平台架构 ML任务流
cube使用argo作为任务流workflow,为了能降低用户的学习成本,开发了一套拖拉拽的任务流拖拉拽的编排能力。并且在其中加入了很多分布式的任务模板。基本上的分布式框架都可以得到解决。各类的分布式框架在分布式任务加速中也有介绍。

有些任务希望在任务实例运行时在产生某些变量的值,目前平台支持一下模板变量
creator=pipeline.created_by.username 字符串:pipeline的创建者
datetime=datetime, 包
runner=g.user.username 字符串:实例的运行者
uuid = uuid 包
pipeline_id=pipeline.id 字符串
pipeline_name=pipeline.name 字符串: pipeline的名称
cluster_name=pipeline.project.cluster['NAME'] 字符串,当前所属k8s集群
execution_date=eta.strftime('%Y-%m-%d %H:%M:%S') 字符串, 实例的周期时间
使用实例
{{uuid.uuid4().hex[:4]}}
{{datetime.datetime.now().strftime("%Y%m%d-%H%M%S.%f")}}
{{pipeline_id}}
{{pipeline_name}}
{{cluster_name}}
{{runner}}
{{execution_date}}
通过notebook我们可以进行代码的编辑,通过镜像调试,我们可以构建自己的镜像。然后就可以编排pipeline了。pipeline运行前需要独立运行调试单个task,所以cube添加单task独立调试的功能。

每个task都可以独立的debug和独立的运行。这样就不用每次都运行整体pipelie才能进行调试。并且对于分布式任务的task,cube在模板中借用stern实现了多个容器log聚合查看。这样就不用每个worker的日志都单独去看了。

单个任务为分布式任务:
往往某个任务需要是分布式任务,所以需要启动分布式任务,云原生分布式任务需要k8s 对应的operator。分布式算法的模板的实现方法,主要在模板中实现launcher,创建对应分布式任务的job yaml,提交到k8s,对应的job operator创建每个worker的pod和service,然后运行业务代码。launcher端启动stern组件,监听该分布式任务的所有pod的日志,进行输出,这样就可以在当前任务中查看到所有worker的日志。

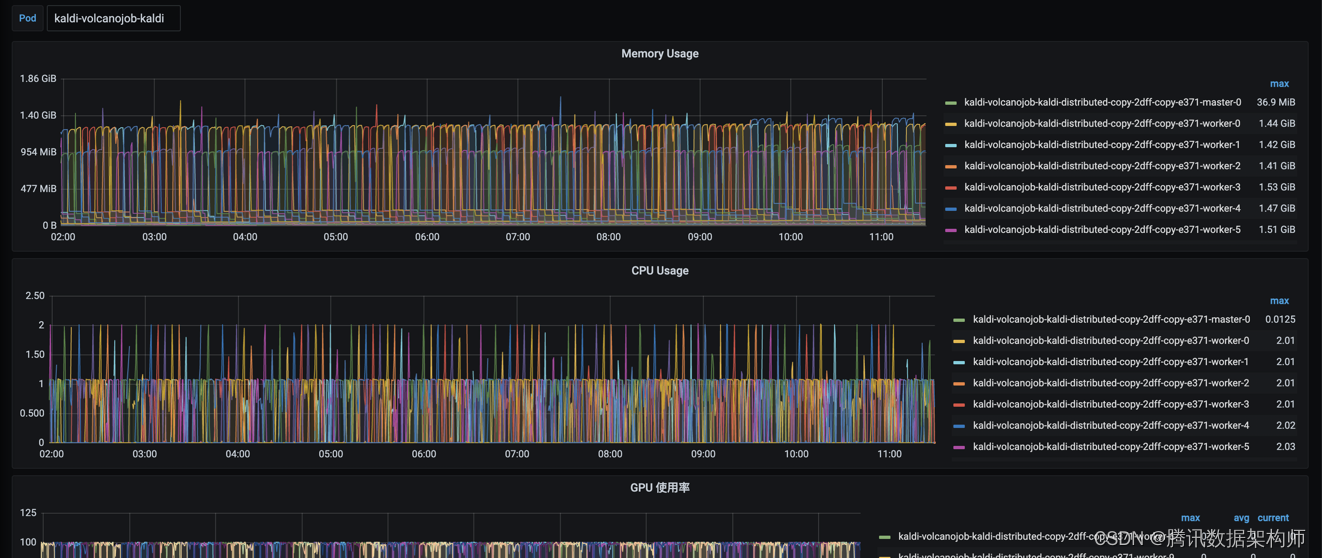
并且每个任务启动后都可以看到相应的资源情况,这样可以边调试边配置资源的申请量,在gpu上也可以及时知道是否还有优化的空间,目前任务的主要瓶颈在哪里。这样能更加直观的确定优化的方向。
对于某些部分一个任务流运行后,可能在某些任务开始出现偶发性错误,cube提供了,在结束pipeline后,在失败点继续训练的功能,这样就能不用重复训练某些耗时的任务。同时cube也为每个任务提供了重试次数和超时时长的配置。并且提供了任务的实时和离线日志查询两种功能。



