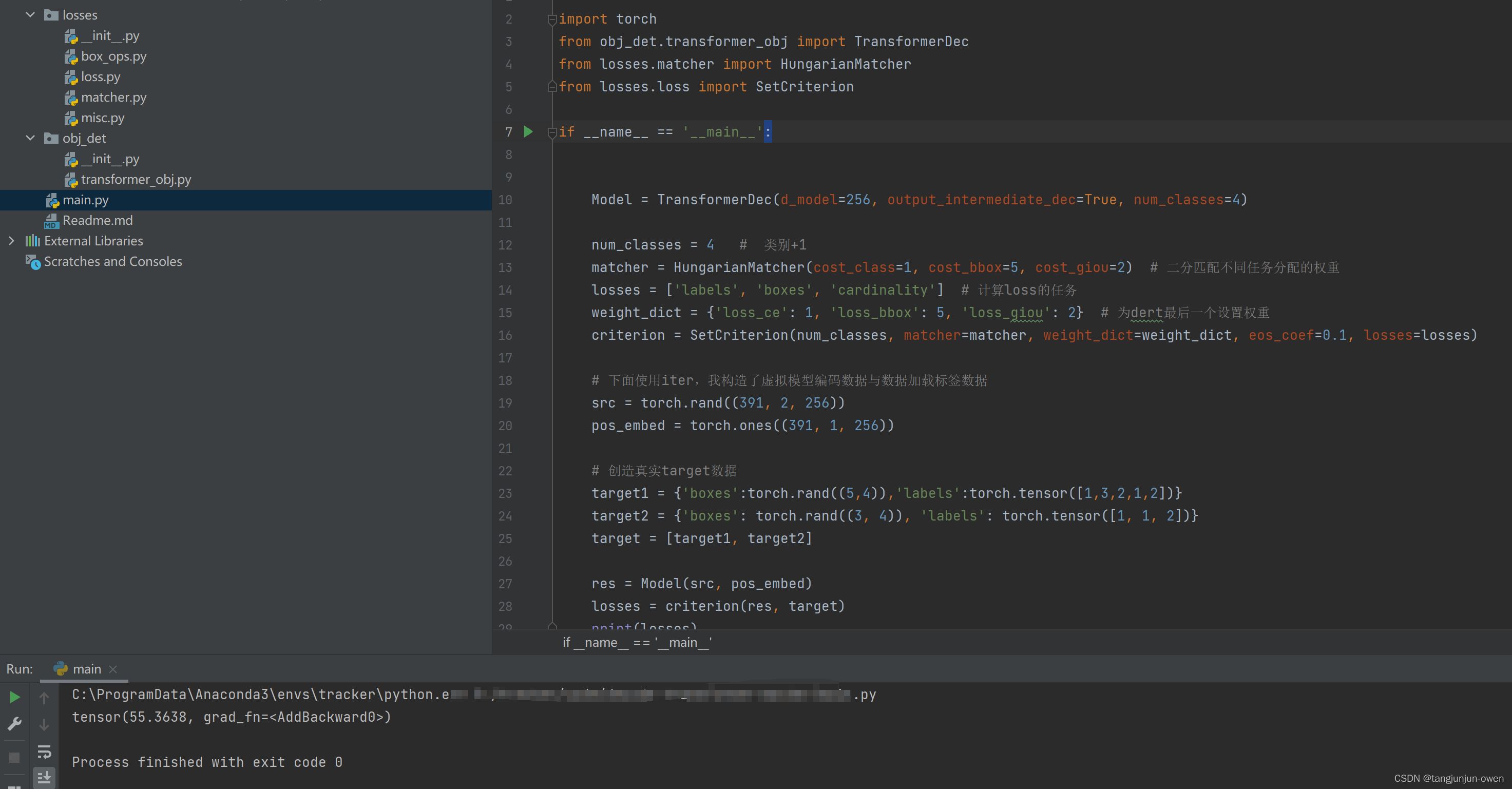
该代码实际是我随机创造了标签target数据与backbone特征提取数据及位置编码数据,使其能正常运行的demo,其代码如下:
import torch
from obj_det.transformer_obj import TransformerDec
from losses.matcher import HungarianMatcher
from losses.loss import SetCriterion
if __name__ == '__main__':
Model = TransformerDec(d_model=256, output_intermediate_dec=True, num_classes=4)
num_classes = 4 # 类别+1
matcher = HungarianMatcher(cost_class=1, cost_bbox=5, cost_giou=2) # 二分匹配不同任务分配的权重
losses = ['labels', 'boxes', 'cardinality'] # 计算loss的任务
weight_dict = {'loss_ce': 1, 'loss_bbox': 5, 'loss_giou': 2} # 为dert最后一个设置权重
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict, eos_coef=0.1, losses=losses)
# 下面使用iter,我构造了虚拟模型编码数据与数据加载标签数据
src = torch.rand((391, 2, 256))
pos_embed = torch.ones((391, 1, 256))
# 创造真实target数据
target1 = {'boxes':torch.rand((5,4)),'labels':torch.tensor([1,3,2,1,2])}
target2 = {'boxes': torch.rand((3, 4)), 'labels': torch.tensor([1, 1, 2])}
target = [target1, target2]
res = Model(src, pos_embed)
losses = criterion(res, target)
print(losses)如下图:
该模块主要是使用transform方式对backbone提取特征的解码,主要使用learn query等相关trike与transform解码方式内容。 我主要介绍TransformerDec、TransformerDecoder、DecoderLayer模块,为依次被包含关系,或说成后者是前者组成部分。
该类大意是包含了learn query嵌入、解码transform模块调用、head头预测logit与boxes等内容,是实现解码与预测内容,该模块参数或解释已有注释,读者可自行查看,其代码如下:
class TransformerDec(nn.Module):
'''
d_model=512, 使用多少维度表示,实际为编码输出表达维度
nhead=8, 有多少个头
num_queries=100, 目标查询数量,可学习query
num_decoder_layers=6, 解码循环层数
dim_feedforward=2048, 类似FFN的2个nn.Linear变化
dropout=0.1,
activation="relu",
normalize_before=False,解码结构使用2种方式,默认False使用post解码结构
