Documentation · Examples · Discord

vectara-agentic is a Python library for developing powerful AI assistants and agents using Vectara and Agentic-RAG. It leverages the LlamaIndex Agent framework and provides helper functions to quickly create tools that connect to Vectara corpora.
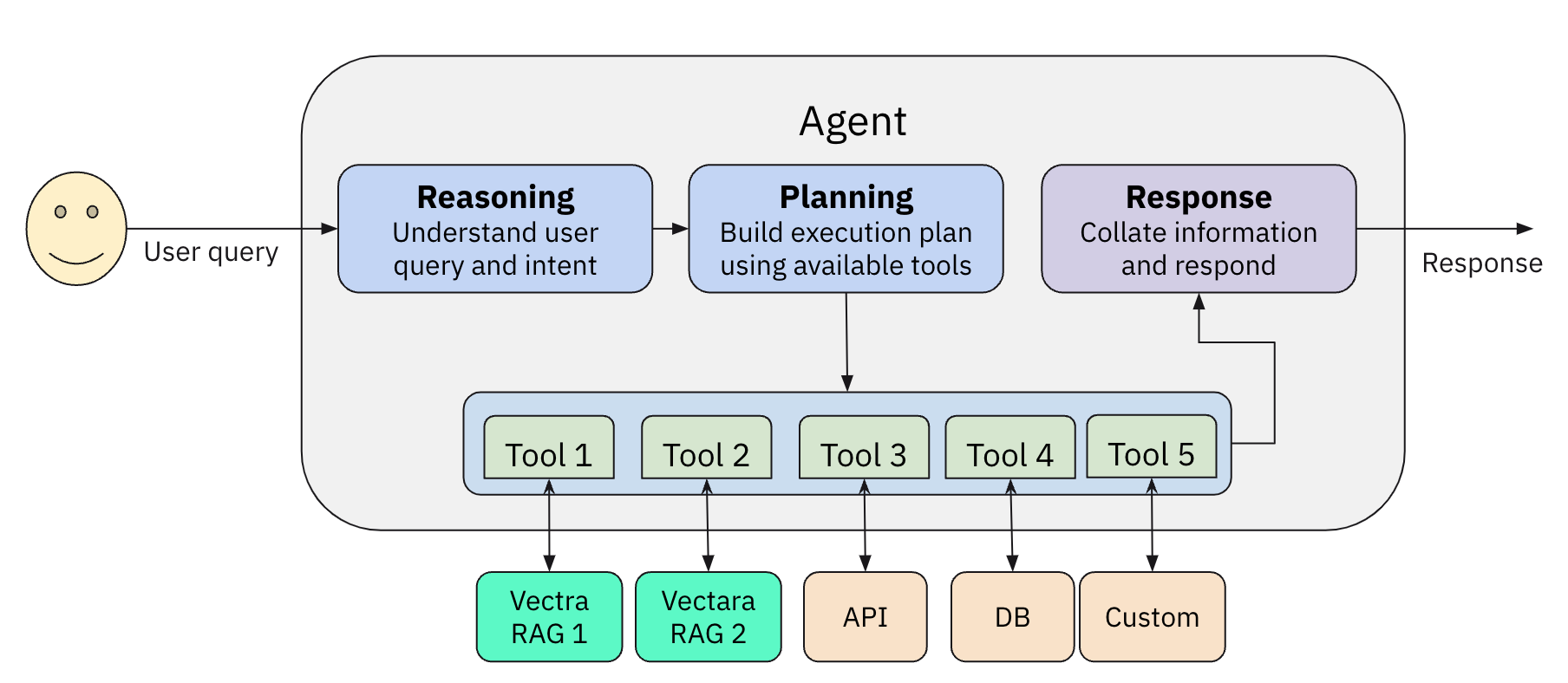
- Enables easy creation of custom AI assistants and agents.
- Create a Vectara RAG tool or search tool with a single line of code.
- Supports
ReAct,OpenAIAgent,LATSandLLMCompileragent types. - Includes pre-built tools for various domains (e.g., finance, legal).