pod调度情况,可以最真实的反应每个任务或分布式任务的状态。还有资源使用情况

任务编排调试好以后,还要进行定时调度。cube支持了定时调度任务的,补录,忽略,重试,依赖,并发限制,过期淘汰等功能,能应对任务堆积,平台故障等可能问题。
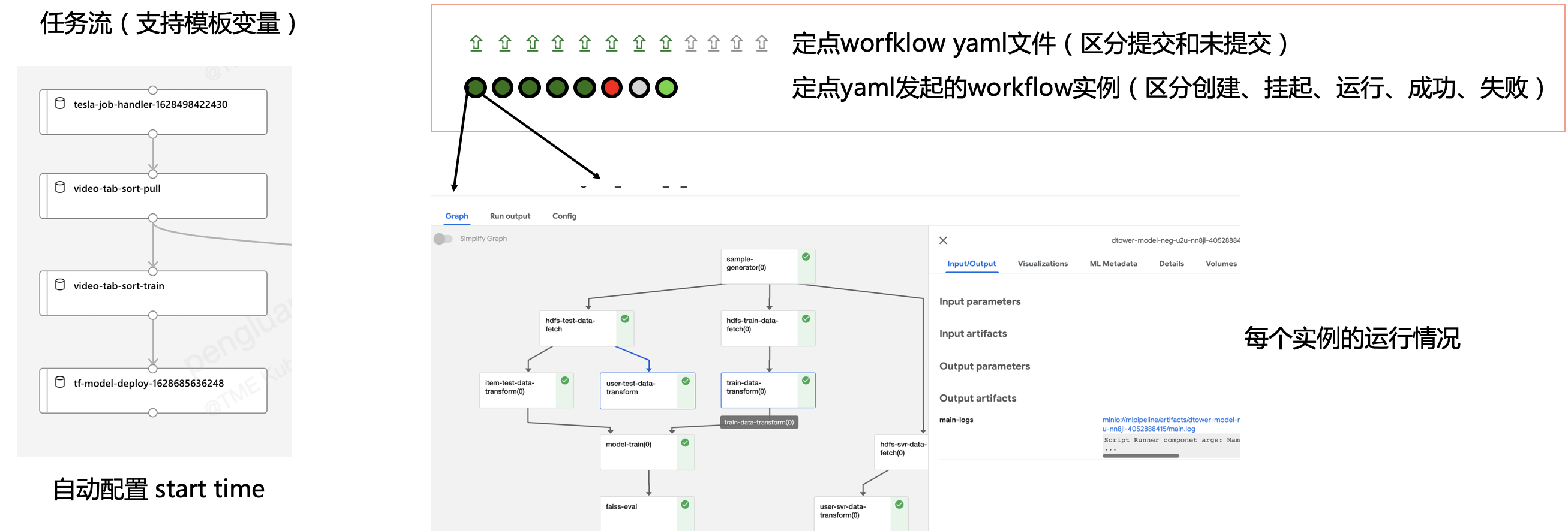
并且对同一个pipeline,区分对待手动运行和定时调度两种实例。
注意:
- 定时调度由celery定时任务make_timerun_config进行控制
- pipeline扩展参数中cronjob_start_time用来控制 历史任务的补录时间起点。(修改pipeline调度类型和crontab会重置cronjob_start_time为当前时间)
- pipeline参数中需要使用execution_date才能在补录时保留实例时间点状态
- pipeline的depends_on_past参数控制新的实例运行是否要关注上一次实例是否完成
- pipeline的expired_limit参数控制过往未调度实例只保留多少个最新实例运行,更久远实例过期。