output_intermediate_dec=False, 若为True保存中间层解码结果(即:每个解码层结果保存),若False只保存最后一次结果,训练为True,推理为False
num_classes: num_classes数量与数据格式有关,若类别id=1表示第一类,则num_classes=实际类别数+1,若id=0表示第一个,则num_classes=实际类别数
额外说明,coco类别id是1开始的,假如有三个类,名称为[dog,cat,pig],batch=2,那么参数num_classes=4,表示3个类+1个背景,
模型输出src_logits=[2,100,5]会多出一个预测,target_classes设置为[2,100],其值为4(该值就是背景,而有类别值为1、2、3),
那么target_classes中没有值为0,我理解模型不对0类做任何操作,是个无效值,模型只对1、2、3、4进行loss计算,然4为背景会比较多,
作者使用权重0.1避免其背景过度影响。
forward return: 返回字典,包含{
'pred_logits':[], # 为列表,格式为[b,100,num_classes+2]
'pred_boxes':[], # 为列表,格式为[b,100,4]
'aux_outputs'[{},...] # 为列表,元素为字典,每个字典为{'pred_logits':[],'pred_boxes':[]},格式与上相同
}
'''
def __init__(self, d_model=512, nhead=8, num_queries=100, num_decoder_layers=6, dim_feedforward=2048, dropout=0.1,
activation="relu", normalize_before=False, output_intermediate_dec=False, num_classes=1):
super().__init__()
self.num_queries = num_queries
self.query_embed = nn.Embedding(num_queries, d_model) # 与编码输出表达维度一致
self.output_intermediate_dec = output_intermediate_dec
decoder_layer = DecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=output_intermediate_dec)
self._reset_parameters()
self.d_model = d_model
self.nhead = nhead
# 设置head头提取
self.num_classes=num_classes
self.class_embed = nn.Linear(d_model, num_classes + 1)
self.bbox_embed = MLP(d_model, d_model, 4, 3)
def _reset_parameters(self):
for p in self.parameters():
if p.dim() > 1:
nn.init.xavier_uniform_(p)
def forward_feature(self, x, pos_embed, mask=None):
'''
假设batch=2,编码后的宽高为17、23
x: 编码后的输入,变为[17*23,2,256]
pos_embed:位置编码,使用[17*23,1,256]