- Integrates with various LLM inference services like OpenAI, Anthropic, Gemini, GROQ, Together.AI, Cohere, Bedrock and Fireworks
- Built-in support for observability with Arize Phoenix
Check out our example AI assistants:
- Vectara account
- A Vectara corpus with an API key
- Python 3.10 or higher
- OpenAI API key (or API keys for Anthropic, TOGETHER.AI, Fireworks AI, Bedrock, Cohere, GEMINI or GROQ, if you choose to use them)
pip install vectara-agenticimport os
from vectara_agentic.tools import VectaraToolFactory
vec_factory = VectaraToolFactory(
vectara_api_key=os.environ['VECTARA_API_KEY'],
vectara_customer_id=os.environ['VECTARA_CUSTOMER_ID'],
vectara_corpus_id=os.environ['VECTARA_CORPUS_ID']
)A RAG tool calls the full Vectara RAG pipeline to provide summarized responses to queries grounded in data.
from pydantic import BaseModel, Field
years = list(range(2020, 2024))
tickers = {
"AAPL": "Apple Computer",
"GOOG": "Google",
"AMZN": "Amazon",
"SNOW": "Snowflake",
}
class QueryFinancialReportsArgs(BaseModel):
query: str = Field(..., description="The user query.")
year: int | str = Field(..., description=f"The year this query relates to. An integer between {min(years)} and {max(years)} or a string specifying a condition on the year (example: '>2020').")
ticker: str = Field(..., description=f"The company ticker. Must be a valid ticket symbol from the list {tickers.keys()}.")
query_financial_reports_tool = vec_factory.create_rag_tool(
tool_name="query_financial_reports",
tool_description="Query financial reports for a company and year",
tool_args_schema=QueryFinancialReportsArgs,
lambda_val=0.005,
summary_num_results=7,
# Additional arguments
)See the docs for additional arguments to customize your Vectara RAG tool.
In addition to RAG tools, you can generate a lot of other types of tools the agent can use. These could be mathematical tools, tools that call other APIs to get more information, or any other type of tool.
See Agent Tools for more information.
from vectara_agentic import Agent
agent = Agent(
tools=[query_financial_reports_tool],
topic="10-K financial reports",
custom_instructions="""
- You are a helpful financial assistant in conversation with a user. Use your financial expertise when crafting a query to the tool, to ensure you get the most accurate information.
- You can answer questions, provide insights, or summarize any information from financial reports.
- A user may refer to a company's ticker instead of its full name - consider those the same when a user is asking about a company.
- When calculating a financial metric, make sure you have all the information from tools to complete the calculation.
- In many cases you may need to query tools on each sub-metric separately before computing the final metric.
- When using a tool to obtain financial data, consider the fact that information for a certain year may be reported in the following year's report.
- Report financial data in a consistent manner. For example if you report revenue in thousands, always report revenue in thousands.
"""
)See the docs for additional arguments, including agent_progress_callback and query_logging_callback.
res = agent.chat("What was the revenue for Apple in 2021?")
print(res.response)Note that:
vectara-agenticalso supportsachat()and two streaming variantsstream_chat()andastream_chat().- The response types from
chat()andachat()are of typeAgentResponse. If you just need the actual string response it's available as theresponsevariable, or just usestr(). For advanced use-cases you can look at otherAgentResponsevariables such assources.
vectara-agentic provides two helper functions to connect with Vectara RAG
create_rag_tool()to create an agent tool that connects with a Vectara corpus for querying.create_search_tool()to create a tool to search a Vectara corpus and return a list of matching documents.
See the documentation for the full list of arguments for create_rag_tool() and create_search_tool(),
to understand how to configure Vectara query performed by those tools.
A Vectara RAG tool is often the main workhorse for any Agentic RAG application, and enables the agent to query one or more Vectara RAG corpora.
The tool generated always includes the query argument, followed by 1 or more optional arguments used for
metadata filtering, defined by tool_args_schema.
For example, in the quickstart example the schema is:
class QueryFinancialReportsArgs(BaseModel):
query: str = Field(..., description="The user query.")
year: int | str = Field(..., description=f"The year this query relates to. An integer between {min(years)} and {max(years)} or a string specifying a condition on the year (example: '>2020').")
ticker: str = Field(..., description=f"The company ticker. Must be a valid ticket symbol from the list {tickers.keys()}.")