- pipeline的max_active_runs参数控制最多同时并行多少个调度实例运行
- 最大并发周期为全局变量PIPELINE_TASK_CRON_RESOLUTION=10分钟一次
查看路径:训练-定时调度记录
字段说明:执行时间为这个pipeline本次调度该发起的时间点
状态:comed,为调度配置已经产生。created为调度已经发起。
操作说明
1、平台会根据pipeline的配置决定是否发起调度。
2、状态链接中可以看到本地调度发起的workflow的运行情况
3、日志链接中可以看到本地调度发起的日志
平台自带的任务模板并不一定能完全满足所有需求,除了用户可以使用自定义镜像,自定义命令的方式外。平台将插件的注册功能开放给用户。
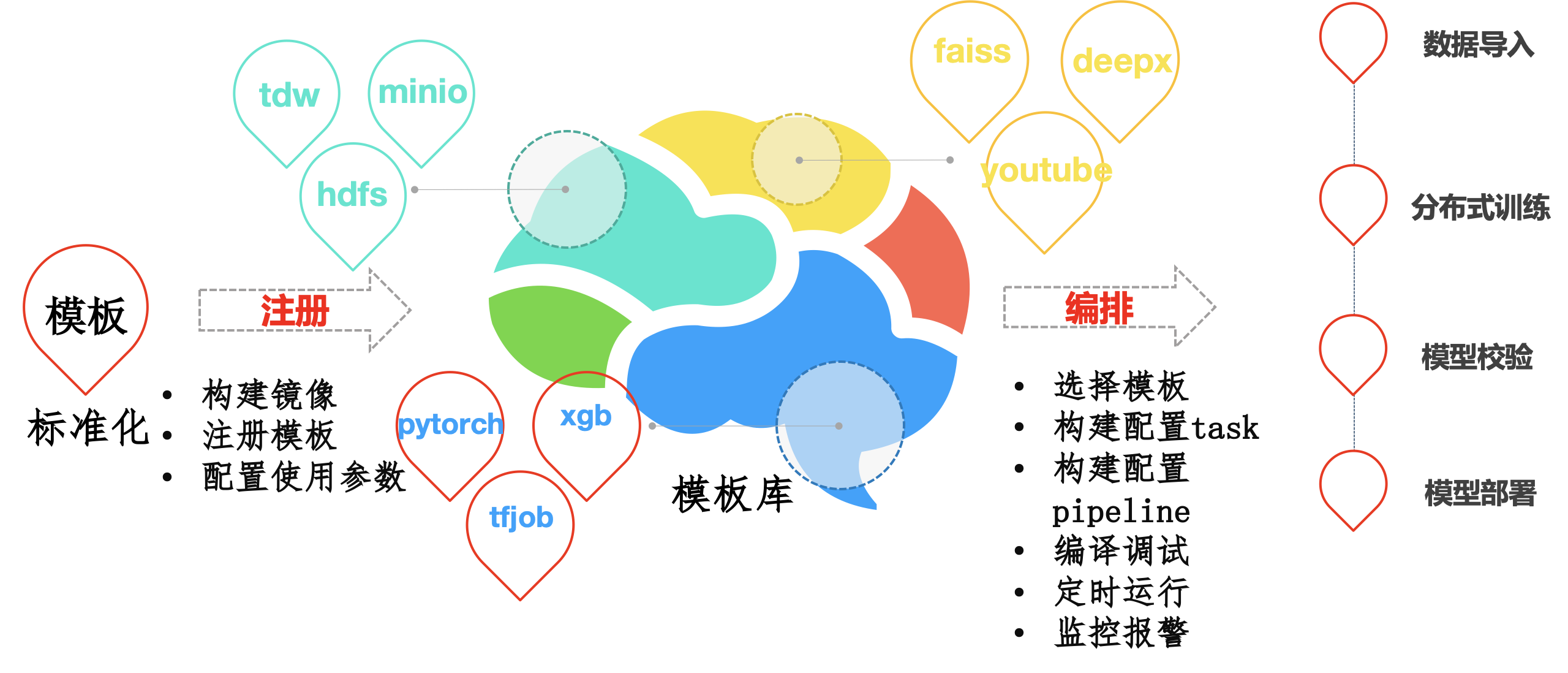
这样用户就可以自己定义模板,然后开放给全平台的用户使用。用户只需要自己构建好功能镜像,然后将其他用户使用此镜像需要填写的参数注册进来了就可以了。其中也包含的模板特定功能,例如固定的挂载,固定的环境变量,k8s账号等。