mask:为图像掩码,nn.MultiheadAttention函数使用,作为memory_key_padding_mask的参数,默认为None,
被图像覆盖为0,否则为1,格式为[2,17,23]。个人感觉pad填充位置为1,就忽略注意,那里是没意义关注的。
'''
# flatten NxCxHxW to HWxNxC
hw,bs,c=x.shape # 编码后的输入,格式为h*w,b,c
pos_embed = pos_embed.repeat(1, bs, 1) # 位置变成[17*23,2,256]
# self.query_embed.weights 是可训练的
query_embed = self.query_embed.weight.unsqueeze(1).repeat(1, bs, 1) # 可学习参数从[100,256]变成[100,2,256]
if mask is not None:
mask = mask.flatten(1) # mask从[2,17,23]变成[2,17*23],该mask被图像覆盖为0
tgt = torch.zeros_like(query_embed) # 生成0张量[100,2,256]
# tgt为生成0张量[100,2,256],memory为编码输出[17*23,2,256],pos为位置编码不变,query_embed为可学习查询参数,在解码开始学习
hs = self.decoder(tgt, x, memory_key_padding_mask=mask, pos=pos_embed, query_pos=query_embed) # [6,100,2,256]
return hs.transpose(1, 2)
def forward(self,x,pos_embed,mask=None):
'''
假设batch=2,编码后的宽高为17、23
x: 编码后的输入,变为[17*23,2,256]
pos_embed:位置编码,使用[17*23,1,256]
mask:为图像掩码,nn.MultiheadAttention函数使用,作为memory_key_padding_mask的参数,默认为None,
被图像覆盖为0,否则为1,格式为[2,17,23]。个人感觉pad填充位置为1,就忽略注意,那里是没意义关注的。
'''
feature_dec = self.forward_feature( x, pos_embed, mask=mask)
# 推理输出类别与box
outputs_class = self.class_embed(feature_dec) # [6,2,100,92] 92=cls_num+背景+置信度,在如三个类[person,cat,dog],则为3+1+1
outputs_coord = self.bbox_embed(feature_dec).sigmoid() # [6,2,100,4]
out = {'pred_logits': outputs_class[-1], 'pred_boxes': outputs_coord[-1]} # 都是取最后一个,变成[2,100,92]和[2,100,4]
# 上面内容训练与推理适用
if self.output_intermediate_dec:
# out['aux_outputs']将前面5个值匹配对应
out['aux_outputs'] = self._set_aux_loss(outputs_class, outputs_coord)
return out
def _set_aux_loss(self, outputs_class, outputs_coord):