The query is required and is always the query string.
The other arguments are optional and will be interpreted as Vectara metadata filters.
For example, in the example above, the agent may call the query_financial_reports_tool tool with
query='what is the revenue?', year=2022 and ticker='AAPL'. Subsequently the RAG tool will issue
a Vectara RAG query with the same query, but with metadata filtering (doc.year=2022 and doc.ticker='AAPL').
There are also additional cool features supported here:
- An argument can be a condition, for example year='>2022' translates to the correct metadata filtering condition doc.year>2022
- if
fixed_filteris defined in the RAG tool, it provides a constant metadata filtering that is always applied. For example, if fixed_filter=doc.filing_type='10K'then a query with query='what is the reveue', year=2022 and ticker='AAPL' would translate into query='what is the revenue' with metadata filtering condition of "doc.year=2022 AND doc.ticker='AAPL' and doc.filing_type='10K'"
Note that tool_args_type is an optional dictionary that indicates the level at which metadata filtering
is applied for each argument (doc or part)
The Vectara search tool allows the agent to list documents that match a query. This can be helpful to the agent to answer queries like "how many documents discuss the iPhone?" or other similar queries that require a response in terms of a list of matching documents.
vectara-agentic provides a few tools out of the box (see ToolsCatalog for details):
- Standard tools:
summarize_text: a tool to summarize a long text into a shorter summary (uses LLM)rephrase_text: a tool to rephrase a given text, given a set of rephrase instructions (uses LLM) These tools use an LLM and so would use theToolsLLM specified in yourAgentConfig. To instantiate them:
from vectara_agentic.tools_catalog import ToolsCatalog
summarize_text = ToolsCatalog(agent_config).summarize_textThis ensures the summarize_text tool is configured with the proper LLM provider and model as specified in the Agent configuration.
- Legal tools: a set of tools for the legal vertical, such as:
summarize_legal_text: summarize legal text with a certain point of viewcritique_as_judge: critique a legal text as a judge, providing their perspective
- Financial tools: based on tools from Yahoo! Finance:
- tools to understand the financials of a public company like:
balance_sheet,income_statement,cash_flow stock_news: provides news about a companystock_analyst_recommendations: provides stock analyst recommendations for a company.
- Database tools: providing tools to inspect and query a database
list_tables: list all tables in the databasedescribe_tables: describe the schema of tables in the databaseload_data: returns data based on a SQL queryload_sample_data: returns the first 25 rows of a tableload_unique_values: returns the top unique values for a given column
In addition, we include various other tools from LlamaIndex ToolSpecs:
- Tavily search and EXA.AI
- arxiv
- neo4j & Kuzu for Graph DB integration
- Google tools (including gmail, calendar, and search)
- Slack
Note that some of these tools may require API keys as environment variables
You can create your own tool directly from a Python function using the create_tool() method of the ToolsFactory class:
def mult_func(x, y):
return x * y
mult_tool = ToolsFactory().create_tool(mult_func)The main way to control the behavior of vectara-agentic is by passing an AgentConfig object to your Agent when creating it.
For example:
agent_config = AgentConfig(
agent_type = AgentType.REACT,
main_llm_provider = ModelProvider.ANTHROPIC,
main_llm_model_name = 'claude-3-5-sonnet-20241022',
tool_llm_provider = ModelProvider.TOGETHER,
tool_llm_model_name = 'meta-llama/Llama-3.3-70B-Instruct-Turbo'
)
agent = Agent(
tools=[query_financial_reports_tool],
topic="10-K financial reports",
custom_instructions="You are a helpful financial assistant in conversation with a user.",
agent_config=agent_config
)The AgentConfig object may include the following items:
agent_type: the agent type. Valid values areREACT,LLMCOMPILER,LATSorOPENAI(default:OPENAI).main_llm_providerandtool_llm_provider: the LLM provider for main agent and for the tools. Valid values areOPENAI,ANTHROPIC,TOGETHER,GROQ,COHERE,BEDROCK,GEMINIorFIREWORKS(default:OPENAI).main_llm_model_nameandtool_llm_model_name: agent model name for agent and tools (default depends on provider).observer: the observer type; should beARIZE_PHOENIXor if undefined no observation framework will be used.endpoint_api_key: a secret key if using the API endpoint option (defaults todev-api-key)
If any of these are not provided, AgentConfig first tries to read the values from the OS environment.