# this is a workaround to make torchscript happy, as torchscript
# doesn't support dictionary with non-homogeneous values, such
# as a dict having both a Tensor and a list.
return [{'pred_logits': a, 'pred_boxes': b}
for a, b in zip(outputs_class[:-1], outputs_coord[:-1])]
可看到该部分比较重要3个类(如下),我将在下面内容解读。
decoder_layer = DecoderLayer(d_model, nhead, dim_feedforward,
dropout, activation, normalize_before)
decoder_norm = nn.LayerNorm(d_model)
self.decoder = TransformerDecoder(decoder_layer, num_decoder_layers, decoder_norm,
return_intermediate=output_intermediate_dec)
self.bbox_embed = MLP(d_model, d_model, 4, 3)TransformerDec是decode解码的组装,包含head部分,而TransformerDecoder是解码transformer结构内容组装,主要决定调用 transformer解码结构轮数及解码输出处理与保存,其代码如下:
class TransformerDecoder(nn.Module):
def __init__(self, decoder_layer, num_layers, norm=None, return_intermediate=False):
super().__init__()
self.layers = _get_clones(decoder_layer, num_layers)
self.num_layers = num_layers
self.norm = norm
self.return_intermediate = return_intermediate
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
output = tgt # output初始化为0,[100,2,256]
intermediate = []
for layer in self.layers: # 循环遍历5次,结构都一样
output = layer(output, memory, tgt_mask=tgt_mask, #output初始化为0[100,2,256] memory为编码输入特征[551,2,256],tgt_mask为None
memory_mask=memory_mask, # memory为None
tgt_key_padding_mask=tgt_key_padding_mask, # 为None
memory_key_padding_mask=memory_key_padding_mask, # 和编码一样[2,551]
pos=pos, query_pos=query_pos) # pos为位置编码,query_pos为可学习query[100,2,256]
if self.return_intermediate:
intermediate.append(self.norm(output)) # 每次解码输出结果[100,2,256]
# output 输出仍为[100,2,256]
if self.norm is not None:
output = self.norm(output)
if self.return_intermediate:
intermediate.pop()
intermediate.append(output)
if self.return_intermediate:
return torch.stack(intermediate) # 将多intermediate保存[100,2,256]做拼接,输出为[6,100,2,256]
return output.unsqueeze(0)
该部分TransformerDecoder类的组成部分,也是最核心部分,实际是q/k/v相关解码内容,该部分在qkv计算中有2中方式, 而这2种方式仅是位置放置不同,我已有注释,其代码如下:
class DecoderLayer(nn.Module):
def __init__(self, d_model, nhead, dim_feedforward=2048, dropout=0.1, activation="relu", normalize_before=False):
super().__init__()
self.self_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
self.multihead_attn = nn.MultiheadAttention(d_model, nhead, dropout=dropout)
# Implementation of Feedforward model
self.linear1 = nn.Linear(d_model, dim_feedforward)
self.dropout = nn.Dropout(dropout)
self.linear2 = nn.Linear(dim_feedforward, d_model)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.norm3 = nn.LayerNorm(d_model)
self.dropout1 = nn.Dropout(dropout)
self.dropout2 = nn.Dropout(dropout)
self.dropout3 = nn.Dropout(dropout)
self.activation = _get_activation_fn(activation)
self.normalize_before = normalize_before
def with_pos_embed(self, tensor, pos: Optional[Tensor]):
return tensor if pos is None else tensor + pos
def forward_post(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
q = k = self.with_pos_embed(tgt, query_pos) # tgt为0,query_pos为可学习参数,随机初始化的