When creating a VectaraToolFactory, you can pass in a vectara_api_key, vectara_customer_id, and vectara_corpus_id to the factory.
If not passed in, it will be taken from the environment variables (VECTARA_API_KEY, VECTARA_CUSTOMER_ID and VECTARA_CORPUS_ID). Note that VECTARA_CORPUS_ID can be a single ID or a comma-separated list of IDs (if you want to query multiple corpora).
These values will be used as credentials when creating Vectara tools - in create_rag_tool() and create_search_tool().
The custom instructions you provide to the agent guide its behavior. Here are some guidelines when creating your instructions:
- Write precise and clear instructions, without overcomplicating.
- Consider edge cases and unusual or atypical scenarios.
- Be cautious to not over-specify behavior based on your primary use-case, as it may limit the agent's ability to behave properly in others.
The Agent class defines a few helpful methods to help you understand the internals of your application.
- The
report()method prints out the agent object’s type, the tools, and the LLMs used for the main agent and tool calling. - The
token_counts()method tells you how many tokens you have used in the current session for both the main agent and tool calling LLMs. This can be helpful if you want to track spend by token.
The Agent class supports serialization. Use the dumps() to serialize and loads() to read back from a serialized stream.
vectara-agentic supports observability via the existing integration of LlamaIndex and Arize Phoenix.
First, set VECTARA_AGENTIC_OBSERVER_TYPE to ARIZE_PHOENIX in AgentConfig (or env variable).
Then you can use Arize Phoenix in three ways:
- Locally.
- If you have a local phoenix server that you've run using e.g.
python -m phoenix.server.main serve, vectara-agentic will send all traces to it. - If not, vectara-agentic will run a local instance during the agent's lifecycle, and will close it when finished.
- In both cases, traces will be sent to the local instance, and you can see the dashboard at
http://localhost:6006
- If you have a local phoenix server that you've run using e.g.
- Hosted Instance. In this case the traces are sent to the Phoenix instances hosted on Arize.
- Go to
https://app.phoenix.arize.com, setup an account if you don't have one. - create an API key and put it in the
PHOENIX_API_KEYenvironment variable - this indicates you want to use the hosted version. - To view the traces go to
https://app.phoenix.arize.com.
- Go to
Now when you run your agent, all call traces are sent to Phoenix and recorded.
In addition, vectara-agentic also records FCS (factual consistency score, aka HHEM) values into Arize for every Vectara RAG call. You can see those results in the Feedback column of the arize UI.
vectara-agentic can be easily hosted locally or on a remote machine behind an API endpoint, by following theses steps:
Ensure that you have your API key set up as an environment variable:
export VECTARA_AGENTIC_API_KEY=<YOUR-ENDPOINT-API-KEY>
if you don't specify an Endpoint API key it uses the default "dev-api-key".
Initialize the agent and start the FastAPI server by following this example:
from vectara_agentic.agent import Agent
from vectara_agentic.agent_endpoint import start_app
agent = Agent(...) # Initialize your agent with appropriate parameters
start_app(agent)
You can customize the host and port by passing them as arguments to start_app():
- Default: host="0.0.0.0" and port=8000. For example:
start_app(agent, host="0.0.0.0", port=8000)
Once the server is running, you can interact with it using curl or any HTTP client. For example:
curl -G "http://<remote-server-ip>:8000/chat" \
--data-urlencode "message=What is Vectara?" \
-H "X-API-Key: <YOUR-ENDPOINT-API-KEY>"
We welcome contributions! Please see our contributing guide for more information.
This project is licensed under the Apache 2.0 License. See the LICENSE file for details.
- Website: vectara.com
- Twitter: @vectara
- GitHub: @vectara
- LinkedIn: @vectara
- Discord: Join our community