tgt2 = self.self_attn(q, k, value=tgt, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0] # q k加了位置分开,而tgt是没加位置信息
tgt = tgt + self.dropout1(tgt2) # 类似残差连接
tgt = self.norm1(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt, query_pos), # query为自注意力后tgt+query [100,2,256]
key=self.with_pos_embed(memory, pos), # key为编码后的值加位置[391,2,256]
value=memory, attn_mask=memory_mask, # value为编码后的值[391,2,256]
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2) # tgt再次加上获得tgt2值
tgt = self.norm2(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt))))
tgt = tgt + self.dropout3(tgt2)
tgt = self.norm3(tgt)
return tgt
def forward_pre(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
tgt2 = self.norm1(tgt)
q = k = self.with_pos_embed(tgt2, query_pos)
tgt2 = self.self_attn(q, k, value=tgt2, attn_mask=tgt_mask,
key_padding_mask=tgt_key_padding_mask)[0]
tgt = tgt + self.dropout1(tgt2)
tgt2 = self.norm2(tgt)
tgt2 = self.multihead_attn(query=self.with_pos_embed(tgt2, query_pos),
key=self.with_pos_embed(memory, pos),
value=memory, attn_mask=memory_mask,
key_padding_mask=memory_key_padding_mask)[0]
tgt = tgt + self.dropout2(tgt2)
tgt2 = self.norm3(tgt)
tgt2 = self.linear2(self.dropout(self.activation(self.linear1(tgt2))))
tgt = tgt + self.dropout3(tgt2)
return tgt
def forward(self, tgt, memory,
tgt_mask: Optional[Tensor] = None,
memory_mask: Optional[Tensor] = None,
tgt_key_padding_mask: Optional[Tensor] = None,
memory_key_padding_mask: Optional[Tensor] = None,
pos: Optional[Tensor] = None,
query_pos: Optional[Tensor] = None):
if self.normalize_before:
return self.forward_pre(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)
return self.forward_post(tgt, memory, tgt_mask, memory_mask,
tgt_key_padding_mask, memory_key_padding_mask, pos, query_pos)以上便是decode解码器整个构成部分了。
前面我已说过decode解码模块,该部分就说明构造虚拟数据模拟运行解码模块。
假设:batch为2,经过backbone提取特征后,变为[391,2,256]的特征表达,其中391=1723为图像宽高积,2为batch,256为d_model维度表达(顺道说下,若维度很高可使用nn.Linear,若有h、w可使用11的cov2d卷积降维)。
输入2个变量,一个为特征表达变量,一个为位置编码变量。我这里使用随机构造虚拟变量,如下:
src = torch.rand((391, 2, 256))
pos_embed = torch.ones((391, 1, 256))该函数为解码模块代码,比较简单,代码如下:
def train_decode_demo():
M = TransformerDec(d_model=256, output_intermediate_dec=True, num_classes=4)
src = torch.rand((391, 2, 256))
pos_embed = torch.ones((391, 1, 256))
res = M(src, pos_embed)前面我已说过了decode解码模块与训练模块,你也很关心解码后的数据如何预测吧? 基于此,该部分就构造虚拟数据模拟运行预测模块demo。
假设:batch为2,经过backbone提取特征后,变为[391,2,256]的特征表达,其中391=1723为图像宽高积,2为batch,256为d_model维度表达(顺道说下,若维度很高可使用nn.Linear,若有h、w可使用11的cov2d卷积降维)。
输入2个变量,一个为特征表达变量,一个为位置编码变量。我这里使用随机构造虚拟变量,如下:
batch = 2
src = torch.rand((391, batch, 256))
pos_embed = torch.ones((391, 1, 256))该函数为解码模块代码,比较简单,代码如下:
def predect_demo():
'''
这是一个推理模型,我使用batch=2进行推理验证的demo
当然,这个没有载入权重,仅作为推理演示
'''
batch = 2
src = torch.rand((391, batch, 256))
pos_embed = torch.ones((391, 1, 256))
M = TransformerDec(d_model=256, output_intermediate_dec=True, num_classes=4).cuda()
res = M(src.cuda(), pos_embed.cuda())
h, w = 420, 640 # 原始图像尺寸,为后处理恢复box使用
orig_target_sizes = torch.tensor([[h, w], [h, w]]).cuda() # batch为2,需要2个高宽
result = PostProcess()(res, orig_target_sizes) # orig_target_sizes原始图像尺寸,未resize尺寸
# print(res)
res_index, res_score, res_lable, res_bbox = [], [], [], []
min_score = 0.5 # thr的阈值,默认为0.9
for b in range(batch):
for i in range(0, 100):
res_tmp = result[b]['scores']
if float(res_tmp[i]) > min_score:
res_score.append(float(res_tmp[i]))
res_lable.append(int(result[b]['labels'][i].cpu().numpy()))
res_bbox.append(result[b]['boxes'][i].cpu().numpy().tolist())
print("result: ", res_score, res_lable, res_bbox)losses模块来源detr源码,我已做了修改,该部分就一个目的,在每张图预测100个目标寻找对应gt目标匹配对应关系,且为一一对应。detr采用二分匹配与匈牙利方法。
源码使用下面代码进行初始化,如下代码:
matcher = build_matcher(args)函数builder_matcher结构如下:
def build_matcher(args):
return HungarianMatcher(cost_class=args.set_cost_class, cost_bbox=args.set_cost_bbox, cost_giou=args.set_cost_giou)以上可知,传递参数为权重固定值,分别表示类权重、L1权重、giou权重,dert固定分别为1、5、2。
而调用该函数在class SetCriterion(nn.Module)类中的forward函数,主要一句调用为:
indices = self.matcher(outputs_without_aux, targets)最终在这里输出匹配结果,我以2个图,每个图只有一个目标,其结果如图:

该部分代码主要为预测与gt匹配方式,将所有batch图的预测按顺序拼接起来,假如每个图预测p=100,batch为b=2,预测拼接类out_prob与out_bbox,而所有gt标签共n=2,并按顺序获得所有标签类索引tgt_ids,最后使用tgt_ids对out_prob得到cost_class=[b*p,n]=[200,2],并取反便得到cost_class,最后使用out_bbox与tgt_bbox分别得到cost_bbox与cost_giou,最终将cost_class/cost_bbox/cost_giou使用权重相加得到成本矩阵,然目前是整体计算,在通过split手段将每张图与对应gt从总成本矩阵拆分,分别计算每个图与gt的对应关系,获得最终匹配。
num_classes参数设计与我们之前有些不同,我将在此解读一下,至于完整说明参考我的detr文章。
结论:num_classes=真实类总数+1,而模型预测src_logits=num_classes+1。
举列:假如真实类有三个[dog,cat,pig],那么num_classes=真实类总数+1=3+1=4,而模型预测src_logits=num_classes+1=4+1=5。
我的理解如下: coco数据格式的类别id是1开始的,假如有三个类,名称为[dog,cat,pig],batch=2,那么参数num_classes=4,表示3个类+1个背景,模型输出src_logits=[2,100,5]会多出一个预测,target_classes设置为[2,100],其初始值为4(该值就是背景,而有类别值为1、2、3), 其它对应位置的值为对应标签(1、2、3中选),恰好target_classes中没有值为0,我理解模型不对0类做任何操作,是个无效值,模型只对1、2、3、4进行loss计算,然4为背景会比较多,作者使用权重0.1避免其背景过度影响。其对应代码如下:
target_classes = torch.full(src_logits.shape[:2], self.num_classes, dtype=torch.int64, device=src_logits.device)
# 该部分就是论文所说使用某种方式将gt也变成100的方式,赋值标签id,第一类的标签为1,以此类推
target_classes[idx] = target_classes_o # 将对应idx赋值,即[0,67]位置为1,[1,79]位置为2,其它赋值任为4该部分呈现构建虚拟预测与target数据,仅使用demo计算loss代码,如下:
import torch
from losses.matcher import HungarianMatcher
num_classes = 4 # 类别+1
matcher = HungarianMatcher(cost_class=1, cost_bbox=5, cost_giou=2) # 二分匹配不同任务分配的权重
losses = ['labels', 'boxes', 'cardinality'] # 计算loss的任务
weight_dict = {'loss_ce': 1, 'loss_bbox': 5, 'loss_giou': 2} # 为dert最后一个设置权重
criterion = SetCriterion(num_classes, matcher=matcher, weight_dict=weight_dict, eos_coef=0.1, losses=losses)
# 创造真实target数据
target1 = {'boxes':torch.rand((5,4)),'labels':torch.tensor([1,3,2,1,2])}
target2 = {'boxes': torch.rand((3, 4)), 'labels': torch.tensor([1, 1, 2])}
target = [target1, target2]
pred_logits=torch.rand((2, 100, 5))
pred_boxes = torch.rand((2, 100, 4))
res={'pred_logits':pred_logits,'pred_boxes':pred_boxes}
losses = criterion(res, target)
print(losses)以上便是losses相关模块代码解读,其很多原理与我之前写的detr解读相似,建议查看点击这里
注:建议参考我的detr博客